
Four reasons ‘You Build It You Run It’ is crucial for highly regulated financial businesses
While ‘financial businesses’ can be quite broad—spanning insurance and superannuation companies, banks, fintech, investment firms, and more—there is one thing they all have in common. And it makes ‘You Build It You Run It’ an incredibly compelling proposition.
Whatever your focus as an Australian financial business, you’re regulated by APRA: the Australian Prudential Regulatory Authority.
As a result, you have mandatory commitments to uphold around transparency and accountability.
In the years following The Royal Commission into Misconduct in the Banking, Superannuation and Financial Services Industry, these commitments are being monitored with more intent than ever before.
The You Build It You Run It operating model makes it incredibly easy for financial businesses to meet those regulatory commitments.
How? By aligning perfectly with APRA’s remit, as defined in their very own statement of intent.
You Build It You Run It perfectly aligns with The Australian Prudential Regulatory Authority’s concerns and interests, making it easier and more cost-effective to meet your regulatory commitments.
At the same time, You Build It You Run It delivers a huge range of additional benefits for your organisation. This is achieved by ensuring your digital services are:
- Highly available for customers
- Capitalising on as much potential revenue as possible, and
- Preventing inefficiencies or wasted cost within the business.
1. You Build It You Run It aligns perfectly with APRA’s focus and remit.
What is APRA’s remit?
Enforcing standards to ensure a ‘stable, efficient, and competitive financial system’.
This language is taken directly from APRA’s public statement of intent.
The You Build It You Run It operating model perfectly complements each individual element of that remit. In the right context, it will make your organisation:
- More stable.
- More efficient.
- As competitive as possible.
Before we touch on how, let’s take a moment to acknowledge the importance of auditing.
Many of APRA’s prudential standards require an Auditor to fulfil a range of responsibilities.
You Build It You Run It involves high levels of automation throughout deployment. This is crucial to achieve the high levels of availability and deployment throughput that define it as an operating model.
By virtue of these deployment processes being automated, your deployment pipeline is continuously logging information.
In the You Build It You Run It operating model, you have real-time access to information on demand. This includes things like:
- The number of successful deployments being made
- When deployments are made
- Who instigates each deployment
- Who approves each deployment
- And more.
In stark contrast, the traditional Ops Run It model requires manual creation of audit records. This larger level of manual effort takes time, development resources, and ultimately creates an inconvenient distraction from your main focus: delivering value to both customers and internal stakeholders.
With You Build It You Run It, many elements of your deployment pipeline are automated, logged, and trackable for any necessary audit functions.
By automatically tracking and logging this type of information, it’s much easier to align with APRA’s goals in auditing organisations: ‘to ensure a stable, efficient, and competitive financial system.’
Let’s see how that plays out in reality.
2. You Build It You Run It makes your digital services more stable.
In the context of digital services, APRA’s interest in stability is really about service availability.
The key question is this: can a bank or payments provider serve their customers at all times? Or, conversely, what contingency measures are in place if the provider becomes unavailable? What happens when no one can withdraw their money? This scenario can be catastrophic.
Banks need to be sure their technology is stable. And secure.
So, what is it about You Build It You Run It that contributes to service stability and high availability for customers?
- Teams are naturally incentivised to build proactive availability measures into services from the start, because the teams building the software are accountable for any incidents in production.
- Teams are encouraged to build and architect services that degrade gracefully in the event of an incident. This approach ensures business critical aspects of services are still available to serve customers in the event of a failure.
- Teams are proven to improve time-to-restore after incidents, because they themselves built the code, and can identify and implement fixes faster.
- Teams automate their telemetry and change processes, which reduces the amount of risk associated with deployments. In turn, this contributes to higher levels of service availability.
3. You Build It You Run It makes you more competitive as an organisation.
It’s proven: continuous change and innovation at scale is the best way to increase return on investment for digital organisations.
Launching new features to market rapidly and consistently is the best way to deliver and generate value. In a recent study published by Forrester and Equal Experts, one organisation was able to realise $41,000,000 worth of net present value by improving time-to-market.
The more you’re able to deliver new services or product features, the easier it is to differentiate yourself from competitors.
From APRA’s perspective, it’s suboptimal for every financial organisation to provide the same offering. This creates a scenario where there’s no real choice in the market.
From your perspective, you want to offer new products and services to capitalise on evolving customer needs, driving greater revenue and profit.
How exactly does You Build It You Run It make organisations more competitive?
It exponentially increases teams’ development throughput for a whole number of reasons:
- Unnecessary complexity is removed from the deployment process.
- Teams can streamline and automate testing and approvals processes.
- You Build It You Run It eliminates the need for time-intensive handoff processes and approvals gates.
Perhaps hard evidence is the most compelling rationale here. Using the You Build It You Run It operating model, we’ve supported clients to go from 10 deployments per year to 4,000 per year, without a correlating rise in production incidents.
4. You Build It You Run It makes you more efficient.
Teams need to run in the most efficient way possible. Obviously, profitability is closely linked to your ability to minimise wastage within the business.
From APRA’s perspective, regulating for efficiency ensures your operating model is likely more sustainable. In turn, this prevents banks and financial businesses from falling over, or scenarios like bank runs.
Efficient organisations are also less likely to inflate prices for customers in an attempt to recoup the costs associated with inefficiency or wasted resources.
You Build It You Run It improves your efficiency in a huge range of ways.
- As outlined in the point above, teams are empowered to deliver more value, faster, and more consistently.
- Changes become significantly faster to implement because one single team owns the entire deployment lifecycle. There’s no requirement for time-intensive handoffs or CAB meetings.
- You Build It You Run It fosters a learning culture; teams own all the information required to build and operate a specific digital service. Being less reliant on knowledge or contributions from other teams, they can move faster and make decisions quickly.
- You Build It You Run It is typically extremely cost efficient over time in terms of run costs. Learn more about how much it costs to implement the You Build It You Run It operating model.
So there you have it: four reasons You Build It You Run It is a crucial consideration for highly regulated financial businesses.
If you’re interested in becoming more stable, more competitive, and more efficient in the way you operate, let’s set up a conversation to discuss your requirements.
Alternatively, keep an eye out for more insights into how your operating model can mitigate risk while delivering huge net-present value.
Do you find your teams are continually reworking features? If you’re stuck in an endless cycle of rebuilding and re-releasing features, it’s difficult to deliver valuable new innovations for your customers.
In a recent study conducted by Forrester, an organisation was able to reduce their cost-to-deliver by saving over 3,000 hours of engineering time.
If you’ve read the other articles in this series, you’ll note this is in addition to the $41 million worth of net-present value the organisation was able to realise by improving time-to-market and reducing their ‘concept to cash’ timeline.
How did the organisation realise these incredible results?
By moving to the You Build It You Run It operating model and implementing paved roads.
If you currently support digital services in the traditional Ops Run It model—where teams are segmented by responsibility into ‘Delivery’ and ‘Operations’—you could be denying yourself huge value by engaging in unnecessary rework.
Throughout this article series, I’ve looked at how and why this could be the case:
- Part 1: Ops Run It prioritises stability in a way that fundamentally stops you from delivering at speed (which you can read here).
- Part 2: Ops Run It involves an unnecessarily laborious and manually intensive deployment pipeline (which you can read here).
- Part 3: Ops Run It limits the agility of the development team, making it harder to respond to rapid changes in market conditions or evolving customer needs (which you can read here).
- Part 4: Ops Run It involves an overly strict change management process (which you can read here).
- Part 5: Ops Run It involves a higher rate of rework, which can compromise new feature development (this article).
Ops Run It involves a higher rate of rework, which can compromise new feature development.
Let’s go straight to the data on this one. The following graph is taken from a client I helped to adopt the You Build It You Run It operating model.
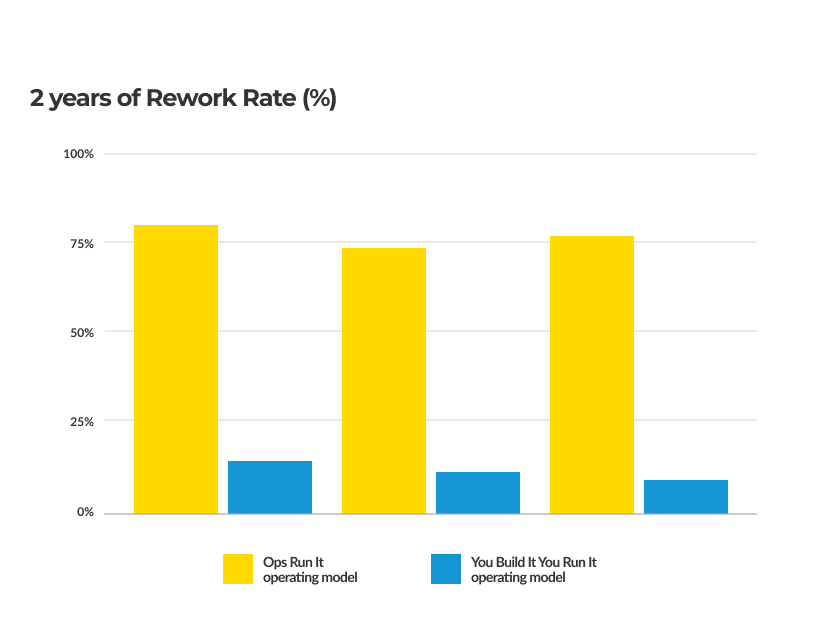
The yellow bars in this graphic represent the rate of rework completed by a product team working in the Ops Run It model over a two-year period.
The blue bars represent the rate of rework completed by the same team while working in the You Build It You Run It operating model.
The difference is significant. And the implication is damning: if your development teams are spending time reworking features, they’re not able to deliver valuable differentiators for your customers.
What are the reasons for this higher rate of rework?
In my experience, there are two main reasons.
1. Ops Run It enforces a distance between the Delivery team and your end customers.
In the Ops Run It model, the Delivery team (the developers who actually build new features) hand off everything they build to an Operations team. As a result, they have no visibility of how the features they build are used by customers.
They also have very limited insight into the general behaviours or needs of their customers in the first place.
When you don’t know your customers, it’s hard to know what they need. And that’s when rebuilding and wasted resource is likely to occur.
With limited visibility of the customer, there’s a higher likelihood that the Delivery team will build features that do not align with the actual needs of customers.
These features won’t be used by customers, creating a scenario where the team needs to rebuild things in a way that aligns with what customers actually want.
2. When Delivery teams are solely responsible for deployment throughput—and not availability—they are more inclined to permit technical debt in what they ship.
Nothing against Delivery teams here. In my experience, this is just human nature.
In Ops Run It, Delivery teams aren’t called out at 3am to rectify any incident in production. This is because incidents that interrupt service availability fall within the remit of the Operations team.
The Delivery team is judged on their ability to hit delivery milestones. Not availability milestones.
So, they are sometimes perversely incentivised to cut corners in order to hit those milestones. Sometimes, to the detriment of the availability of what they’re building.
This technical debt needs to be repaid if there are issues in production. And the payback of technical debt becomes an interruption to BAU development. This is because these issues need to be fixed as they present, rather than through proactive planning or work sequencing.
With these constant interruptions to BAU feature development—and the rework associated with fixing technical debt—it can be difficult to dedicate time to delivering new, innovative features for your customers.
You Build It You Run It puts teams closer to their customers. And eliminates the lure of technical debt.
In You Build It You Run It, teams are much closer to their customers.
They have clear and constant visibility of how customers use what they build, because the team who builds the software then runs the software in production. This means they have a far better understanding of what to build to align with customer needs.
Additionally, because the one team owns every aspect of the development lifecycle, they can react quickly to customer needs. They’re also better placed to react quickly to evolving customer needs and prioritise delivery of the feature that unlocks the most value in any given moment.
Teams in You Build It You Run It are also much less inclined to leave technical debt in the software they build.
This is because they themselves are required to implement any fixes in the event of a failure in production. This includes out of hours support.
As a result, these teams are actively incentivised to build proactive contingencies into their software that safeguard service availability.
This includes measures like graceful degradation, where services cascade on failure to prioritise mission-critical functionality in the event of an issue.
When teams are less distracted or preoccupied with reworking problematic existing features, they’re able to deliver new and exciting features for customers. This consistent innovation at pace—and scale—is proven to be key in
- delivering significant return on investment
- differentiating your service offering from your competitors
- unlocking the substantial value that may be dormant in your teams.
When that value could add up to the tune of USD$41,000,000, it’s worth investigating every avenue to unlock the potential in your business.
If you’re stuck in a perpetual cycle of rework and constantly struggling to deliver anything new—despite your Delivery teams being tied up—You Build It You Run It could be the answer.
That completes my five-part series on Ops Run It and the impact it can have on your time-to-market.
To recap and close things off, let’s run through the five ways Ops Run It can impede your ability to deliver new features for customers, both rapidly and consistently.
- Ops Run It prioritises stability in a way that fundamentally stops you from delivering at speed.
- Ops Run It often involves an unnecessarily laborious and manually intensive deployment pipeline.
- Ops Run It limits the agility of the development team, making it harder to respond to changes in market conditions or evolving customer needs.
- Ops Run It involves an overly strict change management process, which causes delays for releases and costs you in unrealised value.
- Ops Run It involves a higher rate of rework, which can compromise new feature development (this piece).
If you feel like you’re struggling with any—or all—of these issues, I’d love to help you pinpoint the problem and get more value out of your team.
Get in touch today and start capitalising on untapped potential in your business.
Slow moving approvals. A change-management process that takes so long the change is no longer relevant when it’s delivered. Sound familiar?
This wreaks havoc on your ability to innovate at pace. And as a result, denies you from capitalising on the huge potential that exists within your organisation.
And there can be huge potential.
In a recent study conducted by Forrester, an organisation realised over $41 million of net-present value by improving time-to-market and reducing their ‘concept to cash’ timeline.
They achieved this result by moving to the You Build It You Run It operating model and implementing paved roads.
If you’re currently working in a traditional Ops Run It model—where teams are segmented by responsibility into ‘Delivery’ and ‘Operations’—you could be sitting on comparable mountains of untapped profit.
In this article series, I’ve been highlighting how and why that’s the case:
-
- Part 1: Ops Run It prioritises stability in a way that fundamentally stops you from delivering at speed (which you can read here).
- Part 2: Ops Run It involves an unnecessarily laborious and manually intensive deployment pipeline (which you can read here).
- Part 3: Ops Run It limits the agility of the development team, making it harder to respond to rapid changes in market conditions or evolving customer needs (which you can read here).
- Part 4: Ops Run It involves an overly strict change management process (this article).
Part 5: Ops Run It and potential impacts on resourcing for sustained innovation.
Ops Run It involves an overly strict change management process, which causes delays for releases and costs you in unrealised value.
In Ops Run It, you have your Delivery team. They build the software.
Once a new feature is built, they hand off to a second team—effectively a change management function for the business—before that team assesses the feature for approval to production.
Once approved, often the feature is pushed to a third team, which is your Application Support team. They’re responsible for releasing things into the production environment. In some organisations, this same feature can then be pushed to a fourth team, which is responsible for the incident management and running of the service.
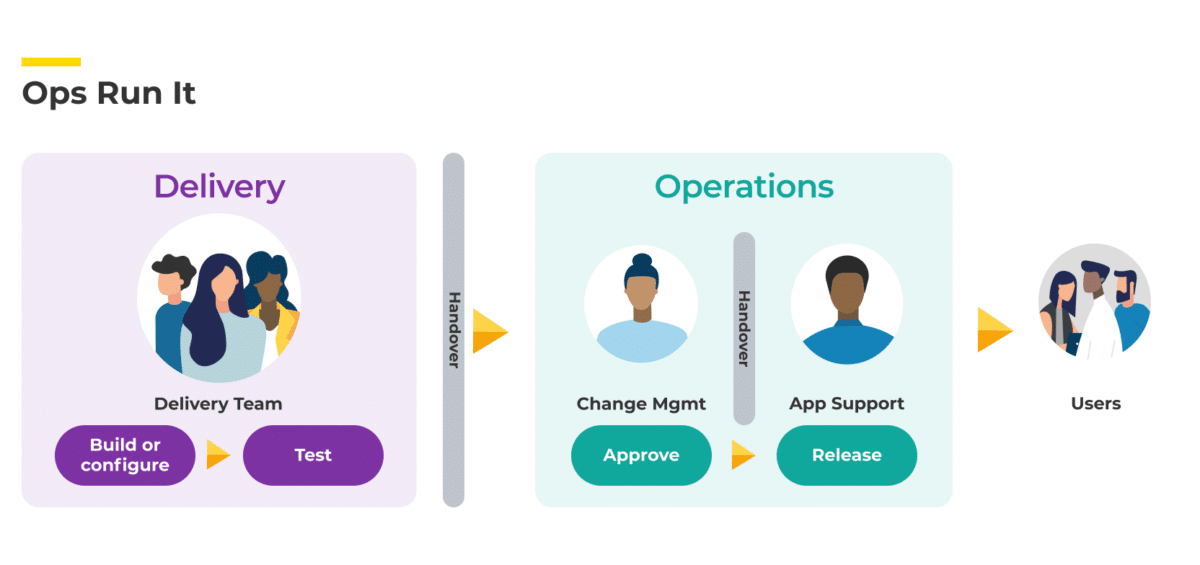
In an Ops Run It operating model, any new feature will move linearly through the teams outlined in the above diagram, from left to right.
If we look at the inherent motivations of these teams, we can assume that:
- The Delivery team is incentivised to deliver: they want to build as many features as possible.
- The change management function within Operations is incentivised to safeguard against problematic deployments: they want to minimise any downtime caused by deployment to production.
- The Operations team is incentivised to maintain a high level of availability.
We can see that two of the teams are primarily motivated by the availability of the system, not by the delivery of new, valuable features.
Both the change management team and the Operations team will likely:
- Have a natural aversion to updating the system.
- Have availability targets to meet.
They’re not judged on how many valuable or innovative features are delivered, which is problematic for both you and your customers.
To protect against compromising their availability KPIs, the teams will implement time-consuming change management processes.
One example is the Change Acceptance Board, or CAB.
Teams will typically attend these meetings to run through a perfunctory checklist, spending time to tick off a checklist of testing requirements.
Change Advisory Boards are not the problem. But they’re certainly not the solution either.
CAB meetings are often implemented as a strategy to mitigate risk. In certain regulatory environments, there’s also a common requirement for ‘separation of duties’. Or, the need for more than one development team to assess code before it’s pushed to production.
Organisations will immediately implement CAB meetings in response to this requirement because there’s a clear delineation between Delivery and Operations.
But as we’ve established, the handoffs required between distinct segmented teams are slow and time consuming. And these bureaucratic gates prevent you from innovating rapidly at scale.
With You Build It You Run It, there’s a better way.
You can still maintain separation of duties in You Build It You Run It.
In You Build It You Run It, there are no handoffs between teams. Because the team that builds the software is responsible for the operation and support of that software.
This eliminates the need for handoff and approvals processes like CABs. But the question remains: how do we accommodate for separation of duties with a single team?
There are three main techniques. You can implement all of them in conjunction.
- You can carry out Extreme Programming (XP) practices like pair programming and continuous integration. These practices involve more than one person, which means code is being assessed by multiple developers throughout the development pipeline.
- You write automation tests. These automation tests should be written as the team’s first port of call and vetted and validated by external stakeholders. From that point on, all subsequent code is written to match the requirements of the automation tests. This provides objective, third-party validated proof that the code is highly available prior to deployment.
- You engage a Platform team to build a paved road for you.
A paved road is officially defined as “a low friction, hardened interface that comprises user journeys, where the user is the product delivery team.” Let’s break that definition down.
Low friction = easy to use.
Hardened = proven and reliable.
Interface = communication between the developers’ code and the infrastructure that supports it.
User journeys = the developers’ or organisational processes required to build, deploy, run, and operate a service.
Examples of paved roads can include automated deployment processes and service alerts.
What’s the purpose of a paved road? How does it relate to separation of duties?
Paved roads are designed to abstract complexity away from common daily operations and eliminate unnecessary cognitive overload. They allow the product delivery team to focus on delivering value.
A Platform Team will manage all paved roads for the organisation, which multiple teams can draw from.
In the context of separation of duties, when you have a paved road that automates deployment, it’s the Platform Team who builds the capability to deploy, not the product delivery team themselves.
This ensures a clear separation of duty. The Platform Team will have implemented all necessary checks and balances—and encompassed the learned best-practices specific to your organisation—in building out the deployment process.
When you’ve validated all your paved roads, which will be replicated exactly through automation whenever they’re required, there’s no need for time-consuming change management or approvals functions like CAB meetings.
Your team is freed up with additional time to focus on:
- Understanding the features your customers want and need.
- Building and deploying those features.
- Learning how customers use what they’ve built.
- Repeating the process rapidly to deliver far more value in a much shorter time window.
Are you delivering valuable change? Or are you caught up in ineffective change-management cycles?
If you’re hampered by slow moving approvals processes, you could be sitting on mountains of untapped net-present value.
And I can help you unlock it for your organisation. If you’re interested, let’s arrange a conversation.
Alternatively, if you’re keen to learn more about You Build It You Run It, keep an eye out for the next and final piece in this article series.
If technology hampers your ability to respond to customer needs, you’re likely denying yourself enormous potential profit. And You Build It You Run It could be the answer.
Welcome to part three of this five-part series, highlighting how a traditional Ops Run It operating model can deny you of value.
This series is designed to help you unlock serious potential that’s dormant within your business.
How serious?
In a recent study conducted by Forrester, an organisation realised over $41 million of net-present value by improving time-to-market and reducing their ‘concept to cash’ timeline.
They achieved this result by implementing the You Build It You Run It operating model: by delivering new value streams to customers consistently and being able to pivot in response to evolving feedback or requirements.
This organisation realised $41 million worth of existing net-present value by implementing the You Build It You Run It operating model.
Why is the model so effective in improving speed to market? And how does Ops Run It create challenges that prevent you from achieving the same results?
Each part in this series examines and answers those questions in detail.
- Part 1: Ops Run It prioritises stability in a way that fundamentally stops you from delivering at speed (which you can read here).
- Part 2: Ops Run It involves an unnecessarily laborious and manually intensive deployment pipeline (which you can read here).
- Part 3: Ops Run It limits the agility of the development team, making it harder to respond to rapid changes in market conditions or evolving customer needs (this article).
- Part 4: Ops Run It involves an overly strict change management process and stifles change (which you can read here)
- Part 5: Ops Run It and potential impacts on resourcing for sustained innovation.
Ops Run It limits the agility of the development team, making it harder to respond to changes in market conditions or evolving customer needs.
Let’s consider this statement in the context of a change management process.
Imagine you work in the Ops Run It model. You’re delivering a new feature to customers.
The Delivery team—which is siloed and distinct from the Operations team—builds the feature. Because of the segmented nature of the teams, the Delivery team is likely incentivised to focus on volume of production and less concerned about stability.
Stability (or service availability) is a consideration, but likely not as significant as it might be if the Delivery team themselves were responsible for fixing incidents in production.
On completion of the new feature, the Delivery team conducts a lengthy handoff process (or series of handoffs).
And none of your customers actually use the feature.
In this scenario, it’s incredibly difficult to identify why no one is using the feature.
The Operations team will likely think “this feature is perfect; we haven’t had a single incident.” The Delivery team, on the other hand, have no visibility that no one is engaging with what they’ve built.
In an Ops Run It model, there is a significant gap between the Delivery team and the end users. This can contribute to a scenario where the Delivery team has very little understanding of their end-customers’ needs.
With no visibility of the impact of what they’re building, the Delivery team forges on…
The Delivery team is completely unaware that what they’ve built is surplus to requirements, so they have no cause to alter their approach. In this situation, they will continue to deliver more, similar features.
Remember, they are incentivised to build. They are charged with developing new features and they will continue to do so.
This creates:
- A substantial backlog, which takes time to work through and deliver.
- Wasted development resource, because they’re largely building redundant features.
- A surplus of features that don’t align with customer needs. This equates to frustrated customers.
Now, imagine the Operations team successfully identifies that no customers are using the feature.
They also manage to pull data on why no one uses the feature.
This is a perfect opportunity to provide value by responding to customer needs.
But in an Ops Run It model, the response will take time…
The teams will need to:
- Enter the change request into the backlog of work for the delivery team.
- Reshuffle the backlog and ensure the changes in priority are communicated to stakeholders.
- Find a slot and deploy the change to production.
In most cases, there will be a separate team to perform that deployment to production. So, the team will also need to spend time onboarding them and provide context in relation to the update.
Once the update is deployed, the team will then have to handoff to the Ops Team to run the update.
Jumping through all of these procedural hoops takes time. Time in which you’re not satisfying your customers, and time in which you’re losing potential revenue from them.
Consider another example. Imagine you have a development team member monitoring your website; they notice a high amount of traffic in relation to a specific form on the website. Their response? Increase the scalability of the system to cope with a higher volume of traffic.
In reality, the button experiences high amounts of traffic because the design of that particular form is poor–it doesn’t provide any indication that it has received a submission, so people are clicking it rapidly and far more frequently. Without visibility of the customer, the development team can make assumptions and build a solution that doesn’t alleviate the root cause of an issue.
What would happen in the You Build It You Run It model?
In the You Build It You Run It model, the team that builds the software is the team that runs the software.
This means they are much closer to the customer. They monitor how customers engage with what they build and have direct access to customer feedback.
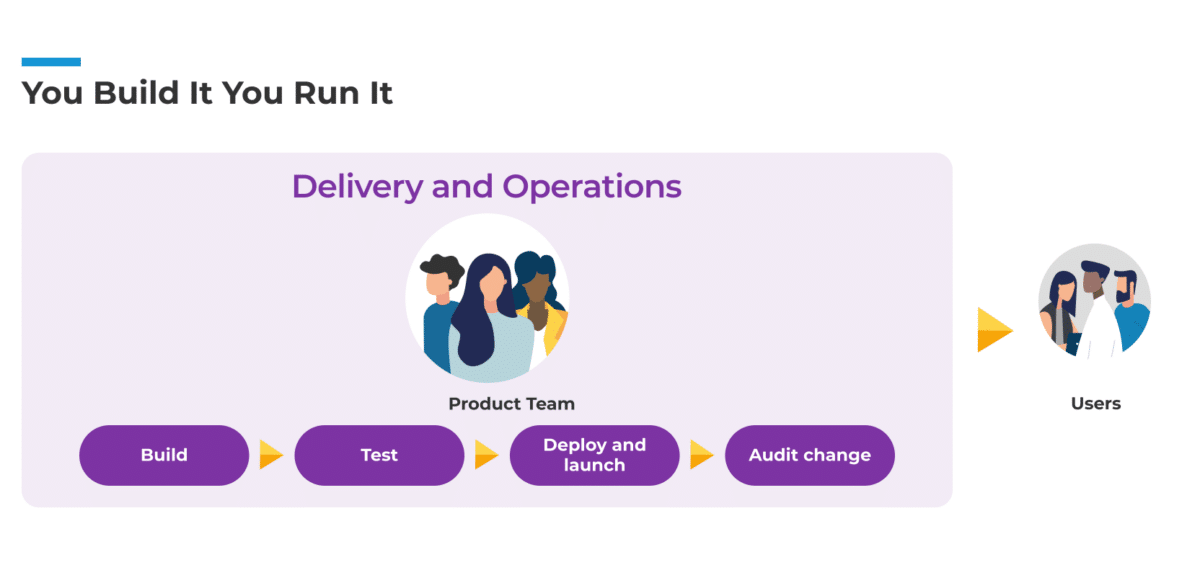
In the You Build It You Run It model, the team who builds the software and monitors the software in production have direct access to—and visibility of—their end users.
If they need to respond to customer requirements, they can make changes in real time. They do not have to navigate a lengthy and time-consuming approvals process, because they own the entire lifecycle of the product or service they maintain.
Generally speaking, You Build It You Run It fosters a strong culture of ownership and accountability. This encourages teams to be more responsive to customer needs and own the impact of what they build.
In my experience, developers are also happier. They derive purpose from knowing they are contributing tangible value for both customers and the business; they have a stronger sense of their value to the organisation and feel more pride in their role.
Are you denying yourself of substantial net-present value?
If you’re currently working in a traditional Ops Run It model—held up by overly rigid approvals and that stifle your team’s ability to respond to customer needs—there’s every chance you’re sitting on a gold mine of potential value.
Adopting the You Build It You Run It model could be the key to unlocking significant profits. If you’d like to have a conversation to assess how likely that’s the case, get in touch today.
Or, keep an eye out for the next article in this series, where I’ll focus on change management processes in each of the models.
Maximising Profits & Efficiency: Why Ops Run It Costs You Revenue By Slowing Time-To-Market – Part 3
Are your traditional processes dragging your business down? It’s time for a change! In part 3 of our 5-video series, we’ll expose how the Ops Run It model is holding you back and why switching to the You Build It You Run It model will help you surge ahead of the competition!
3Reducing time-to-market is proven to help digital organisations unlock enormous value. In the right circumstances, adopting You Build It You Run It—rather than Ops Run It—is the key to helping you deliver more value, faster.
Welcome to part two of this five-part series highlighting how a traditional Ops Run It operating model can deny you of value.
In a recent study conducted by Forrester, an organisation realised over $41 million of net-present value by improving time-to-market and reducing their ‘concept to cash’ timeline.
They achieved this result by adopting You Build It You Run It and moving away from the traditional Ops Run It operating model.
So, what is it about Ops Run It that prevents you from delivering valuable features at pace? Each piece of this series will look at a different aspect in detail.
The other parts of the series include:
- Part 1: Ops Run It prioritises stability in a way that fundamentally stops you from delivering at speed (which you can read here).
- Part 2: Ops Run It involves an unnecessarily laborious and manually intensive deployment pipeline (this article).
- Part 3: Ops Run It limits the agility of the development team, making it harder to respond to rapid changes in market conditions or evolving customer needs.
- Part 4: Ops Run It involves an overly strict change management process.
- Part 5: Ops Run It and potential impacts on resourcing for sustained innovation.
Ops Run It often involves an unnecessarily laborious and manually intensive deployment process.
This is largely caused by the fundamental structure of the teams in an Ops Run It approach.
There are at least two separate, siloed teams in Ops Run It. They are typically:
- The Delivery team: who focus on building software.
- The Operations team: who focus on approvals, change management, monitoring, and support.
- Sometimes, you may have a third team which is the team that does the deployment itself. This could be separate from either the delivery team or operations team.
In this approach, there’s a requirement for multiple handovers between the teams, which contributes to the complexity of the deployment pipeline.
This complexity can come to fruition in many ways.
In this piece, I’ll focus on testing and approvals processes prior to deployment.
Let’s analyse a practical example.
In Ops Run It, you’ll have a distinct subset team within Operations. Their role is solely to determine whether features are stable and ready for deployment.
The objective of this team is to assess and confirm that testing has been completed. This is typically a mandatory approvals gate as part of deployment.
Critically, this change management team is not involved in building software. Nor are they involved in identifying which features should be built.
As a result, change management teams typically resort to relying on a testing checklist to carry out their role.
For every change or deployment, they will ask:
- Has the unit testing been completed?
- Have the acceptance tests been completed?
- Have the performance tests been completed?
- Have you done a penetration test?
- Where is the evidence of these tests?
The better, more valuable question—rather than ‘have you completed X test?’—is ‘have you completed the right tests with the right amount of testing on the right portions of code? Are the right tests in place for the features that are being developed.’
For example, teams will be able to confirm they’ve tested for specific scenarios and alternative scenarios. They will be able to confirm testing in a specific area of the system where changes have occurred and where there are downstream dependencies.
And the only people who will know the answer to that question are the delivery team who’ve built the software.
You Build It You Run It can eliminate these inefficient, bureaucratic approvals processes.
In You Build It You Run It, the team who builds the software is the team who then runs and supports that software in production.
As a result, teams in this model will conduct multiple rounds of incremental tests themselves. They are motivated to ensure the code is highly available because they have to support it in production.
For example, teams in You Build It You Run It will commonly:
- Provision automated unit testing that can be run at any time to ensure that the unit of code that has changed now does what it is supposed to do.
- Provision automated acceptance-based testing to ensure the features meet the acceptance of the users and business
- Provision automated load and performance tests that can ensure that the system can cope with different volume requirements.
- Provision automated security tests that can ensure that the system is secure.
The reason teams will do this is because You Build It You Run It teams are likely to automate their deployment pipleine, so that every change they make is repeatable, reliable, and quick to action.
Without automating all these tests, teams can’t automate their entire pipeline. As a result, manual testing will need to take its place.
When the one team builds and scrutinises their own code to ensure it is highly available—because they’ll be responsible if there are failures in production—there is no need for multiple manual approvals gates in deployment.
In this scenario, there is no need to have time-consuming checkpoints or change management processes prior to approvals for deployment to production because that checklist has been built into the deployment pipeline. With ineffective approvals meetings replaced by an automated pipeline and testing, the deployment process is simplified and, importantly, repeatable and reliable. There is less time spent on handover and a reduced requirement for approvals milestones, but with the same emphasis on QA and rigorous code assessment.
Ultimately, you get the same quality code—or higher—in a much shorter time frame.
Through this approach, we’ve supported clients to improve their deployment throughput from 10 releases per year to over 4,000. Without a correlating rise in production incidents.
While You Build It You Run It can be incredibly potent, it’s worth acknowledging that Ops Run It is still a valid operating model.
The right operating model will depend on the needs of the service; in instances where speed-to-market is critical, You Build It You Run It will typically unlock significant value.
For more information on selecting the right operating model, you can:
- read about selection processes in our You Build It You Run It playbook, or
- read this piece; two things to consider when selecting an operating model for a digital service.
If you’d like to discuss your implementation of Ops Run It, You Build It You Run It or any of the challenges you face in delivering features at speed, I’d love to help.
Are you sitting on a substantial amount of net-present value waiting to be unlocked? Let’s arrange a conversation to find out.
If you haven’t read it yet, check out or first part in this series on how Ops Run It stops speed & denies you value.
It’s a fact. Reducing time-to-market at scale is the best way to increase return on investment for digital organisations.
In a recent study conducted by Forrester, an organisation realised over $41 million of net-present value by improving time-to-market and reducing their ‘concept to cash’ timeline.
By improving the speed at which this organisation consistently delivers new features, it saw:
Significantly increased profits
- A profit increase of $41.1 million from faster time-to-market
- A profit increase of $19.4 million from enhanced performance of custom apps
Reduced costs
- A cost reduction of $716,000 through reduced configuration time
- A cost reduction of $544,000 through net revenue protection for digital applications
The two critical ingredients in unlocking this substantial value were:
- Implementing Paved Roads, which increase productivity, and
- adopting the You Build It You Run It operating model, which substantially improves time-to-market.
The key takeaway is this: if your organisation works in a traditional Ops Run It operating model—defined by having distinct, separate teams involved in the build (Delivery) and support (Operations) of features for a product or service—you may be denying yourself enormous value.
In this five-part series, I’ll look at five key reasons why Ops Run It could be denying you of value. They are:
- Part 1: Ops Run It prioritises stability in a way that fundamentally stops you from delivering at speed (this article).
- Part 2: Ops Run It involves an unnecessarily laborious and manually intensive deployment process.
- Part 3: Ops Run It limits the agility of the development team, making it harder to respond to rapid changes in market conditions or evolving customer needs.
- Part 4: Ops Run It involves an overly strict change management process.
- Part 5: Ops Run It and potential impacts on resourcing for sustained innovation.
So, let’s look into the first reason.
Ops run it prioritises stability in a way that fundamentally stops you from delivering at speed.
In the Ops Run It model, there are no processes or methods in place to actively drive speed. In fact, teams are structured in a way that inherently compromise your ability to consistently deliver new features at pace.
By having separate, compartmentalised teams—being segregated Delivery and Operations teams—you create a scenario where it is necessary to have gates and handovers between those teams.
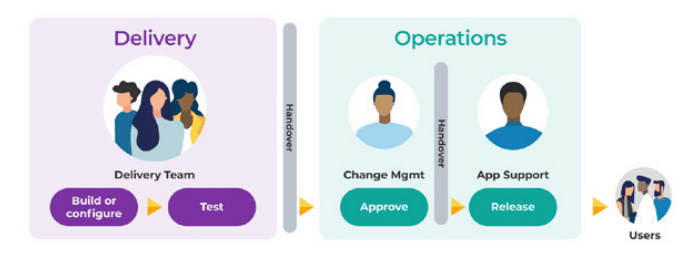
The diagram above highlights a common team structure in Ops Run It, where handovers are a necessity. One handover occurs between Delivery and Operations teams, and the second occurs between Change Management and App Support teams within the Ops team.
These handovers, required for the passing of context and information between segregated teams, inherently create delays.
This structure prevents you from delivering at pace and can deny you the ability to reap huge potential profits.
Let’s consider a practical example.
Think about incident management and the way your team responds when something fails in production.
In an Ops Run It model, the Operations team is responsible for identifying and triaging incidents.
If they cannot rectify an incident, they will eventually contact the Delivery team that originally built the feature. This is known as level 3 support.
In this scenario, there are two negative implications:
- The Operations team will be slower to rectify incidents than the Delivery team who built the software in the first place. This is because they are less familiar with the codebase they’ve been tasked with supporting. There is obviously a cost associated with this delay in fixing incidents.
- The Operations team is solely motivated to prioritise availability. When a team is incentivised to maintain availability (or service stability) at all costs, they are not incentivised to support the rapid delivery of new features. In fact, the rapid delivery of new features can be seen as a threat to the stability of the system.
In this scenario, rapid delivery of new features can be seen as a threat to the stability of the system.
To protect their primary objective of high availability, the Operations team can over engineer the process of change.
They will attempt to safeguard the availability of the system. They likely:
- Reduce the number of changes they make to the system in a given period.
- Deploy changes at night to minimise impact in the event of failure.
- Implement both manual and automated deployment pipelines, rather than fully automate.
- Set up ‘eyes on glass’ monitoring, where people watch systems in anticipation of incidents.
- Batch multiple changes into one release to reduce the number of changes (making each change more risky).
Accumulatively, these practices make it incredibly difficult for an organisation to launch innovative new features at pace. Which means you’re not delivering new value streams for your customers, which means you’re denying yourself of potential profits.
How is You Build It You Run It different?
Critically, You Build It You Run It doesn’t emphasise speed instead of stability.
In fact, You Build It You Run It can contribute to higher levels of service availability than a traditional Ops Run It model. You can read more about this in detail in my piece How to save millions and protect against the cost of unplanned downtime for digital services.
There are many practices in You Build It You Run It that emphasise both speed and stability concurrently.
In this model, the team who builds the software then runs the software.
In contrast to the Ops Run It model, this diagram highlights the lack of handovers required in deploying changes or new features when working in the You Build It You Run It operating model.
This structure immediately creates two clear benefits:
- Given the team who builds the software then runs the software, there is no requirement for time intensive handover meetings. This goes both ways; there is no onboarding involved in getting new features live, and there is no retrospective knowledge sharing required to fix an incident in production.
- Because the team who builds the software is also charged with running the software in production (and are on call in the event of an incident), teams will implement proactive contingencies to remove the risk of failure. They will also ‘architect for adaptability’. This means building services that gradually shutter on failure to ensure business-critical aspects of the service can still generate value.
Teams in You Build It You Run It are able to deliver new features at a much faster rate. They are also empowered to proactively build in measures that promote higher availability.
In contrast, the Operations Team in an Ops Run It model is largely reactive. They do not get hold of new features until they are live and cannot retrospectively implement the same forward-thinking protections that are possible when developing the feature.
You Build It You Run It also supports the ability for teams to implement continuous delivery and continuous deployment, which is impossible to adopt in an Ops Run It model. This provides an additional range of benefits for fast, safe, and reliable delivery.
Ops Run It can deliver value in the right context.
This is not intended as a sweeping criticism of Ops Run It.
Importantly, it’s worth pointing out that Ops Run It is an entirely valid operating model. In scenarios where speed-to-market isn’t a factor, Ops Run It can often be the right approach.
The issue is that many businesses run into the costly pitfalls of going ‘all in’.
Every digital service should be assessed for a range of factors to identify the right operating model. To learn more about these factors, read my article: two things to consider when selecting an operating model for a digital service.
If you’re looking to assess the operating model for your needs, or you’d like to know more about unlocking value by implementing You Build It You Run It, let’s arrange a conversation.
Check out my next article in the series on the unnecessary time spent on manual deployments when using Ops Run It
You Build It You Run It can deliver enormous value. It can accelerate time to market for digital services and features, increase quality, and improve reliability. In the right circumstances, it’s proven to create significant revenue growth. But how much will it cost to realise the value of You Build It You Run It?
Obviously, the answer to that question will change based on a number of factors.
The cost associated with implementing any operating model will likely be influenced by:
- The size and structure of your team
- The number of services you envision running in the operating model
- Whether you’re transitioning an existing service to a different operating model or creating a new service
- How much the service is used
- How the service was originally designed and implemented
That said, while it’s difficult to provide an answer with any kind of dollar-value specificity, we can make a meaningful conceptual comparison of the type of costs associated with implementing different operating models.
Each model—whether Ops Run It or You Build It You Run It—has associated costs that fluctuate at different stages of the implementation lifecycle.
For example, some things take more effort to set up; once configured though, they will deliver greater value over a longer period of time. In contrast, things that are quick and cost-effective to implement in the short term may not deliver substantial value in perpetuity.
When you understand these costs and how they fluctuate over time, you’ll be in a better position to assess which operating model suits your objectives.
Plus, with this information, any business case for a certain operating model can be evaluated in terms of all the relevant financial variables.
That said, it’s worth acknowledging that cost should never be the only consideration in selecting an operating model for a service. It’s best to consider the operational needs of the service, including feature demand and financial exposure on failure, which you can read more about in this article: two things to consider when selecting an operating model for a digital service. Selecting an operating model without consideration of these needs may mean the model you select is not fit for purpose.
Still, for many, cost is an important consideration, so let’s get into the different costs that apply to each operating model.
Common types of cost in operating models.
There are three main cost types I’ll use in comparing Ops Run It with You Build it You Run It. They are:
1. Setup cost.
This is the one-off cost associated with setting up the operational model for a new service. Or, if you’re moving an existing service into a different operating model, the cost associated with that transition process.
In practical terms, you can expect that:
- A high setup cost indicates that you will need to invest a larger amount upfront, in the initial stages of implementing the operating model. This is a one-off cost.
2. Run cost.
The run cost involves the ongoing business-as-usual costs associated with keeping a service operational. This includes things like change management, deployments, and procedures or protocols for incident response.
In practical terms, you can expect that:
- A high run cost means it will be more expensive to maintain the service for the entire time it’s operational. This is an ongoing cost.
3. Opportunity cost.
This is a critical consideration. And one that is frequently—and wrongly—overlooked when assessing an operating model.
In its simplest form, opportunity cost refers to the cost of delay between someone having the idea of a new product feature, and the actual launch of that feature. All the time spent navigating that workflow is time the feature is not earning revenue.
Opportunity cost also includes any prospective revenue that is lost due to operational issues with the service.
Consider opportunity cost in the context of: ‘how many opportunities do I cost myself because I can’t deliver the feature quickly enough, or because the service was down and unavailable for customers?’
For a practical example of opportunity cost, let’s consider a retail business. Often, there’s a requirement to launch new features or services before peak events, like Christmas or the Black Friday sales. Hypothetically, let’s say this retailer wants to launch a ‘click and collect’ service prior to a peak sales event. If the development team is unable to build this service in time (or equally, unable to deploy it to production because of batched release cycles), then the opportunity cost would be the lost revenue the retailer should have made through that ‘click and collect’ service.
With that in mind, we can expect that:
- The higher the opportunity cost, the more prospective revenue left on the table. A high opportunity cost is not desirable.
- Conversely, the lower the opportunity cost, the more revenue you’re capitalising on, because you’re earning all the money associated with every opportunity you identify. A low opportunity cost is desirable.
With these cost types in mind, let’s compare how they apply within the Ops Run It and You Build It You Run It operating models.
Ops Run It vs You Build It You Run It: a cost comparison.
The data in the below graph is based on my experience working with on-call product teams in many different organisations from around the world.
The graph intends to highlight the difference in expected cost types when implementing an operating model for a single software service. These ratios would likely change when economies of scale are a factor.
In this graph, yellow represents Ops Run It, while blue represents You Build It You Run It.
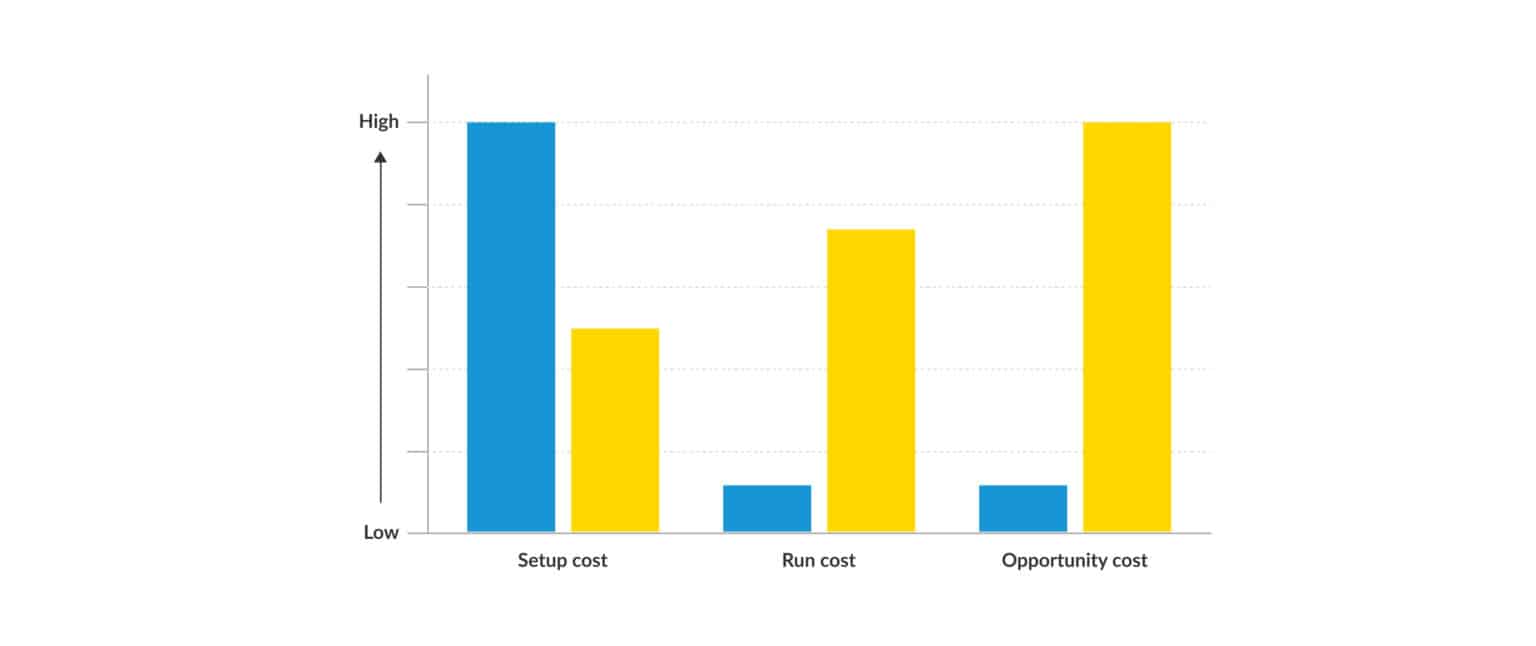
The graph shows that:
- Ops Run It has low setup costs. However, its run costs can be high, and its opportunity costs are very high. It is worth reiterating that both run costs and opportunity costs will recur for the entire duration of any service’s operation.
- The majority of You Build It You Run It costs are incurred as one-off setup costs. Its ongoing run costs and opportunity costs are much lower.
What informs the projections in the graphic above? What are the contributing factors in the comparatively higher setup cost for You Build It You Run It? Why does Ops Run It cost so much in missed opportunities? Let’s take a look:
A detailed cost analysis of You Build It You Run It.
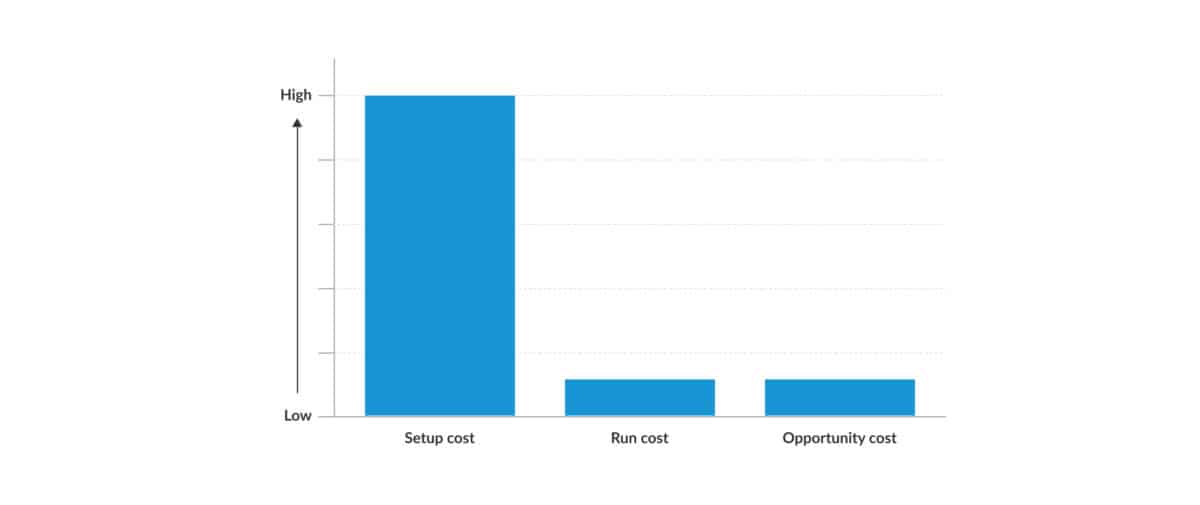
Setup cost in You Build It You Run It.
- Frequency: one off
- Impact: capex cost
- Cost estimate: high
When you set up a software service in You Build It You Run It, there’s a requirement to configure a high amount of automation. Because these tasks are automated, they represent a one off cost. Thanks to this automation, a higher initial investment in set up results in drastically reduced run costs over time. The trick here is to do just the right amount; ensuring that you can launch and make your service available without unnecessarily over-investing in setup. For help in finding that perfect balance, get in contact for a conversation.
Generally speaking, setup cost can include activities like:
- Purchasing licenses for things like telemetry licenses, licensing for SAAS products the service may integrate with, and licensing for additional services that may be consumed in the cloud. Visibility of these considerations will come from the design of the service being built
- Configuring deployment pipelines
- Installing telemetry so the team can visualise prospective incidents
- Setting up live access permissions, so relevant stakeholders have access to the appropriate tier of environment (for example, live versus staging or production)
- Training the team in day-to-day operating practices
- Documenting runbooks
- Providing training for incident response and post-incident reviews
- Developing playbacks and walkthroughs, so anyone in the team can pick up and respond to an incident
- Setting up a new change management process
Run costs in You Build It You Run It.
- Frequency: ongoing per each of the actions listed below
- Impact: capex cost
- Cost estimate: low to medium
Now that we’ve automated a lot of tasks—which are repeatable and reliable—your run costs are largely involved with maintenance. In contrast, Ops Run It involves continued manual effort for run tasks; as those costs accrue, there will come a time where the run cost associated with maintaining a service in Ops Run It eclipses the initial investment (or continued investment) in You Build It You Run It.
In You Build It You Run It, a larger investment is made into setup with the knowledge that your run costs will be reduced in perpetuity, reducing total cost of ownership (TCO).
In You Build It You Run It, run costs can largely be attributed to resourcing the product team’s time for business-as-usual maintenance work, such as:
- Deploying code changes
- Performing deployments
- Rolling back on any failed deployments
- Applying data fixes
- Making configuration changes
- Adding infrastructure capacity
- Monitoring operating conditions
- Updating telemetry tools
- Doing on-call standby during working hours
- Doing on-call standby outside of working hours
- Responding to callouts and managing incidents, both in and out of hours
Opportunity costs in You Build It You Run It.
- Frequency: ongoing per product feature you intend to launch
- Impact: lost revenue and operational costs incurred
- Cost estimate: low
Remember, a lower opportunity cost is a positive outcome. This is because it means there’s very little delay enforced between the idea of a product feature and its launch to market.
In You Build It You Run It, there is very little time spent waiting for change management approval, because deployments are far more frequent and represent a lower risk. When you can release frequently with ease, that’s exactly what product teams do. They may get a set of features or a new service delivered for customers as a minimum viable product (MVP) and iterate through daily deployments. All that time, the team is gaining insights into the service, learning from the way customers interact with the service, and importantly, delivering value—both for your customers and your organisation.
This frees you up to continually respond to customer needs and deliver value faster than your competitors. For more detail on why You Build It You Run It allows value creation at pace, see how to launch new product features to market every day.
A detailed cost analysis of Ops Run It.
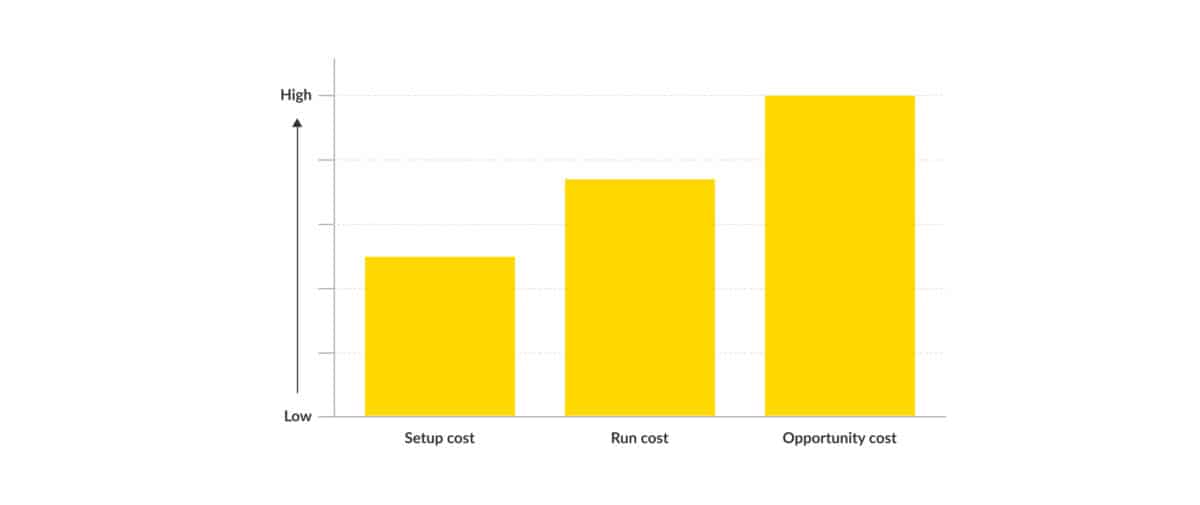
Setup cost in Ops Run It.
- Frequency: one-off
- Impact: capex cost
- Cost estimate: medium
In an Ops Run It model, the building and operational responsibilities are split between multiple teams. As a result of this distribution, there are far fewer things to set up. Setup activities typically involve the application support team:
- Purchasing licenses for things like telemetry licenses, licensing for SAAS products the service may integrate with, and licensing for additional services that may be consumed in the cloud. Visibility of these considerations will come from the design of the service being built
- Installing telemetry
- Agreeing to a handover plan with the delivery team
- Reviewing operational acceptance criteria with the delivery team
Run costs in Ops Run It.
- Frequency: ongoing per each of the actions listed below
- Impact: opex cost
- Cost estimate: medium to high
In Ops Run It, run costs pertain to the ongoing manual effort associated with supporting the service. As mentioned above, these costs are medium to high for the entire duration the service is in operation. With this ongoing level of investment, there will typically come a time where Ops Run It eclipses You Build It You Run It in terms of total cost of ownership.
Run costs in Ops Run It typically involve:
- Requesting change approvals from the change management team
- Performing deployments
- Rolling back any failed deployments
- Applying data fixes
- Making configuration changes
- Adding infrastructure capacity
- Monitoring operating conditions
- Updating telemetry tools
- Doing on-call standby, both in and out of working hours
- Responding to callouts and managing incidents, both in and out of working hours
Opportunity costs in Ops Run It.
- Frequency: ongoing per product feature you intend to launch
- Impact: lost revenue and operational costs incurred
- Cost estimate: high
Remember, a high opportunity cost is a negative outcome. This means a high amount of potential revenue is being lost.
In an Ops Run It model, teams are much more inclined to ‘batch’ the work and deploy it to production only once everything is available. This is typically due to the difficulty involved with making deployments, because everything is manual, time consuming, involves multiple handoffs and approvals processes, and—because you’re deploying more features concurrently—there is greater risk associated with the deployment.
All the time spent waiting on batched deployments is time where services and features fail to generate revenue, and fail to capitalise on potential opportunities.
So, which operating model should you choose?
Inevitably, it depends on the utility of the service in question. It’s a common mistake to take a blanket approach to operating models. In other words, you shouldn’t go ‘all in’ on either You Build It You Run It or Ops Run It for every service. You can read more about this mistaken approach here.
In assessing your service for an operating model, cost is certainly a consideration. However, there are other more critical factors that should inform your selection.
If you’re eager to learn more about the costs associated with operating models—or you’d like to know more about a specific transition or project you need to implement in your organisation—get in touch today to arrange a conversation.
Digital customer experience is more important than ever before. To compete in today’s complex economic environment, you need the ability to adapt, transform, and rapidly launch new, compelling digital capabilities before your competitors.
According to Salesforce’s State of the Connected Customer report, 88% of customers claim the experience a company provides is as important as its product and services.
If that’s not enough motivation, this Forrester research shows that customer experience (CX) leaders grow revenue faster than CX laggards, cut costs, reduce risk, and can charge more for their products.
Basically, CX is critical. Your teams’ ability to deliver compelling differentiators and value for customers—consistently, at pace—will be crucial to your organisation’s success.
You Build It You Run It is the secret weapon that unlocks enormous business potential to give you the competitive advantage. Why?
Here’s what CEOs and CTOs need to know:
1. Delays in speed-to-market for digital services are costing you enormous amounts in prospective revenue.
“Speed is the ultimate weapon in business. All else being equal, the fastest company in any market will win.” – Dave Girouard, Upstart Cofounder and former President of Google’s billion-dollar cloud apps business, Google Enterprise Apps.
You Build It You Run It can play a significant role in reducing time-to-market when scaling digital delivery. And reducing your ‘concept to cash’ timeline is proven to drive significant business growth.
A recent Forrester TEI (Total Economic Impact™) study revealed that reducing time-to-market consistently across multiple delivery teams helped customers realise a 123% return on investment.
Building paved roads, adopting the You Build It You Run It operating model and using other techniques to reduce the time from ideation to deployment was the greatest driver of business benefit.
In the study, using data aggregated from four organisations we’ve worked with, over $41,000,000 of net present value was realised by improving time-to-market.
The You Build It You Run It operating model drastically reduces time to market for new strategic digital initiatives. Then, scales that capability across many teams.
One of the most critical things to do is understand your current time to market and quantify how much revenue you’re losing in opportunity cost and cost of delay. Cost of delay is an indicative calculation used to measure and understand the benefits you stand to lose by delaying a decision. It can relate to the delay of a migration, a feature update, or a production deployment.
Too many organisations have limited ability to deliver innovative digital services frequently, at pace. You may be hampered by slow, complicated processes to move ideas to deployment. Or perhaps you’ve invested in technology that is costly and cumbersome to change.
Whatever the reasons, decreased speed to market gives your competitors the advantage.
You only need to ask yourself: how long will you leave millions of dollars of prospective revenue on the table? How long will you let the competition reach your customers with new products, services and offers before you?
2. Markets are oversaturated and hyper-competitive: innovating frequently is the best way to establish valuable differentiation.
“Creativity is thinking up new things. Innovation is doing new things.” – Theodore Levitt, economist and professor at Harvard Business School.
Working with enterprise organisations, I notice far too many businesses struggle to offer meaningful differentiation in their digital channels.
Why?
Complex, inflexible deployment and approvals processes make it impossible to deliver new market offerings or strategic differentiators at pace.
And, as we’ve already noted in point 1:
If you’re not continuously innovating to offer new streams of value for prospective customers, your competitors are.
Choosing commercial off-the-shelf software is often seen as a strategy to launch new features quickly. But you’re only going to access and leverage the same features as your competitors.
You need to build and run digital services in a way that allows flexibility. In a way that meets the needs of evolving strategies or customer needs.
You Build It You Run It empowers teams to deliver far more features—and more business value—faster and at higher quality. We’ve supported global organisations to move from 10 deployments per year to more than 4,000, without a correlating increase in production incidents.
Are you delivering enough value, frequently enough, to stand out in a hyper-competitive market?
Learn more about how You Build It You Run It can help you launch new product features to market every day.
3. Poor, unreliable service is poor customer service: You Build It You Run It can reduce incidents, improve availability, and enhance profit protection.
When it comes to digital CX, exceptional service is the baseline expectation. Latency is simply not an option.
In 2006, Amazon software engineer found that Greg Linden found that every 100 milliseconds in service latency cost them 1% in sales. In the same year, Google VP Marissa Mayer found that a half-second delay in generating search results caused a 20% drop in traffic.
In 2018, Google shared that as page load time increases on mobile devices:
- From 1 second to 3 seconds, the probability of a customer leaving the site without any meaningful action (also called ‘bounce rate’) increases 32%.
- From 1 second to 5 seconds, the probability of bounce increases 90%.
- From 1 second to 6 seconds, the probability of bounce increases 106%.
- From 1 second to 10 seconds, the probability of bounce increases 123%.
In other words, every second your site or digital service is unavailable, the likelihood your customers will defer to a competitor increases exponentially.
You Build It You Run It can drastically improve service availability and reduce time to resolve incidents by:
- Incentivising teams to architect for adaptability, building contingencies so that vital customer service functions are still available in the event of an incident.
- Encouraging teams to build proactive measures into services to prioritise availability because they own every aspect of the service, from feature development to operations.
- And many more: learn how You Build It You Run It provides crucial protections against unplanned downtime.
***
There you have it. You Build It You Run It supports enterprise teams and organisations to unlock enormous value, based on:
- Empowering you to deliver new services to customers faster than ever before.
- Ensuring you can meaningfully and valuably differentiate your organisation in the minds of customers.
- Enhancing service reliability and protecting against costly downtime.
If you’re ready to embrace high performance software teams that deliver consistent and significant business value, let’s arrange a conversation.
If you’re about to adopt the You Build It You Run It operating model—or you’re already in the early stages of working in it—it’s crucial to ensure your team has everything required to succeed.
In my experience supporting teams to create more tangible business value by adopting You Build It You Run It, there are two common risks to success:
- A failure to implement the operational and logistical things needed for the model to succeed, and
- A failure to consider the impact on the team–personally and professionally–that can come from a new way of working.
In this piece, I’ll focus on the second risk. For more information on the first risk—including steps you can take to mitigate its impact—have a read through this article highlighting four reasons developers won’t embrace You Build It You Run It (and how to overcome them).
While the first risk is often seen as critical, it’s equally crucial to pause and consider the team in any type of transition in the workplace. By ensuring team members feel heard and motivated, we can reduce the potential negative personal and professional impacts of the transition process.
There are many different ways we can try to achieve a positive outcome, grouped together as ‘the five types of intrinsic motivation’.
The five types of intrinsic motivation
In looking at the motivation of software development teams, I often reference the insightful work of Shonna Waters.
Shonna works for an organisation called BetterUp—who drive optimal performance in teams—and holds a PhD in Industrial-Organisational Psychology and Statistics. She is also an ICF-certified coach.
In this recent piece, Shonna suggests there are five types of intrinsic motivation. Intrinsic motivation (or internal motivation) refers to the motivators that drive us to do something for its own sake; simply because the activity aligns with our interests or values. It is distinct from extrinsic motivation (or external motivation), like rewards or consequences for certain behaviours.
The five types of intrinsic motivation are:
- Learning motivation
- Attitude motivation
- Achievement motivation
- Creative motivation
- Physiological motivation
Let’s unpack each of the five types of intrinsic motivation and how you can use them in the context of You Build It You Run It.
1. Learning motivation
If people are driven by learning motivation, they’re incentivized by the accumulation of knowledge. By trying new things and enhancing skills and experience.
This type of person is driven by a desire to learn more and improve performance.
How does learning motivation apply in the context of You Build It You Run It?
In a You Build It You Run It operating model, developers are able to see how customers use the features they’ve built. This is because they’re involved in supporting the service once it’s live.
By seeing how people interact with the services you build, you develop enormous insights into the features that best support customer needs and behaviours. With these learnings, the team can prioritise and build features that will make their service or product infinitely more effective.
In other words, they continuously learn and drastically improve their output as a result.
These same learning opportunities are not facilitated in an Ops Run It model, because the team is not in close enough proximity to the customer. They hand the features they build to a separate operations team to implement and operate. In an Ops Run It model, the team works in isolation of the customer, removed from the insights associated with seeing people use what they build.
2. Attitude motivation
Attitude motivation refers to a desire to be positive and spread positivity. These types of people are driven by a desire to feel good about the work they’ve done.
How does attitude motivation apply in the context of You Build It You Run It?
Simple. Look for opportunities to praise your team. To celebrate their sense of accomplishment and make them feel valued within the organisation.
Given that You Build It You Run It empowers teams to take greater ownership of results, there will be many.
Some obvious examples could include highlighting:
- The number of incidents the team is able to identify and fix within a rapid time frame.
- Any improvements in average response time for rectifying issues.
- How much money the team has saved the organisation by actively pre-empting incidents and implementing fixes.
3. Achievement motivation
This one’s a relatively single proposition: it’s about getting things done. Sheer volume of output; a sense of achieving things.
These people are driven by reaching the finish line or hitting key milestones.
How does achievement motivation apply in the context of You Build It You Run It?
You Build It You Run It is extremely potent in helping teams achieve more.
For example, they might be able to deploy new features to production in weekly or daily cycles. This is in contrast to monthly or quarterly batched deployments.
We’ve helped teams go from 10 deployments a year to over 4,000 without a correlating rise in incidents.
If teams are motivated by getting things done, working in a You Build It You Run It operating model can provide an enormous sense of achievement.
4. Creative motivation
Some people are motivated by solving complex problems.
In these instances, people or teams are driven by being creative and having opportunities to express their lateral thinking.
How does creative motivation apply in the context of You Build It You Run It?
It’s a common misconception to assume that—because teams are now responsible for operations and feature development—You Build It You Run It will stifle creativity and prevent teams from ruminating or experimenting.
With the right supports in place, You Build It You Run It should invigorate people with creative motivation. This is because it’s an exceptional way to provide teams with more ownership over their end-to-end digital service. In turn, this creates many opportunities for compelling software development challenges the team may not have broached or considered previously.
For example, consider the following challenge: ‘we want to reduce this service’s number of incidents by 10%. What contingencies can you build, or availability measures can you implement, to help our organisation achieve this goal?’
With the right approach, the operational side of maintaining a service should represent stimulating opportunities for developers, rather than onerous responsibilities.
5. Physiological motivation
Physiological motivation refers to basic needs like food and water. Think about Maslow’s hierarchy of needs: physiological motivation refers to needs at the lower levels of the pyramid.
How does physiological motivation apply in the context of You Build It You Run It?
Conceptually, this is a little trickier, and treads the line between being an intrinsic and extrinsic motivator.
In my opinion, this links back to remuneration. And specifically, ensuring you have the right processes in place to remunerate developers appropriately.
If developers are required to provide out-of-ours support (and they may not always have to, depending on the requirements of the digital service in question), you need to remunerate them appropriately for their effort.
At the very least, you need to implement a range of measures to protect against burnout for developers on call.
***
So, there you have it. Five simple, yet surprisingly effective, techniques you can use to ensure You Build It You Run It resonates with the different personality types in your team.
If you implement these correctly and consistently—along with some of the operational and logistical things needed for the model to succeed—you’ll have a greater chance at success. And therefore, a greater chance of reaping the many benefits associated with You Build It You Run It.
For more information on getting the best out of your team check out the video below & visit our YouTube channel or keep checking this blog for further updates.
As a business, you should never go ‘all in’ on either Ops Run It or You Build It You Run It. Why? Because the operating model you select should be chosen based on the unique requirements of each digital service. So, the obvious question becomes: what do you assess to determine the ideal operating model?
Firstly, let’s clarify some terminology. When I talk about assessing a ‘service’, I’m referring to anything from digital services (like a customer facing e-commerce application) to foundational systems.
And while their requirements might be quite different, you can use the same metrics to assess the most suitable IT operating model.
Those metrics are:
- The demand of deployment throughput for the individual service, and
- The financial exposure on failure of that service.
1. Calculate your service’s deployment throughput.
The first thing to determine is the throughput requirement for your service.
That means:
- How often are changes needed for that service?
- How often will it be valuable to deploy new features within a certain period of time?
To answer those questions, you really need to ask yourself, at a business level:
- Will this specific service create more value by getting deployments to market quickly?
- Will this service benefit from launching new features to customers far more regularly?
The utility of your service will drive the deployment throughput, and there are many ways this can play out.
For example, you might only want to change a service once each week. But when you make that change, you need it deployed incredibly quickly. Compare that to a requirement where you have multiple changes per week for a service, but they can be deployed less rapidly.
If you’re deploying one or two features per fortnight, that is a low requirement for throughput.
On the other hand, deploying multiple features per week—or even per day—indicates a higher requirement for deployment throughput.
The higher a service’s requirement for deployment throughput, the more likely you will benefit from a You Build It You Run It operating model.
Services with a higher requirement for deployment throughput (i.e. deploying multiple features per day, rapidly) will likely see significant benefit from a You Build It You Run It operating model. This is largely because your team will have far more control over how quickly they can make deployments.
In contrast, an Ops Run It model typically involves rigid schedules and gated milestones. This is problematic when, in my experience, most organisations want the control and flexibility to deploy new features independently. Or, to have more granular control on how much they deploy and when, rather than waiting for a cyclical batched deployment that could take weeks (or months).
You Build It You Run It is an excellent way to achieve this flexibility and remove the constraints—and risks—associated with batched deployment.
Learn more about how You Build It You Run It can support your team to launch new product features to market every day.
In these instances, You Build It You Run It can also mitigate risk
In addition to providing greater flexibility for deployment cadence, You Build It You Run It can remove the risks associated with batched deployment. This is because:
- More frequent deployments mean you can be more incremental in your approach, minimising the potential blast radius of a failure.
- Fewer features are deployed as a bundle, meaning less risk of failure.
- It’s easier, faster and more cost-effective to identify the cause of a failure
2. Understand your service’s financial exposure on failure.
Almost inevitably, whenever you ask a business ‘how much does your service need to be up and available?’ the answer is: ‘All the time. 24/7
Alternatively, you might hear: ‘we have a five-nine requirement – 99.999% availability.’
Fair enough. Always on means always profitable, right?
Wrong.
In fact, an ‘always available’ approach can create unnecessary costs.
This is where I typically ask the following types of questions:
- Are you more financially exposed (i.e. will you lose more revenue) if the service goes down at one time as opposed to another? For example, during the day versus 3am?
- How much will the business stand to lose if the service goes down?
- How much revenue is not generated if the service goes down?
- How many customer complaints will the service’s failure cause, which in turn will cost you money?
These questions are designed to help you think of financial exposure on failure as a mix of:
- the costs associated with lost prospective revenue when you have an incident (for example, sales that don’t go through) and
- the costs of treating and resolving incidents for a service (for example, calling an out-of-hours support team to rectify an issue).
Let’s look at two applied examples for different types of services, in the context of a national retail business. The services are as follows:
- An operations system for packing and shipping orders in the warehouse: this service will have significant financial exposure during working hours only (assuming the shop doesn’t offer round-the-clock shipping). This is because workers will depend on the service to complete their role in the warehouse during business hours; if the service goes down, they are sitting inactive and unable to process orders. If the service goes down out of working hours—when there are no employers relying on the service—there is far less financial impact.
- Customer-facing ecommerce services: in comparison, this service will likely have greater financial exposure on fail, for a wider window. People might be shopping online in the early morning, throughout the day and into the evening. If the service goes down, we lose potential revenue on prospective sales because people can’t buy products.
Your service’s financial exposure should inform an availability target
When assessing an availability target, we consider availability requirements across the whole day.
For example, 99.999% availability means a service can only be unavailable for a few seconds over the course of the day. In comparison, a 95% availability target can allow services to be down for an hour or two.
Considering the two examples above:
- The operations system for packing and shipping orders in the warehouse: the financial exposure here will be much lower than the business might expect, because the service only need to be available from 8am to 6pm.
- Customer-facing ecommerce services: the financial exposure here is much higher and for a longer period of time throughout the day. As a result, the availability target should be much higher to protect against lost revenue during service downtime.
With figures for deployment throughput and financial exposure on failure, you can select an appropriate operating model.
The higher your requirement for deployment throughput, the more your service will benefit from You Build It You Run It.
The higher your financial exposure on failure—and therefore the higher your availability target—the more your service will benefit from You Build It You Run It.
But what if you have a high financial exposure on failure and a low requirement for deployment throughput?
The chart below offers a basic guide to help you identify the most suitable operating model based on your requirements for each metric.
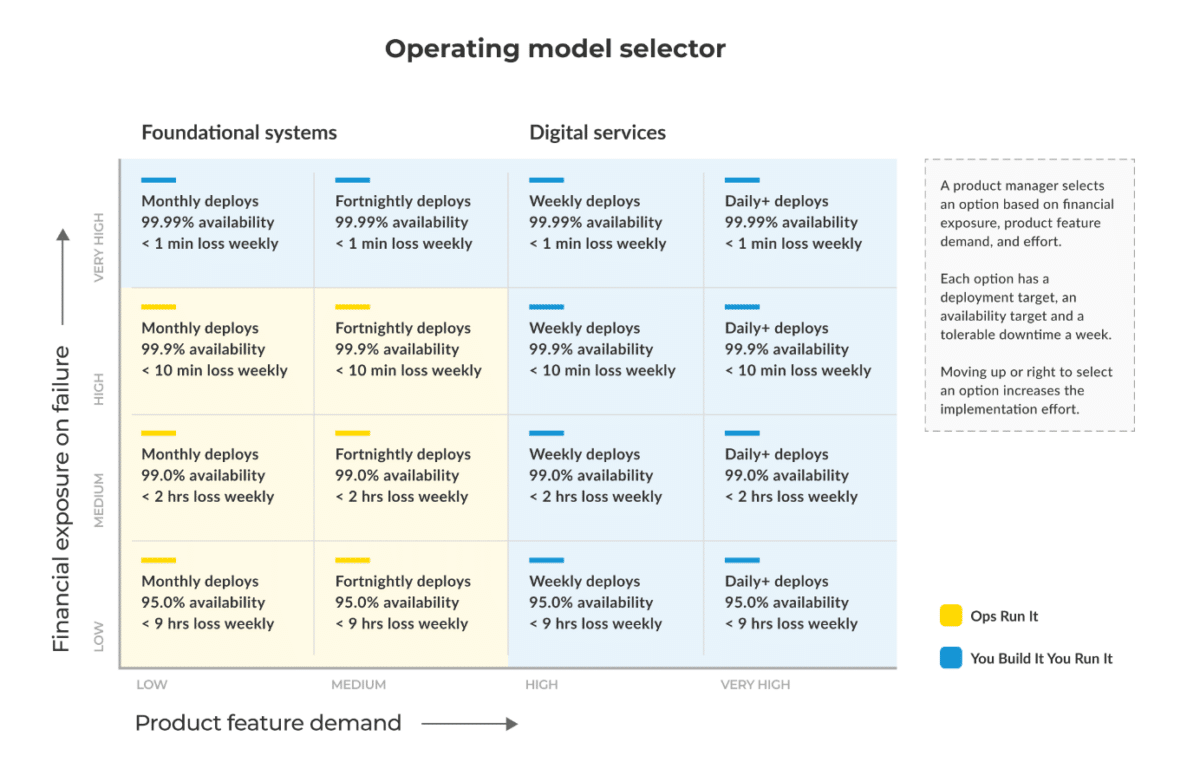
If you’d like to know more about You Build It You Run It check out the video below. You can also find more information in: Build It You Run It Playbook
If you’re looking for more guidance in assessing services or systems, or you’d like to talk about your organisation’s unique requirements, please get in touch to arrange a conversation.
Adopting a You Build It You Run It operating model can unlock enormous business growth. It can provide greater flexibility and enhance reliability for your digital services. It can create much happier developer teams.
Inevitably though—like anything that offers genuine growth and value—it can also come with some perceived challenges and scepticism. After all, as humans, many of us are hard-wired to resist change.
Additionally, there’s a sentiment from pockets of the software development community that ‘developers don’t want to do operations’, and therefore by extension, don’t want to adopt You Build It You Run It.
Interestingly, this is a sentiment I hear from industry commentators more so than developers themselves. That said, in my experience there are some common reservations that developers do offer up when presented with the prospect of moving to You Build It You Run It.
So, here they are, with some techniques you can use to overcome them.
1. “It’s really difficult to support the service”.
Adopting You Build It You Run It means teams will both build and support digital services.
When development teams suggest that a digital service is difficult to support, it’s often a symptom of deeper issues.
The first of these issues is that the service hasn’t been architected for adaptability. So, in reality, it is difficult to support.
The second is that there are no ‘paved roads’ in place. As defined in this excellent article by Equal Experts’ Alan Coppack, paved roads consist of low-friction, hardened interfaces that comprise common user journeys for Digital Service teams. Examples might include building a service, deploying a service, or service alerts. In summary, building paved roads is about removing friction from frequent processes or user journeys.
Without paved roads in place—which abstract unnecessary complexity and cognitive load away from the team’s day-to-day responsibility of focusing on a single digital service—the development team has to do everything associated with operating the service, all the time. This means:
- Running the deployment pipelines
- Running the cloud underneath the service
- Testing
- The whole shebang.
In this scenario, it’s common for a team’s workload to become overwhelming because the cognitive load becomes enormous. Without correcting, teams will inevitably suffer burn out. Incidentally, you can read more about mitigating developer burn out in this article.
How to overcome this challenge.
No prizes for guessing this one: build out the required paved roads.
This allows you to abstract problems away from one development team, so they can focus more exclusively on their role in relation to a specific service.
Generally speaking, you can consider paved roads in relation to four broad categories:
- 1: Build and deployment—How do I build a service? How do I deploy it? How do I get it out to production?
- 2: Telemetry—How do I monitor a service? How do I log on it?
- 3: Enablement—How do I create a service in the first place? Is the cloud set up to manage and provide resiliency?
- 4: User access and security controls.
Beyond removing complexity for one team, paved roads also provide valuable economies of scale. For example, when you have multiple delivery teams, these paved roads can support all of them. In that instance, you would have a dedicated platform team to solely build and run paved roads.
If you’re keen to learn more about paved roads, there is enormous insight and value in our Digital Platforms playbook.
2. “We don’t want to work on support out of hours.”
Firstly, this is an entirely valid reservation. We shouldn’t expect teams to work out of hours without the right supports and incentives in place.
Here, we need to understand why the architecture is built in a way that forces people to work out of hours. It’s enormously important to understand so we can rearchitect the service to remedy the situation.
At a personal level, it’s also about understanding and empathising with peoples’ circumstances.
They could have all sorts of things going on. Some common scenarios include:
- Not having the skills or support to feel confident in an out of hours role.
- Caring for children or family members.
- Sometimes, even having responsibilities with another job, because they’re not being paid enough to complete this type of support work.
How to overcome this challenge.
There are two courses of action to take in response to this concern:
- Understand and empathise with peoples’ personal circumstances.
- Analyse the service to determine whether out of hours support is necessary. In my experience, in many cases, it’s not.
This is because many organisations mistakenly take a blanket approach to operations—rather than select an operating model based on the actual availability requirements of that service.
More often than not, businesses assume a service has a requirement of 99.9% availability.
People wrongly assume ‘we need this service available all night’, and developers are unnecessarily supporting those services out of hours.
There are ways to test that assumption and determine the real availability requirements of a service.
With less requirement for out of hours support, you’ll have less requirement for developers to do this type of work. And less cause for their concern.
3. “We won’t be remunerated properly.”
Again, this is a legitimate concern for teams adopting a You Build It You Run It operating model.
In my experience, developers are often asked to work out of hours and they’re not paid for it.
A common technique is to provide ‘time off in lieu’—rather than pay—as compensation.
This can be a fallacy though; despite receiving time in lieu, developers can’t actually take time off because of a critical requirement to produce more features from an overwhelming backlog,
In these situations, you can become trapped in a never-ending cycle of ‘get more features out’—support the service—get more features out—support the service.
And there’s no real time to take the time off in lieu within this cycle. So, from the developers’ perspective, there’s no respite and no remuneration.
How to overcome this challenge.
This pressure to deliver new features can come from a range of sources:
- Perhaps you’re not delivering frequently and iteratively enough.
- Perhaps there’s pressure to develop features rather than ensure reliability of service—or that there’s not an appropriate analysis of where the most value lies; whether in developing new features or keeping the service live.
There’s a simple solution to managing this bottleneck: appoint a product manager to the team—or across multiple teams—to assist in clarifying priority and managing backlog.
4. “We just want to build new features. Our job is to focus on development work, not operations.”
Again, I hear this statement being referenced by industry commentators, but I don’t see it expressed in the reality of working with development teams.
If we do encounter this sentiment, I’d look at the team’s motivation. Particularly, how they view the problem they’ve been tasked with solving.
How to overcome this challenge.
Re-frame the problem so there’s no perception the team is being forced to inherit operations.
For example, give them the space and support to focus on rebuilding the service so that it’s robust and reliable, with a number of contingencies in place to mitigate the need for onerous operations tasks.
Rather than say ‘monitor this and ensure there are no incidents’, try the following:
- Use your creativity to build something that won’t fall over in production.
- How might we ensure the service is architected for adaptability and create something that’s highly resilient?
How to support your team(s) in adopting You Build It You Run It.
It’s one thing to tell a team ‘we’re implementing You Build It You Run It and you’re in charge of operations now’.
It’s another thing to implement the necessary supporting mechanisms and structures that allow the team to flourish in a new operating model.
I often see teams being told to support a service in You Build It You Run It, without being appropriately supported themselves. They’re not given the things that allow them to prosper, and the success and value of the operating model is compromised.
To recap those things are:
- A service that’s architected for adaptability.
- Paved roads.
- A thorough assessment as to whether services genuinely require out of hours support.
- Appropriate remuneration for out of hours support.
To find out more, watch our video below.
I speak with customers and consultants across the Equal Experts network, to help our customers understand how to speed up innovation and reduce total cost of ownership at scale. Sometimes, our customers refer to this broadly as ‘scaling agile delivery’.
We’ve helped a lot of organizations to scale agile delivery successfully. Forrester Research recently published a Total Economic Impact (TEI) study that shows partnering with Equal Experts achieved a 123% ROI and 60% reduction in time to market for:
- A food franchise scaleup: 10 teams, 40 workloads
- A consulting organization: 10 teams, 100 workloads
- A high end retailer: 40 teams, 75 workloads
- A government department: 80 teams, 900 workloads
It’s hard to implement cross-functional, outcome-oriented teams delivering complementary product capabilities. The good news is success leads to a faster time to market, better quality, reduced risks, lower costs, and better user outcomes which improve your bottom line. My colleague Jon Ayre recently talked about how to iteratively scale agile. I’ll take that a step further. Here are four ways to scale up your delivery capabilities:
- Set teams up to have alignment with autonomy
- Introduce a You Build It You Run It operating model
- Focus on frictionless onboarding
- Create paved roads to allow teams to focus on delivering business value.
Create alignment with autonomy
Teams make faster and better decisions when they understand the intent, purpose, and constraints behind their work, and when they can act for themselves. Teams need to be aligned to deliver on strategy and execution, and autonomous to deliver outcomes without handoffs.
The problem is organizations often implement alignment as command and control. Teams are forced to treat alignment and autonomy as opposites, and they become stuck in one of two scenarios:
- Autocracy. Teams have high alignment but low autonomy. They incur delays because they can’t make decisions. At a media conglomerate, I saw 8 teams who constantly had to wait for 2 shared product managers to make all their decisions for them.
- Anarchy. Teams have high autonomy but low alignment. They’re unaware if they’re making good decisions or not. At an insurer, I saw 10 teams spending ~80% of their time on unplanned BAU work, because they’d implemented 10 different services with 10 different AWS runtimes.
The solution is to replace command and control with contextual alignment, and give teams the freedom to make good decisions in aligned autonomy. See why you need alignment with autonomy at scale.
Adopt You Build It You Run It
Teams achieve higher throughput, greater reliability, and a continuous learning culture when they build and run their own workloads. Teams need to become accountable for reliability as well as functionality, and focussed on outcomes rather than outputs.
The problem is organizational inertia towards using a central operations team to run differentiated digital services. It’s not possible to achieve a high throughput, high reliability baseline when delivery teams and an operations team are set up to work at cross-purposes. I’ve seen many organizations struggle to innovate because handoffs, competing priorities, and misaligned incentives occur every day.
The solution is to adopt the You Build It You Run It operating model for differentiated services, and keep your operations team for foundational systems. Make your product managers accountable for reliability, and put product teams on-call. See You Build It You Run It sounds great but it won’t work here and the You Build It You Run It playbook.
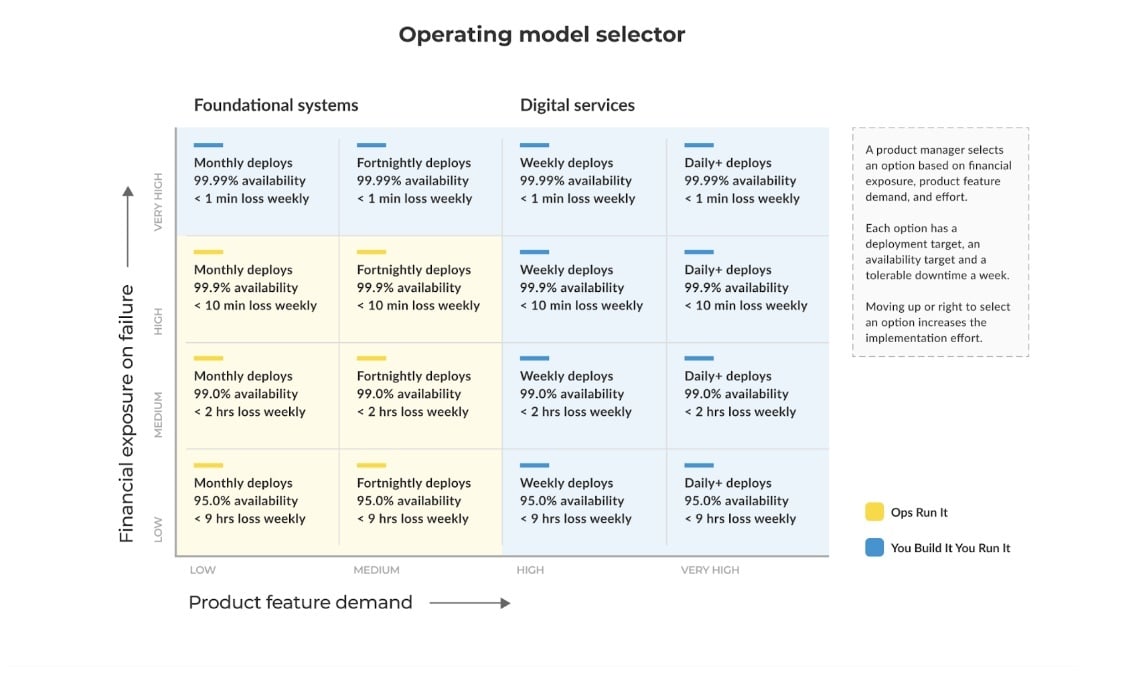
Focus on frictionless team onboarding
Teams are more effective when new engineers can make meaningful contributions as soon as they join up. Teams need a friction-free onboarding process that allows people to join a team and be productive on day one.
The problem is organizations usually treat onboarding as an afterthought. The onboarding process is disjointed and time-consuming, because it lacks a clear owner and is split between multiple organizational functions. I’ve seen engineers on a new team wait for weeks to commit their first line of code, because they’re waiting for the necessary permissions.
The solution is to automate onboarding tasks and reserve team capacity for knowledge sharing, so new joiners are immediately productive. Replace gatekeeping with trust and verify, share business domain knowledge, and establish a Bring Your Own Devices (BYOD) policy. See seven onboarding tips to accelerate productivity.
Build paved roads
Teams can deliver many user outcomes at pace when a majority of technology challenges are solved for them ahead of time. Teams need tasks such as microservice creation and telemetry provisioning to be self-service, fully automated, and fault free.
The problem is centralized technology capabilities are rarely designed to be user-centric. Teams can’t accelerate because they depend on platform teams focussed on infrastructure standardization, rather than the needs of their consumers. I’ve seen teams wait for weeks for a microservice provisioning ticket to be actioned by a platform team.
The solution is for platform teams to partner with product teams to create bi-directional feedback loops, and deliver self-service paved roads formed around engineer user journeys. Create a positive engineering experience for teams, focus on solving business problems with minimal cognitive load, and prevent platform teams from becoming service desks. See the Digital Platform Playbook.
Find out more
If you’d like to know more about how to successfully scale for agile delivery, get in touch! We’d love to hear from you.
You’ve probably heard of You Build It You Run It before. It’s an operating model that empowers product teams to own every aspect of digital service management. When done well, it accelerates your time to market, increases your service reliability, and grows a learning culture. There are also some pitfalls, which can drain the confidence of your senior leadership, and ultimately put the success of You Build It You Run It at risk.
In our recent You Build It You Run It playbook, my co-author Steve Smith and I take a deeper look at the embedded specialists pitfall. You can guard against this pitfall, and even escape it if necessary.
Teams of specialists suffer at scale
Steve and I often see organisations with small, central teams of specialists supporting a number of delivery teams. For example, you might have some delivery teams and an application support team dependent upon a small DBA team, for the provisioning of your on-premise relational databases and management of your user data.
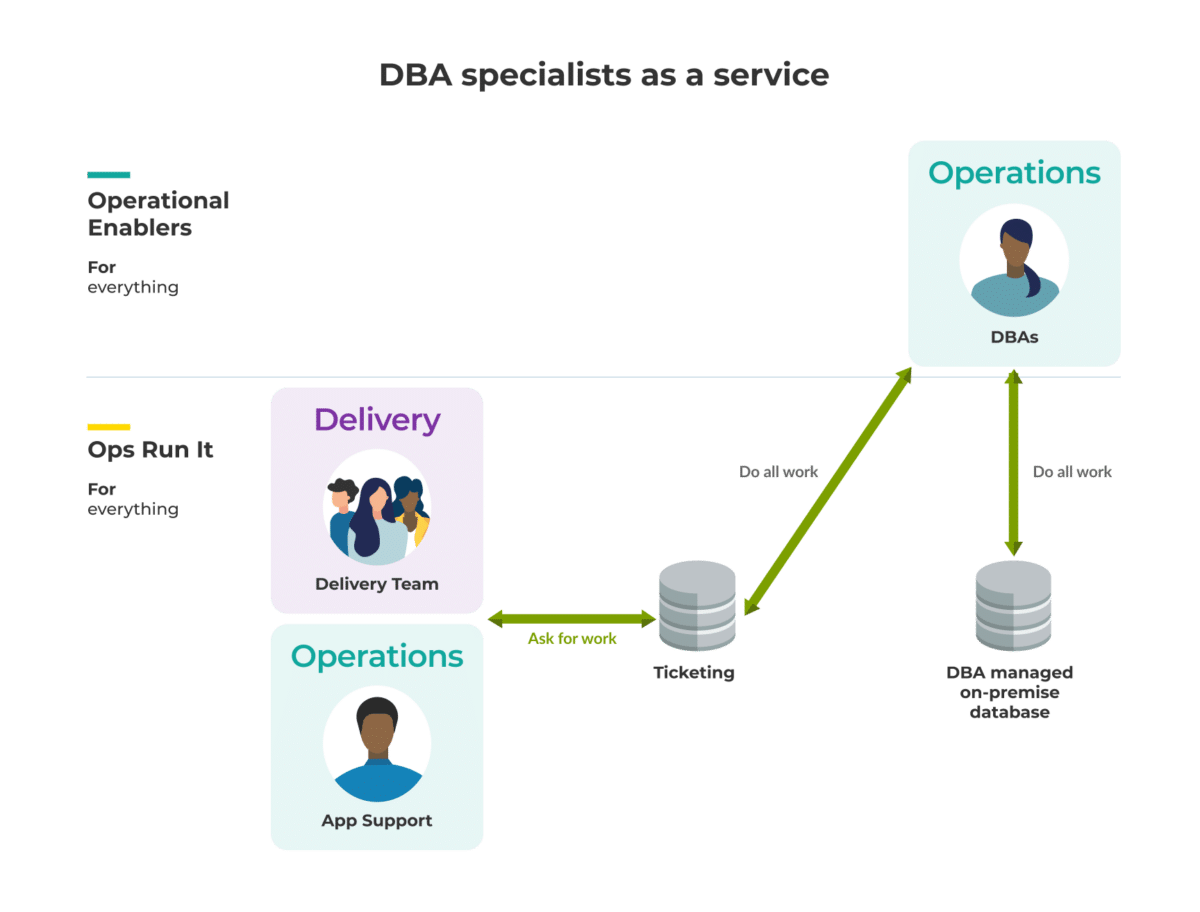
You don’t want developers to manage database backups themselves, nor to debug a live database with millions of rows of user data. At the same time, your DBAs can’t transfer their depth of expertise to developers. This means DBA workload will inevitably increase as you add more delivery teams, no matter how skilled your DBAs are. Conflicting prioritisation calls, strained relationships, and a lack of delivery team progress are likely, as well as burnout for your DBAs.
Steve and I have seen specialists in this situation too many times, in different organisations and in different specialisations. We’ve seen it with DBAs, InfoSec analysts, network admins, and operability engineers (which you might know as DevOps). In addition, the easy answer of recruiting more specialists into the central team doesn’t usually work, because there’s a consistent scarcity of affordable specialists in the marketplace.
The embedded specialists pitfall
You Build It You Run It is an operating model in which product teams build, deploy, operate, and support their own digital services. If your organisation adopts You Build It You Run It and you have multiple product teams constrained by a struggling specialist team, one solution that could be considered is embedding those specialists into the product teams. In other words, if you had 10 product teams and one team of 10 DBAs, you would embed each DBA into one of the 10 product teams.
Steve and I call this the embedded specialists pitfall. It’s the logical extreme of You Build It You Run It, and it’s not a good idea. In theory, embedded specialists will act as first responders, and influence technical quality on product teams via their deep expertise. However, we’ve seen serious problems emerge for embedded specialists:
- Multiple assignments. Your embedded specialists are each assigned to multiple teams, because you have N product teams, less than N specialists available, and recruiting more specialists is difficult.
- Unpredictable workloads. Your embedded specialists are either bored from a lack of work, or burned out from too much work across multiple product teams.
- Lack of knowledge sharing. Your embedded specialists don’t have opportunities to work together, learn from one another, or even talk to another. They can feel lonely.
Tom Clark spoke at DevOps Enterprise Summit Europe 2019 about how this pitfall affected the ITV Common Platform. ITV tried to embed a platform engineer into each product team, and the engineers suffered from multiple assignments, unpredictable workloads, and a lack of knowledge sharing. This had a direct, negative impact which led to technology stagnation and reduced developer productivity.
So, if the answer isn’t adding more specialists to a central team, or embedding specialists into product teams… what do you do?
Establish specialists as a service
You can achieve a step change in productivity by turning your specialist teams into consumable specialist as a service offerings, and achieving a balance between cross-functional product teams and depth of specialist expertise that’s right for your organisation. Steve and I recommend the following:
- Offload non-specialist tasks to product teams.
- Map out specialist tasks and the associated actions. For example, you should offload repeatable, low value tasks to your cloud provider. You should automate repeatable, high value tasks in a deployment pipeline. And retain ad hoc, high value tasks as is. See the table below for more details.
- Establish low friction, public messaging channels for bi-directional feedback loops, #ask-the-dbas, #ask-network-admins.
- Create public ticket queues to show planned work and work in progress for specialists.
Specialist tasks can be mapped in terms of repeatability and value-add.

The goal is to remove toil for your specialists, and free them up to concentrate on high value scenarios in which product teams really need their deep expertise. Their expertise is too scarce, and too important, to be wasted on tasks that can be handled by your cloud provider or product teams.
Further reading
To find out more, you can continue our You Build It You Run It pitfalls series:
- 7 pitfalls to avoid with You Build It You Run It
- 5 ways to minimise your run costs with You Build It You Run It
- Why your operations manager shouldn’t be accountable for digital reliability
- How to manage BAU in product teams
- 4 ways to remove the treacle in change management
- Why product teams still need major incident management
- Stop trying to embed specialists in every product team – you are here!
- How to avoid developer burnout on call
Our You Build It You Run It page has loads of resources on on-call product teams – case studies, conference talks, in-depth articles, and more. Plus our You Build It You Run It playbook gives you a deep dive into how to make it happen!
Today’s most successful organisations are fast and flexible. They can deploy new features for digital services to meet rapidly evolving customer demands and market opportunities. They capitalise on first-mover advantage and sustain innovation: improving digital services incrementally through weekly—or even daily—deployments.
For many businesses, maintaining or achieving rapid time-to-market is a constant challenge. If the same is true for you, you’re not alone. We constantly hear the same type of complaints from many different organisations, at every level:
“IT is too slow.”
“We can’t get new initiatives delivered quickly enough.”
“New features consistently run late in delivery or get bogged down in approvals processes.”
“We don’t react to the needs of our customers.”
“The tech team is a constant bottleneck.”
In many cases, it may not actually be the tech team causing the blockages that impede your ability to deliver value, at pace, consistently. It could be the way your tech team is structured that’s the issue. And adopting an alternative operating model—called You Build It You Run It—could be the answer to your problems.
We’ve helped clients make enormous gains in deployment throughput by adopting You Build It You Run It: from 10 deployments a year to 4000+, without a correlating increase in production incidents.
So, how do you manage deployments in a You Build It You Run It operating model, and how does it differ to your—likely—current deployment process (often referred to as ‘Ops Run It’)?
Deployment in ‘Ops Run It’: the common, conventional IT approach.
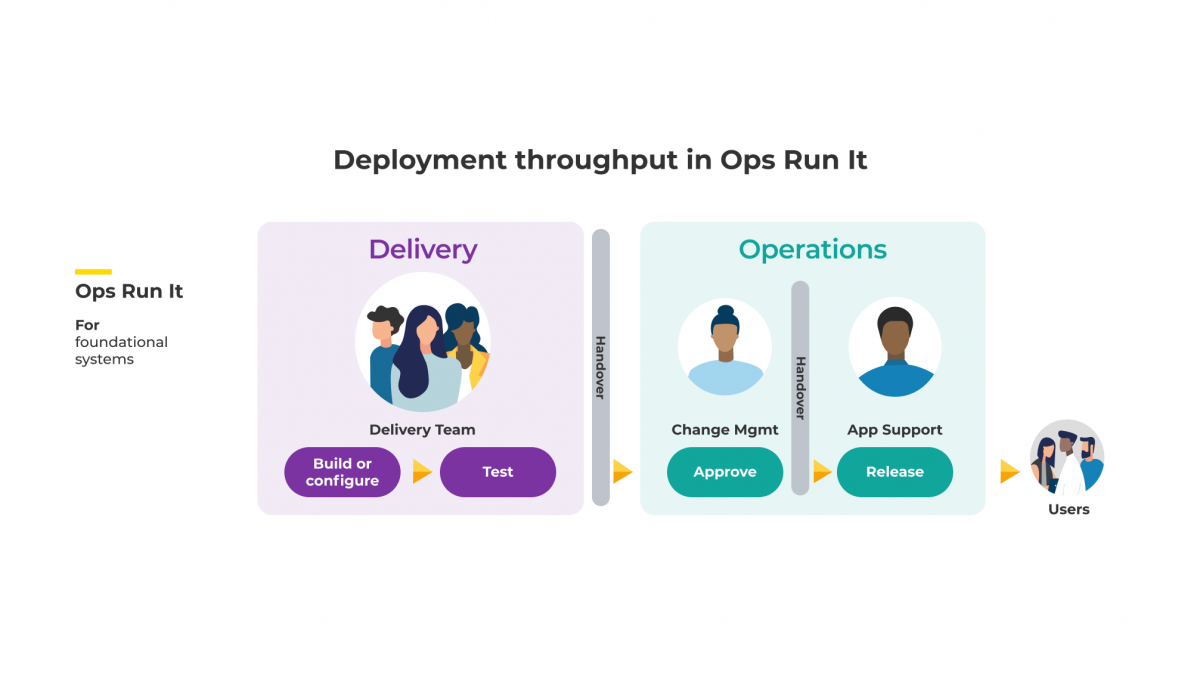
Many software teams use an operational model called ‘Ops Run It’. In this model, Operations teams are charged with the responsibility of deploying and supporting applications in production. The above graphic highlights a composite IT department, where Delivery and Operations function as silos.
In this approach there are many delivery teams building and testing software services. Once those services are built and tested, there’s a handover. In Operations, there’s a Change Management team running change-advisory board meetings (or CAB meetings) to ensure the services are stable and safe. Then, there’s an App Support Team doing the deployments.
How does ‘Ops Run It’ work in a day-to-day capacity?
- The Delivery team adds a delivery request into the change-management queue.
- Each delivery request is approved or rejected in a CAB meeting.
- An approved change is added into the deployment queue.
- The Application Support team perform the actual deployment at the scheduled time.
- Post-deployment validation testing will be performed by either the Operations App Support team or, in some cases, the Delivery team.
What are the drawbacks in this approach?
- It’s incredibly slow to approve a change request: in this operating model, deployments are mired in bureaucracy because it takes hours, days, or even weeks to approve a change.
- The act of deployment itself is slow-to-complete: it can take hours or days to actually complete deployment. Additionally, if the deployment tasks are not automated, the act of deployment can be risky and time consuming. In some cases, the architecture itself may prevent teams from being able to make changes while the system is running. This means all deployments must be timed to correlate with planned outages. If the team does not have automated production verification tests, then testing must be completed manually after each deployment. All of these factors—whether individually or in conjunction—can contribute to lengthy deployment times.
- It’s slow to synchronize knowledge between teams during handovers: every time the delivery team completes a piece of work, they need to conduct a handover process to pass the deliverable to Operations for approval and deployment. This involves a detailed summary of what was built, why it was built a specific way, and anything to be mindful of in support cases. Providing this context is time consuming and often arduous, given the Operations team was not involved in building the change and typically have very little context as to why it is important.
- You can’t sustain innovation with Ops Run It: while Ops Run It is suitable for commercial-off-the-shelf software (COTS) applications and foundational systems, it does not facilitate the rapid time-to-market required for sustained innovation. This is because it is slow to approve, implement and learn from new product features.
Deployment in You Build It You Run It: how to launch new product features to market every day.
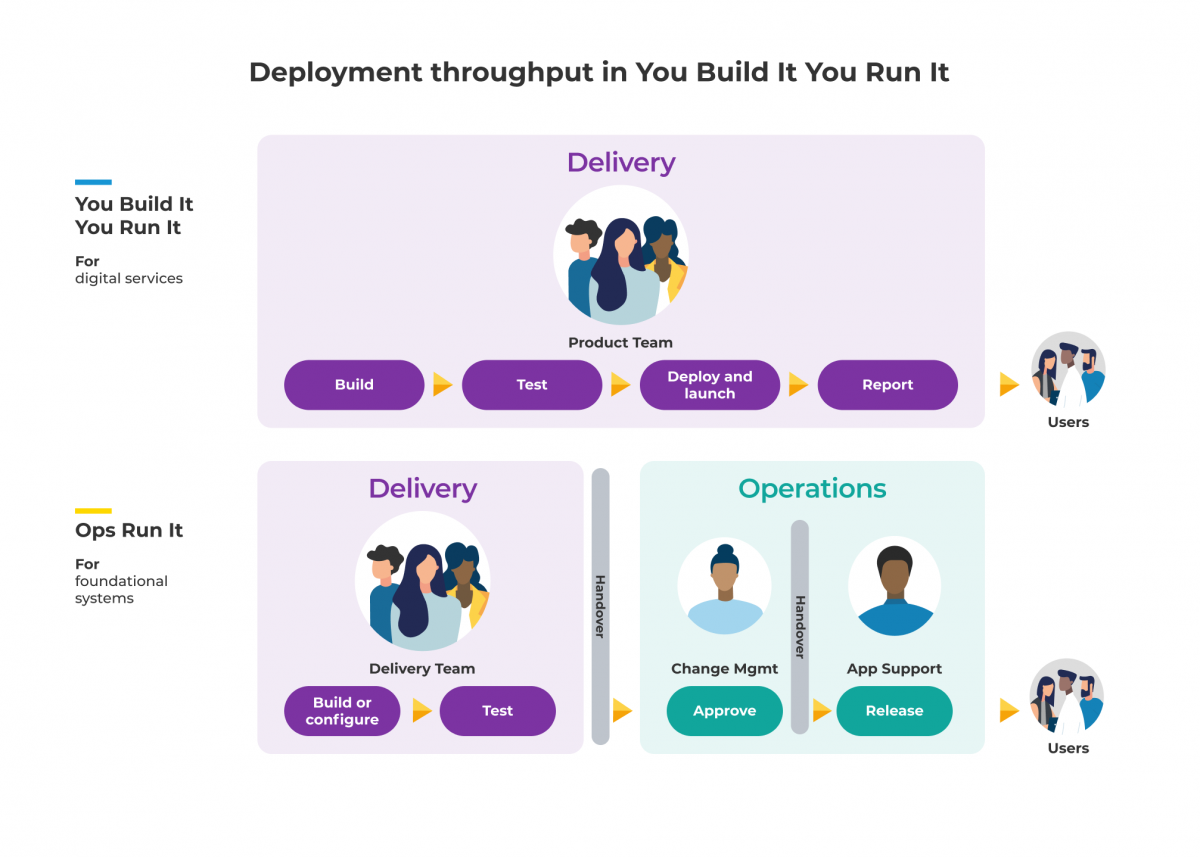
The above graphic shows a hybrid model.
It’s important to note that You Build It You Run It and Ops Run It are not binary propositions. It’s a common misconception that you can simply choose one model over the other and employ it universally. In most cases, you’ll have different models working together, because different services have different requirements. You should also frequently review your operating model depending on the maturity or lifecycle of the product/system you’re supporting.
Here, the Delivery team employs the You Build It You Run It operating model for all activity involved with developing, testing, deploying and evolving digital services.
The same Delivery team could be using an Ops Run It model—in conjunction with a central Operations team—for work associated with commercial-off-the-shelf software (COTS), foundational systems, or even mature digital products that require little intervention.
How does You Build It You Run It work in a day-to-day capacity?
In You Build It You Run It, an on-call Delivery team has total ownership over developing, deploying, monitoring and supporting digital services. As a result, there is no hand-off from Development to Operations.
The Delivery team has all the skills and context needed to do this across the entire lifecycle. It’s made possible by a loosely-coupled service-oriented architecture, and an automated deployment process.
In the You Build It You Run It operating model, the on-call product team will determine for themselves whether what they want to do is a regular, low-risk change. We trust they’re in the best position to make this call, because these team members have built the service and best understand the intricacies of its codebase.
If the Delivery team deem it is a regular low-risk change, they use a pre-approved change request process, and it’s managed by the team as a standard change. This process is extremely fast when implemented correctly—updates can be deployed daily to help organisations sustain innovation and consistently deliver value.
If the Delivery team deem it is an irregular or high-risk change, it goes through a normal CAB process with the same change-management team from Operations.
When a deployment happens, the Delivery team perform it themselves—at a time of their own choosing—and report their successful changes to the Change Management team.
Critically, this removes the bottleneck you see in Ops Run It where the Delivery team is dependent on the App Support team.
In You Build It You Run It, we also typically see Delivery teams being much more considered and cautious with their deployment times than an Operations team might be. This is because the Delivery team themselves are responsible for fixing any problems that arise from the deployment.
Often, in scenarios where deployment is automated and the architecture is built in a way that doesn’t require downtime for deployments, Delivery teams will deploy during the day to give themselves a working day to monitor for issues and implement immediate fixes as they arise. This, in turn, means fixes are provisioned faster and services are more reliable in general.
What are the benefits of this approach?
In the right environment, there are many benefits to You Build It You Run It. The top three we typically see are:
- It’s much, much faster to approve change requests: in this operating model, an approved change request for a regular low-risk change can be obtained within minutes or even immediately. As opposed to days, weeks, or months.
- It’s much, much faster to complete deployments: the deployment process can be fully automated by the Product team using the deployment pipeline. Crucially, even if you choose not to automate this process, there is no handoff to any other team as part of the deployment workflow; the team is entirely self-sufficient.
- It’s much, much faster to synchronise knowledge: there’s no requirement for meetings or phone calls to facilitate a deployment handover for an Operations team. The only requirement is to synchronise knowledge within the Product team; through an approach like paired development, everyone on the team has far greater clarity of what’s happening at any point in time.
So how do I get started with You Build It You Run It?
Like many things, You Build It You Run It can be incredibly powerful when implemented in the right context. But it’s not necessarily the right approach for every organisation universally.
If you’re interested to learn more about You Build It You Run It—including whether it’s right for you, and how you can start to determine its suitability for your team —I’d love to set up a conversation.
According to a Fortune 1000 study, a critical application failure costs an average of $500,000 to $1m per hour. Luckily, with some structural changes to the way you support digital services, you can protect against the massive consequences—for both cost and reputation—caused by unplanned downtime.
Despite contingencies and protective measures, unplanned business-critical service outages can happen to the best of us.
Just ask world-leading enterprises like Microsoft, Google, AWS and Atlassian, who’ve all recently experienced costly periods of downtime. And they are costly.
Beyond the obvious economic cost outlined above, you’ve also got to factor for:
- Loss of service and prospective revenue
- Lost productivity for development teams trying to regain service
- Customer attrition due to degraded experience
- Damage to your broader reputation via poor press and customer sentiment
You have to ask: are we doing everything possible to guard against the impact of critical outages? By structuring your team to adopt the You Build It You Run It operating model, you can add a crucial layer of protections and promote greater service reliability, while accessing a huge range of other valuable benefits.
So, let’s look at:
- The operating model many organisations use for service reliability (called an Ops Run It approach).
- The positives and negatives of Ops Run It.
- An alternative model for service reliability, called You Build It You Run It.
- The significant benefits associated with the You Build It You Run It operating model, and some minor tradeoffs to consider.
1. ‘Ops Run It’: the model most organisations use for service reliability.
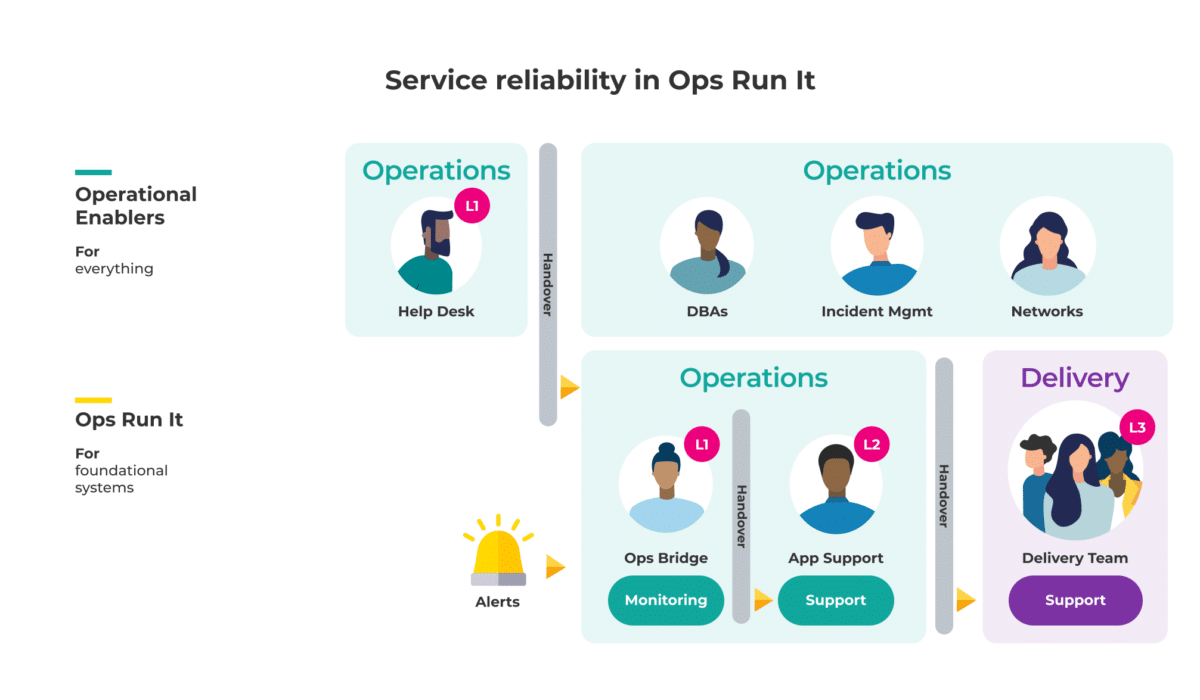
This approach to service reliability involves a tiered approach to support with hand-offs between teams:
- L1 refers to basic help-desk resolution and service delivery
- L2 refers to an application support team: personnel with deeper knowledge of the product or service, but not necessarily those who built it
- L3 refers to expert product and service support: highly skilled product specialists, which may include the architects or engineers who built the service in question.
In the above diagram, we have an L1 Operations Bridge Team, an L2 Application Support Team, and L3 Delivery Teams. There are also ‘Operational Enablers’, who can be called on for assistance, such as incident management and database administrators (DBAs).
In my experience, the labeling of this setup can vary slightly between organisations, but the structure is fundamentally the same. For example:
- Any customer self-service functions could be classified as L0.
- The Help Desk Team could be called Customer Service.
- The Operations Bridge Team could be called the Operations Centre.
- The Application Support team could be called Application Operations.
- The Help Desk and Operations Teams could be a single L1 team.
- The Operations Bridge and Application Support Teams could be a single L2 team.
How does this approach work in day-to-day reality?
In working hours, the App Support Team will monitor dashboards for any signs of abnormal operating conditions. Out of hours, a single team member is on call for any alerts, typically provisioned via some kind of alert system.
If an issue arises, the L1 Help Desk Team will deal with the customer complaints. The L1 Ops Bridge Team will proactively monitor the dashboards and, in theory, use customer service scripts to resolve any high-volume, straight-forward issues.
When they can’t resolve a problem, it is escalated to L2. The L2 App Support Team can modify items such as:
- Configuration
- Data
- Deployment
- Infrastructure
- Dashboards
They can use these capabilities to restore availability when there’s a production incident. But the L2 App Support Team can’t modify the service code, because it’s owned by the Delivery Teams. Any requirement for a code change is escalated to L3.
The L3 Delivery Teams will work with the L2 App Support Team on high priority incidents. These may involve emergency deployments or code changes. However, unlike the Ops Bridge and App Support Teams, L3 Developers are on-call out-of-hours, or on best-efforts only.
2. The pros and cons of using ‘Ops Run It’ for digital service reliability.
The positives:
- Low setup cost. For better or worse, Ops Run It is extremely well-established. As a result, there are many training courses and vendor tools you can use to implement it.
- Low running cost. This is because there’s one Ops Bridge team and one App Support Team supporting all services. These can be outsourced to reduce costs if required.
- Straight-forward governance. With one single Operations Manager, there’s a clear and singular point of accountability for the reliability of all your software services.
The negatives:
- Fragile architecture. In Ops Run It, Delivery teams are rarely incentivized to build operability into services as they are not responsible for the out of hours monitoring and support of the application. In other words, they rarely feel the consequences of not building operability into the digital services.. This results in digital services that are brittle, that do not gracefully degrade (i.e. do not maintain limited service or functionalities when under duress), and that are vulnerable to costly failures.
- Very little capacity for proactive protection. In an Ops Run It model, the App Support team can’t proactively enhance the operating conditions, because updating dashboards depends on changing events via the digital services. Those changes can only be provisioned by asking a Product Manager to prioritise them with the Delivery team, which forces the Ops Bridge team into being reactive rather than proactive.
- Long wait times to resolve incidents. With an Ops Run It operating model, it can take hours and possibly even days for an incident to be resolved. In working with many organisations, I’ve seen:
- 20-minute windows for Ops Bridge Analysts to pick up on alerts, refer to the on-call support roster, identify the right person, and contact them.
- Incidents bounce between different teams discussing who’s best to respond. An App Support team can’t implement code workarounds without a Delivery team; but a Delivery team can’t assist without access permissions, because in many organisations, Delivery teams don’t even have access to read-only monitoring dashboards.
If the cost of a critical service outage is $1m per hour, and it takes your Ops Bridge team 20 minutes to identify the best responder in an Ops Run It model, that’s a $300,000 cost to start rectifying the incident.
I’ve seen these drawbacks add up to millions of dollars of lost revenue during production incidents. So, surely there’s a better approach?
3. Using the You Build It You Run It model for improved digital service reliability.
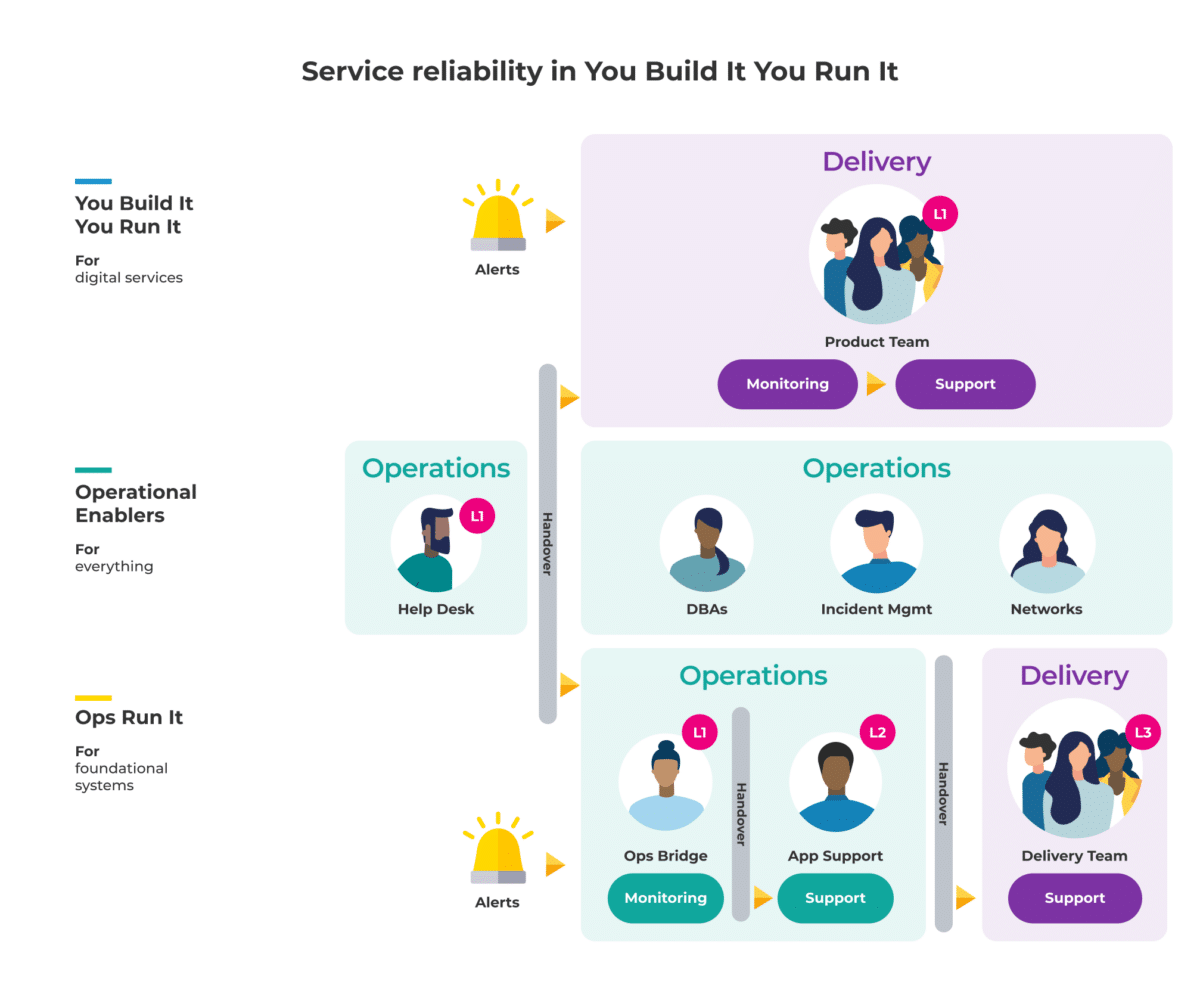
In the You Build It You Run IT approach outlined above, an on-call Product Team offers 24/7 production support. The on-call Product Team can modify all aspects of a digital service, including:
- Alert definitions
- Code
- Configuration
- Data
- Deployments
- Infrastructure definitions
- Logging
- Monitoring dashboards
In the You Build It You Run It Model, the Delivery team who built the product also provides the production support for the service. This ensures they have all the necessary context, insight, and familiarity with the codebase required to categorise issues and provision fixes rapidly, promoting a higher standard of service reliability in general.
How does this hybrid approach work in day-to-day reality?
In working hours, team engineers proactively observe their own service health checks, logs, and metrics in different dashboards. Out of hours, one of the developers is paid to be on call and on standby for any loss of availability.
If an availability target is breached, the on-call developer receives an automated alert through an incident response platform like PagerDuty. The developer acknowledges the alert, which automatically creates a ticket in a workflow system.
The developer will then diagnose the incident themselves using their own detailed knowledge, having built the digital service themselves. They can deploy any code changes needed, add any structural capacity, make any configuration changes, and do whatever else is necessary to rectify the issue in the fastest time frame possible.
4. The benefits of using You Build It You Run It for digital service reliability.
Using the You Build It You Run It model creates many, many benefits. Four of the more significant positives that typically appeal to clients are:
- Developers are incentivized to create adaptive architectures. You can read more about this concept in our You Build It You Run It Playbook. Unlike in an Ops Run It model, because developers are ‘on the hook’ to provide support themselves, we see services that are designed to gracefully degrade in the event of failure. In other words, developers create and maintain contingencies to prioritise vital functionalities even when a service is compromised. This includes things like circuit breakers, asynchronous calls rather than downstream dependencies, or toggles so that you can turn certain non-essential features off in the event of a crisis.
- You can evolve and improve proactive protection measures over time. In a You Build It You Run It operating model, the Product delivery team is able to control the monitorable events that are produced by a digital service. This is because they own every aspect of that service themselves. They can add new metrics, delete old metrics, refine metrics, add new logs, and constantly change dashboards to look at macro business metrics, as well as low-level technical metrics.
- There’s a lower number of callouts (and happier support teams). By virtue of being the support team for their own work, product teams typically remove unnecessary alerts. They eliminate low priority faults immediately as they’re found. They minimise out-of-hours call outs, because it’s in their best interest to do so.
- Significantly shorter time to resolve incidents or failures. This is because the Product Team receiving the alert have far greater knowledge of the digital service in its entirety. They have all the knowledge and tools they need at their disposal to quickly resolve a problem. I’ve seen potential revenue loss and operational costs significantly reduced by on-call product teams: incidents resolved in minutes, rather than hours. And when time is money—quite literally—every second counts.
While these benefits are significant, there is a commonly perceived drawback when implementing a You Build It You Run It operating model. In the interest of transparency, it’s worth calling this one out.
- There’s a high setup cost. Admittedly, it can take time to familiarize developers with an incident management process, to procure licenses for incident response tools, to enable production access rights for telemetry tools, and for developers to agree to that all important out-of-hours on-call schedule. (Incidentally, I recommend an engineer ideally spends about a week on-call, and three weeks off-call).
While there can be a high setup cost associated with moving to a You Build It You Run It model, think of this cost as an investment in the robustness of your models and systems moving forward.
It’s like insurance. The small amount of money you spend now protects you against–and crucially, pales in comparison to the–potential cost of a service outage if you continue in your current approach.
Again, you have to ask yourself: could you be doing more to protect against costly failures? If the answer is yes, let’s talk about whether You Build It You Run It is right for you.
You Build It You Run It accelerates your time to market, increases your service reliability, and grows a learning culture. All by empowering your product teams to own every aspect of digital service management. However, there are some pitfalls, which can put the success of You Build It You Run It at risk. One pitfall involves implementing the same reactive change management process. It creates something we like to refer to as treacle.
In our recent You Build It You Run It playbook, my co-author Bethan Timmins and I take a deeper look at the change management treacle pitfall. You can guard against it. And how you can even completely escape it.
Change management is needed
Let’s start with a little more explanation of the You Build It You Run It hybrid operating model:
- Product teams build, deploy, operate, and support their own digital services, such as user-facing microservices.
- An application support team manages foundational systems, like self-hosted COTS and custom back office applications for which there’s no equivalent SaaS or COTS.
This diagram shows how we think of deployment throughputs for digital services and foundational systems in You Build It You Run It.
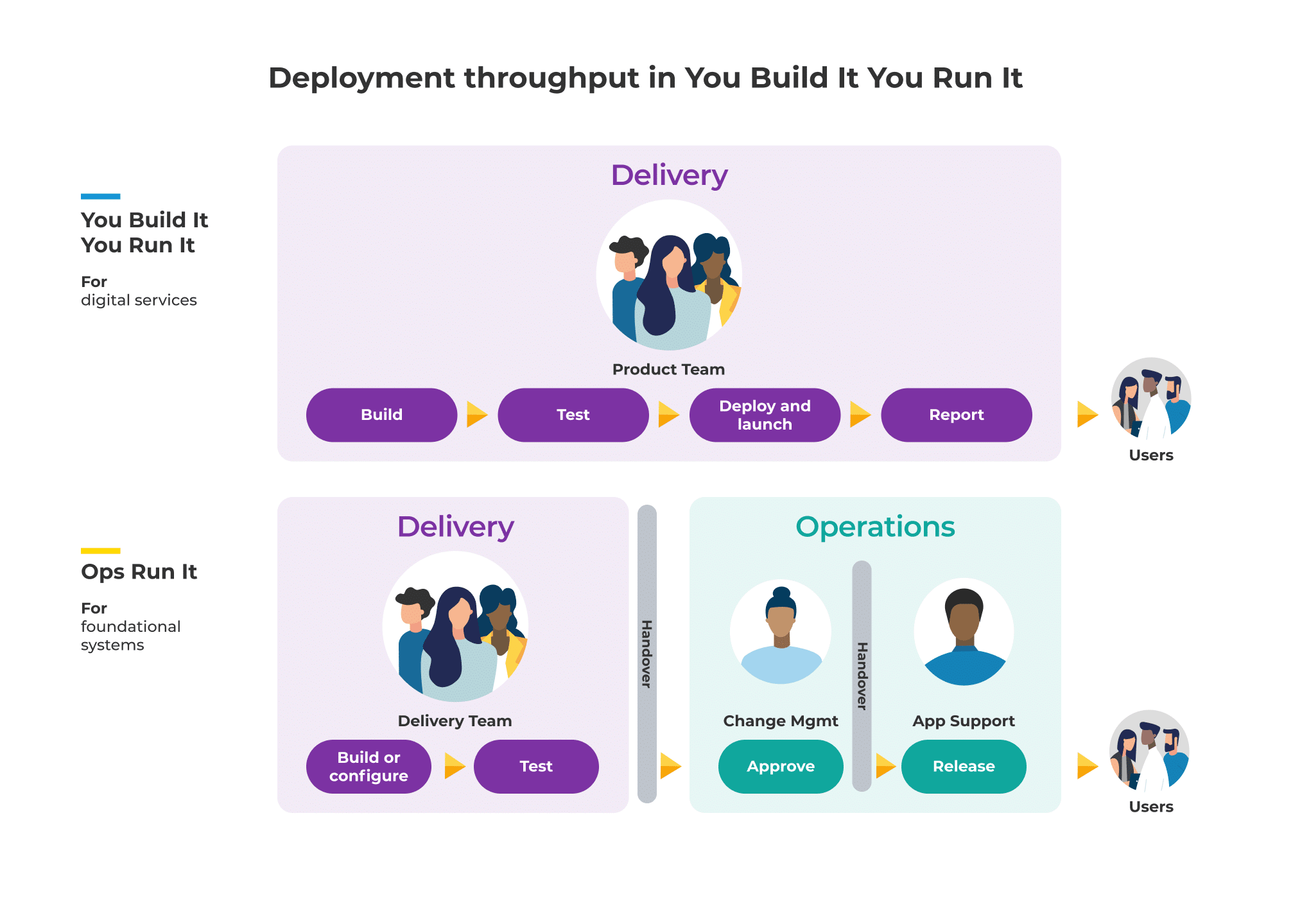
In the diagram, you can see an approval step for foundational systems, prior to the release step. The delivery team has to file a change request to the change management team, who then review the change and approve or reject it. If the change is approved, the application support team performs the production deployment.
“Our change management is too slow” is a complaint we’ve hear often. Now we all recognise the need for change management, it’s necessary for large, complex changes with lots of moving parts. It’s also important that your IT department can produce an audit trail of all production changes, to assist in incident diagnosis and to satisfy internal compliance requirements.
It’s easy to blame slow change management on ITIL. But we’ve helped plenty of organisations to implement daily deployments within ITIL parameters.
In our experience, slow change management is caused by using a heavyweight, one size fits all process. We’ve seen many organisations get stuck when they don’t make the time to rethink how to do it well. But You Build It You Run It depends on a slicker change management process, which still satisfies the needs for change approvals and auditing.
Change management treacle
Bethan and I refer to slow, heavyweight processes as treacle. You can’t move faster, because you’re stuck in sticky syrup where you are.
When you adopt You Build It You Run It, copying and pasting the same reactive change management process causes a lot of treacle. Product teams are empowered to build, test, and deploy their own digital services, but every change still has to be approved by the change management team. This causes a lot of problems:
- The change management team can’t approve changes fast enough for weekly or more frequent deployments, so product features can’t be rapidly tested with customers
- Changesets per deployment become much larger, which makes it harder to test changes and diagnose production failures when they occur
- Product teams suffer from low morale, because their hard work is often trapped in a change request queue for days at a time
- Relationships between product teams and the change management team become frayed, and resentful
This is what we call the change management treacle pitfall. It prevents you from achieving one of the key goals of You Build It You Run It – an acceleration in deployment throughput, as a means to increase product revenues, keep BAU under control, and reduce operational costs.
You need to re-implement change management for digital services and You Build It You Run It – but how?
Here are our 4 suggestions to remove the treacle
We recommend you aim for a twin-track approach to change management. This way you allow digital services to move at a faster pace than foundational systems, while allowing for change approvals and auditing. Try these practices and you will quickly see how you can cut out the treacle.
- Pre-approve low risk, repeatable changes. This is known as ‘standard changes’ in ITIL. Establish a template with your change management team for pre-approving small digital services changes, and retain the regular process for large changes to digital services or foundational systems.
- Encourage frequent, small changes. Incentivise your product teams to make their planned features and changesets as small as possible.
- Automate change auditing. Record all deployment pipeline changes in a persistent store, and create an information portal so your change management team can view ongoing changes.
- Run regular chaos days. Ensure every product team runs Chaos Days, to validate their approach to change management, deployment failures, and incident handling.
This will result in a streamlined change management process for digital services, akin to:
- Product manager creates a pre-approved change request template
- For any low risk and repeatable changes, automate filling in a pre-approved change request whenever a release candidate passes all functional tests
- For any high risk or unrepeatable change, send a change request to the change management team for approval.
- Automatically check prior to a production deployment that an approved change request exists.
- Automatically close the change request when the deployment is completed.
That’s it. It’s the most effective way we have discovered to remove your change management treacle, and allow your You Build It You Run It adoption to be successful! We hope it helps.
To find out more, you can continue our You Build It You Run It pitfalls series:
- 7 pitfalls to avoid with You Build It You Run It
- 5 ways to minimise your run costs with You Build It You Run It
- Why your head of operations shouldn’t be accountable for digital reliability
- How to manage BAU in product teams
- 4 ways to remove the treacle in change management – you are here!
Our You Build It You Run It page has loads of resources on on-call product teams – case studies, conference talks, in-depth articles, and more. Plus our You Build It You Run It playbook gives you a deep dive into how to make it happen! Get in touch, and let us know what you think.
It’s no secret that sustaining innovation is difficult for well-established organisations. By and large, they are not known as innovators. And traditional approaches to operations certainly don’t help them.
Which is why, over the years, many organisations have recognised the need to rethink how they operate their digital services. I know this because I have spent many years helping these large organisations to do this effectively.
I’m Bethan, the Managing Director of Equal Experts in Australia & New Zealand. My colleague, Steve Smith, and I have just finished a playbook on You Build It You Run It, because we want to help organisations to innovate and achieve success.
Before I tell you about the playbook, I’ll give you a little of our back story. Steve and I started in IT software development in the 1990s. At this point, there really was only one way for large organisations to operate software services. It involved multiple delivery teams building multiple services, and one operations team managing live services.
How things have changed. In recent years the emergence of Continuous Delivery, DevOps, and Site Reliability Engineering has led customers to ask us the same question.
“How do we manage the operations of our digital services now the way we build them has changed?”
They knew the traditional approach to operations was not helping them to sustain the innovation they needed. But it wasn’t clear what the alternative could be. Since 2006 there’s been talk of You Build It You Run It, but no real understanding of when, and when not, to use it – or how to implement it in large organisations. If our customers decided to adopt You Build It You Run It, we couldn’t find any references on principles to consider, practices to implement, and pitfalls to look out for.
So, Steve and I decided to combine our years of experience, the operational experiences of our customers, and the knowledge of the 2000+ people in the EE network, and publish this information as a playbook.
So why a playbook? Well, core to the values of Equal Experts is a passion for learning. We don’t pretend to know all the answers – but we are confident in our ability to find them. And when we do, we want to give our community a place to find them too.
At its core, Equal Experts is a haven where this sharing happens freely and happily between like-minded practitioners and our customers. We trade on our ability to learn and share knowledge rather than protecting or ‘guarding’ it. This is why we feel compelled to open-source our playbooks to share this knowledge as widely as possible.
We hope you enjoy reading this playbook as much as we have enjoyed creating it. We welcome your feedback and thoughts, in fact, we encourage them.