A model that fundamentally stops speed: how Ops Run It denies you huge value (part 1)
It’s a fact. Reducing time-to-market at scale is the best way to increase return on investment for digital organisations.
In a recent study conducted by Forrester, an organisation realised over $41 million of net-present value by improving time-to-market and reducing their ‘concept to cash’ timeline.
By improving the speed at which this organisation consistently delivers new features, it saw:
Significantly increased profits
A profit increase of $41.1 million from faster time-to-market
A profit increase of $19.4 million from enhanced performance of custom apps
Reduced costs
A cost reduction of $716,000 through reduced configuration time
A cost reduction of $544,000 through net revenue protection for digital applications
The two critical ingredients in unlocking this substantial value were:
Implementing Paved Roads, which increase productivity, and
adopting the You Build It You Run It operating model, which substantially improves time-to-market.
The key takeaway is this: if your organisation works in a traditional Ops Run It operating model—defined by having distinct, separate teams involved in the build (Delivery) and support (Operations) of features for a product or service—you may be denying yourself enormous value.
In this five-part series, I’ll look at five key reasons why Ops Run It could be denying you of value. They are:
Part 1: Ops Run It prioritises stability in a way that fundamentally stops you from delivering at speed (this article).
Part 2: Ops Run It involves an unnecessarily laborious and manually intensive deployment process.
Part 3: Ops Run It limits the agility of the development team, making it harder to respond to rapid changes in market conditions or evolving customer needs.
Part 4: Ops Run It involves an overly strict change management process.
Part 5: Ops Run It and potential impacts on resourcing for sustained innovation.
So, let’s look into the first reason.
Ops run it prioritises stability in a way that fundamentally stops you from delivering at speed.
In the Ops Run It model, there are no processes or methods in place to actively drive speed. In fact, teams are structured in a way that inherently compromise your ability to consistently deliver new features at pace.
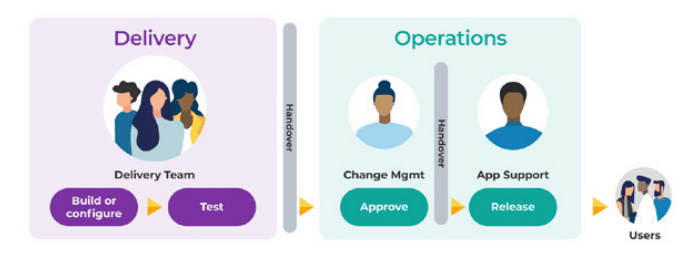
By having separate, compartmentalised teams—being segregated Delivery and Operations teams—you create a scenario where it is necessary to have gates and handovers between those teams.
The diagram above highlights a common team structure in Ops Run It, where handovers are a necessity. One handover occurs between Delivery and Operations teams, and the second occurs between Change Management and App Support teams within the Ops team.
These handovers, required for the passing of context and information between segregated teams, inherently create delays.
This structure prevents you from delivering at pace and can deny you the ability to reap huge potential profits.
Let’s consider a practical example.
Think about incident management and the way your team responds when something fails in production.
In an Ops Run It model, the Operations team is responsible for identifying and triaging incidents.
If they cannot rectify an incident, they will eventually contact the Delivery team that originally built the feature. This is known as level 3 support.
In this scenario, there are two negative implications:
The Operations team will be slower to rectify incidents than the Delivery team who built the software in the first place. This is because they are less familiar with the codebase they’ve been tasked with supporting. There is obviously a cost associated with this delay in fixing incidents.
The Operations team is solely motivated to prioritise availability. When a team is incentivised to maintain availability (or service stability) at all costs, they are not incentivised to support the rapid delivery of new features. In fact, the rapid delivery of new features can be seen as a threat to the stability of the system.
In this scenario, rapid delivery of new features can be seen as a threat to the stability of the system.
To protect their primary objective of high availability, the Operations team can over engineer the process of change.
They will attempt to safeguard the availability of the system. They likely:
Reduce the number of changes they make to the system in a given period.
Deploy changes at night to minimise impact in the event of failure.
Implement both manual and automated deployment pipelines, rather than fully automate.
Set up ‘eyes on glass’ monitoring, where people watch systems in anticipation of incidents.
Batch multiple changes into one release to reduce the number of changes (making each change more risky).
Accumulatively, these practices make it incredibly difficult for an organisation to launch innovative new features at pace. Which means you’re not delivering new value streams for your customers, which means you’re denying yourself of potential profits.
How is You Build It You Run It different?
Critically, You Build It You Run It doesn’t emphasise speed instead of stability.
There are many practices in You Build It You Run It that emphasise both speed and stability concurrently.
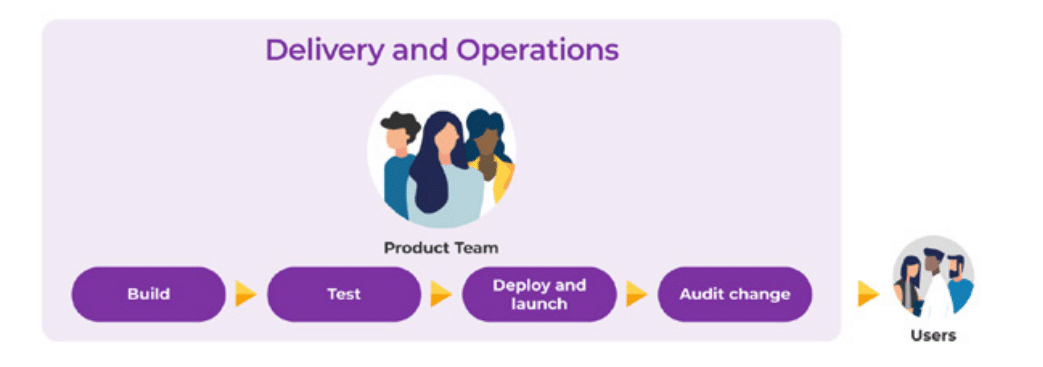
In this model, the team who builds the software then runs the software.
In contrast to the Ops Run It model, this diagram highlights the lack of handovers required in deploying changes or new features when working in the You Build It You Run It operating model.
This structure immediately creates two clear benefits:
Given the team who builds the software then runs the software, there is no requirement for time intensive handover meetings. This goes both ways; there is no onboarding involved in getting new features live, and there is no retrospective knowledge sharing required to fix an incident in production.
Because the team who builds the software is also charged with running the software in production (and are on call in the event of an incident), teams will implement proactive contingencies to remove the risk of failure. They will also ‘architect for adaptability’. This means building services that gradually shutter on failure to ensure business-critical aspects of the service can still generate value.
Teams in You Build It You Run It are able to deliver new features at a much faster rate. They are also empowered to proactively build in measures that promote higher availability.
In contrast, the Operations Team in an Ops Run It model is largely reactive. They do not get hold of new features until they are live and cannot retrospectively implement the same forward-thinking protections that are possible when developing the feature.
You Build It You Run It also supports the ability for teams to implement continuous delivery and continuous deployment, which is impossible to adopt in an Ops Run It model. This provides an additional range of benefits for fast, safe, and reliable delivery.
Ops Run It can deliver value in the right context.
This is not intended as a sweeping criticism of Ops Run It.
Importantly, it’s worth pointing out that Ops Run It is an entirely valid operating model. In scenarios where speed-to-market isn’t a factor, Ops Run It can often be the right approach.
The issue is that many businesses run into the costly pitfalls of going ‘all in’.
If you’re looking to assess the operating model for your needs, or you’d like to know more about unlocking value by implementing You Build It You Run It, let’s arrange a conversation.
Discover how our You Build It You Run It playbook can help you to manage operations, innovate and achieve success
Blog
Discover how our You Build It You Run It playbook can help you to manage operations, innovate and achieve success
Blog
Five ways to ensure your team is motivated to embrace You Build It You Run It
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.