How to save millions and protect against the cost of unplanned downtime for digital services
According to a Fortune 1000 study, a critical application failure costs an average of $500,000 to $1m per hour. Luckily, with some structural changes to the way you support digital services, you can protect against the massive consequences—for both cost and reputation—caused by unplanned downtime.
Despite contingencies and protective measures, unplanned business-critical service outages can happen to the best of us.
Just ask world-leading enterprises like Microsoft, Google, AWS and Atlassian, who’ve all recently experienced costly periods of downtime. And they are costly.
Beyond the obvious economic cost outlined above, you’ve also got to factor for:
Loss of service and prospective revenue
Lost productivity for development teams trying to regain service
Customer attrition due to degraded experience
Damage to your broader reputation via poor press and customer sentiment
You have to ask: are we doing everything possible to guard against the impact of critical outages? By structuring your team to adopt the You Build It You Run It operating model, you can add a crucial layer of protections and promote greater service reliability, while accessing a huge range of other valuable benefits.
So, let’s look at:
The operating model many organisations use for service reliability (called an Ops Run It approach).
The positives and negatives of Ops Run It.
An alternative model for service reliability, called You Build It You Run It.
The significant benefits associated with the You Build It You Run It operating model, and some minor tradeoffs to consider.
1. ‘Ops Run It’: the model most organisations use for service reliability.
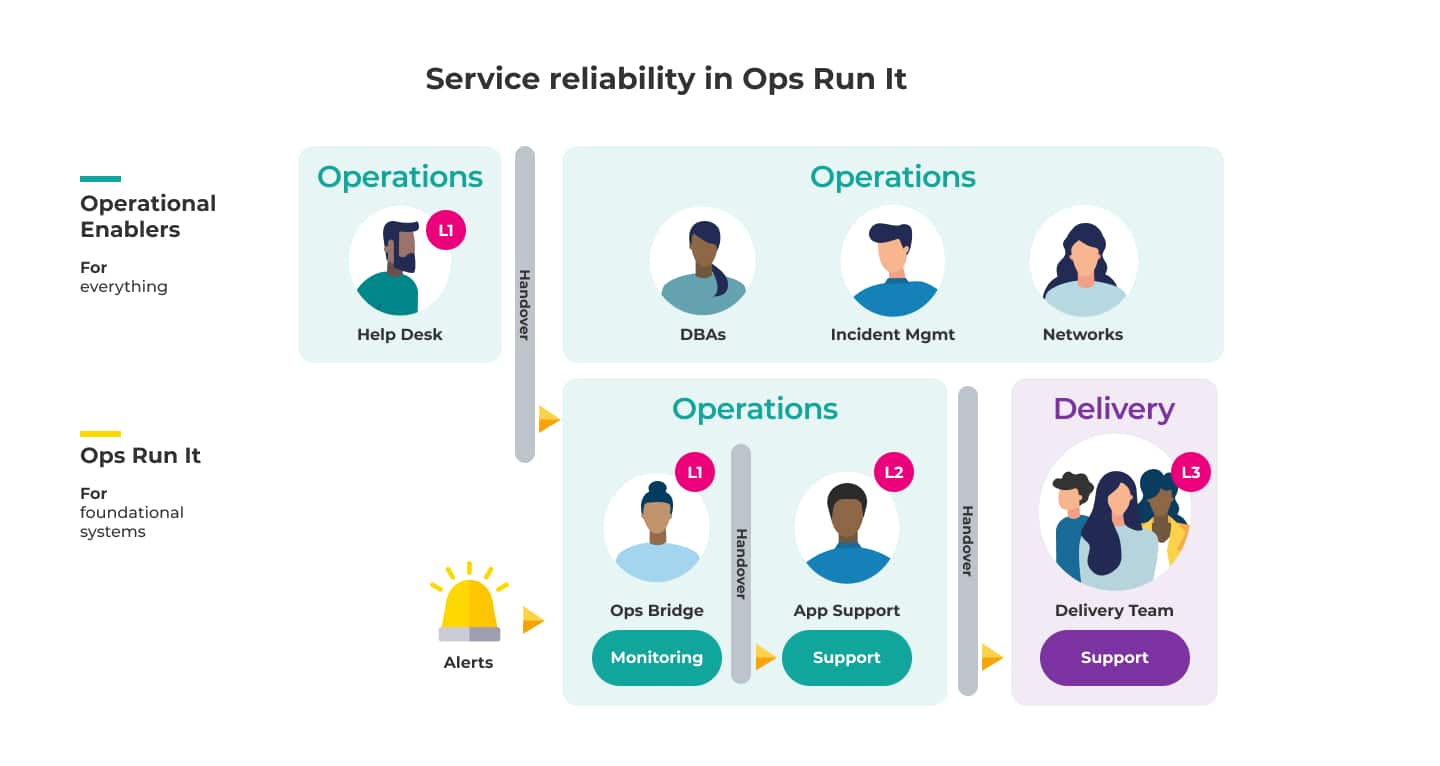
This approach to service reliability involves a tiered approach to support with hand-offs between teams:
L1 refers to basic help-desk resolution and service delivery
L2 refers to an application support team: personnel with deeper knowledge of the product or service, but not necessarily those who built it
L3 refers to expert product and service support: highly skilled product specialists, which may include the architects or engineers who built the service in question.
In the above diagram, we have an L1 Operations Bridge Team, an L2 Application Support Team, and L3 Delivery Teams. There are also ‘Operational Enablers’, who can be called on for assistance, such as incident management and database administrators (DBAs).
In my experience, the labeling of this setup can vary slightly between organisations, but the structure is fundamentally the same. For example:
Any customer self-service functions could be classified as L0.
The Help Desk Team could be called Customer Service.
The Operations Bridge Team could be called the Operations Centre.
The Application Support team could be called Application Operations.
The Help Desk and Operations Teams could be a single L1 team.
The Operations Bridge and Application Support Teams could be a single L2 team.
How does this approach work in day-to-day reality?
In working hours, the App Support Team will monitor dashboards for any signs of abnormal operating conditions. Out of hours, a single team member is on call for any alerts, typically provisioned via some kind of alert system.
If an issue arises, the L1 Help Desk Team will deal with the customer complaints. The L1 Ops Bridge Team will proactively monitor the dashboards and, in theory, use customer service scripts to resolve any high-volume, straight-forward issues.
When they can’t resolve a problem, it is escalated to L2. The L2 App Support Team can modify items such as:
Configuration
Data
Deployment
Infrastructure
Dashboards
They can use these capabilities to restore availability when there’s a production incident. But the L2 App Support Team can’t modify the service code, because it’s owned by the Delivery Teams. Any requirement for a code change is escalated to L3.
The L3 Delivery Teams will work with the L2 App Support Team on high priority incidents. These may involve emergency deployments or code changes. However, unlike the Ops Bridge and App Support Teams, L3 Developers are on-call out-of-hours, or on best-efforts only.
2. The pros and cons of using ‘Ops Run It’ for digital service reliability.
The positives:
Low setup cost. For better or worse, Ops Run It is extremely well-established. As a result, there are many training courses and vendor tools you can use to implement it.
Low running cost. This is because there’s one Ops Bridge team and one App Support Team supporting all services. These can be outsourced to reduce costs if required.
Straight-forward governance. With one single Operations Manager, there’s a clear and singular point of accountability for the reliability of all your software services.
The negatives:
Fragile architecture. In Ops Run It, Delivery teams are rarely incentivized to build operability into services as they are not responsible for the out of hours monitoring and support of the application. In other words, they rarely feel the consequences of not building operability into the digital services.. This results in digital services that are brittle, that do not gracefully degrade (i.e. do not maintain limited service or functionalities when under duress), and that are vulnerable to costly failures.
Very little capacity for proactive protection. In an Ops Run It model, the App Support team can’t proactively enhance the operating conditions, because updating dashboards depends on changing events via the digital services. Those changes can only be provisioned by asking a Product Manager to prioritise them with the Delivery team, which forces the Ops Bridge team into being reactive rather than proactive.
Long wait times to resolve incidents. With an Ops Run It operating model, it can take hours and possibly even days for an incident to be resolved. In working with many organisations, I’ve seen:
20-minute windows for Ops Bridge Analysts to pick up on alerts, refer to the on-call support roster, identify the right person, and contact them.
Incidents bounce between different teams discussing who’s best to respond. An App Support team can’t implement code workarounds without a Delivery team; but a Delivery team can’t assist without access permissions, because in many organisations, Delivery teams don’t even have access to read-only monitoring dashboards.
If the cost of a critical service outage is $1m per hour, and it takes your Ops Bridge team 20 minutes to identify the best responder in an Ops Run It model, that’s a $300,000 cost to start rectifying the incident.
I’ve seen these drawbacks add up to millions of dollars of lost revenue during production incidents. So, surely there’s a better approach?
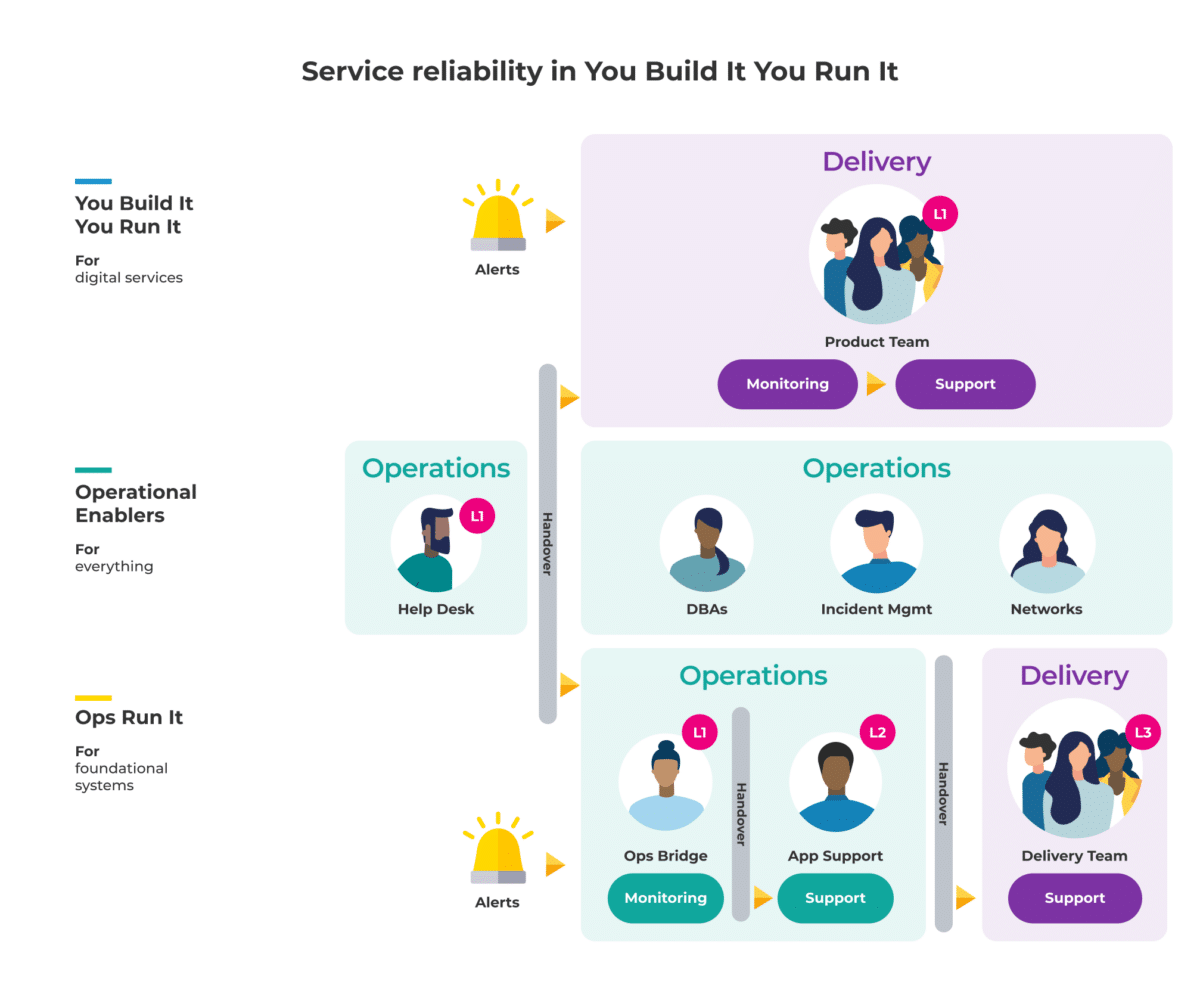
3. Using the You Build It You Run It model for improved digital service reliability.
In the You Build It You Run IT approach outlined above, an on-call Product Team offers 24/7 production support. The on-call Product Team can modify all aspects of a digital service, including:
Alert definitions
Code
Configuration
Data
Deployments
Infrastructure definitions
Logging
Monitoring dashboards
In the You Build It You Run It Model, the Delivery team who built the product also provides the production support for the service. This ensures they have all the necessary context, insight, and familiarity with the codebase required to categorise issues and provision fixes rapidly, promoting a higher standard of service reliability in general.
How does this hybrid approach work in day-to-day reality?
In working hours, team engineers proactively observe their own service health checks, logs, and metrics in different dashboards. Out of hours, one of the developers is paid to be on call and on standby for any loss of availability.
If an availability target is breached, the on-call developer receives an automated alert through an incident response platform like PagerDuty. The developer acknowledges the alert, which automatically creates a ticket in a workflow system.
The developer will then diagnose the incident themselves using their own detailed knowledge, having built the digital service themselves. They can deploy any code changes needed, add any structural capacity, make any configuration changes, and do whatever else is necessary to rectify the issue in the fastest time frame possible.
4. The benefits of using You Build It You Run It for digital service reliability.
Using the You Build It You Run It model creates many, many benefits. Four of the more significant positives that typically appeal to clients are:
Developers are incentivized to create adaptive architectures. You can read more about this concept in our You Build It You Run It Playbook. Unlike in an Ops Run It model, because developers are ‘on the hook’ to provide support themselves, we see services that are designed to gracefully degrade in the event of failure. In other words, developers create and maintain contingencies to prioritise vital functionalities even when a service is compromised. This includes things like circuit breakers, asynchronous calls rather than downstream dependencies, or toggles so that you can turn certain non-essential features off in the event of a crisis.
You can evolve and improve proactive protection measures over time. In a You Build It You Run It operating model, the Product delivery team is able to control the monitorable events that are produced by a digital service. This is because they own every aspect of that service themselves. They can add new metrics, delete old metrics, refine metrics, add new logs, and constantly change dashboards to look at macro business metrics, as well as low-level technical metrics.
There’s a lower number of callouts (and happier support teams). By virtue of being the support team for their own work, product teams typically remove unnecessary alerts. They eliminate low priority faults immediately as they’re found. They minimise out-of-hours call outs, because it’s in their best interest to do so.
Significantly shorter time to resolve incidents or failures. This is because the Product Team receiving the alert have far greater knowledge of the digital service in its entirety. They have all the knowledge and tools they need at their disposal to quickly resolve a problem. I’ve seen potential revenue loss and operational costs significantly reduced by on-call product teams: incidents resolved in minutes, rather than hours. And when time is money—quite literally—every second counts.
While these benefits are significant, there is a commonly perceived drawback when implementing a You Build It You Run It operating model. In the interest of transparency, it’s worth calling this one out.
There’s a high setup cost. Admittedly, it can take time to familiarize developers with an incident management process, to procure licenses for incident response tools, to enable production access rights for telemetry tools, and for developers to agree to that all important out-of-hours on-call schedule. (Incidentally, I recommend an engineer ideally spends about a week on-call, and three weeks off-call).
While there can be a high setup cost associated with moving to a You Build It You Run It model, think of this cost as an investment in the robustness of your models and systems moving forward.
It’s like insurance. The small amount of money you spend now protects you against–and crucially, pales in comparison to the–potential cost of a service outage if you continue in your current approach.
Again, you have to ask yourself: could you be doing more to protect against costly failures? If the answer is yes, let’s talk about whether You Build It You Run It is right for you.
You may also like
Blog
Supporting Austrade to embrace world-class data practice
Blog
Six Fundamental MLOps Principles – and how to apply them
Blog
Equal Experts will become 100% employee owned in 2025
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.