
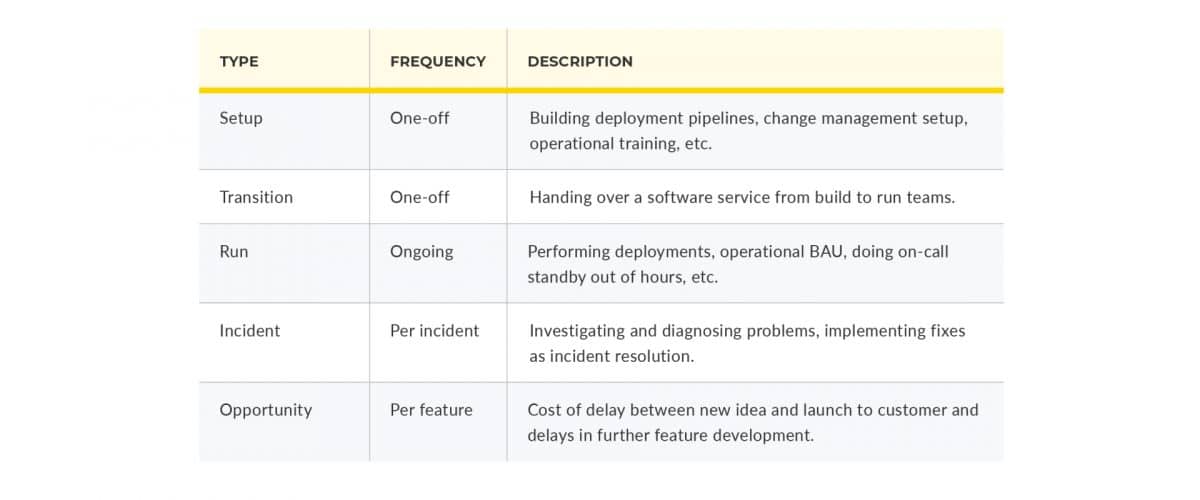
4 ways to remove the treacle in change management
You Build It You Run It accelerates your time to market, increases your service reliability, and grows a learning culture. All by empowering your product teams to own every aspect of digital service management. However, there are some pitfalls, which can put the success of You Build It You Run It at risk. One pitfall involves implementing the same reactive change management process. It creates something we like to refer to as treacle.
In our recent You Build It You Run It playbook, my co-author Bethan Timmins and I take a deeper look at the change management treacle pitfall. You can guard against it. And how you can even completely escape it.
Change management is needed
Let’s start with a little more explanation of the You Build It You Run It hybrid operating model:
- Product teams build, deploy, operate, and support their own digital services, such as user-facing microservices.
- An application support team manages foundational systems, like self-hosted COTS and custom back office applications for which there’s no equivalent SaaS or COTS.
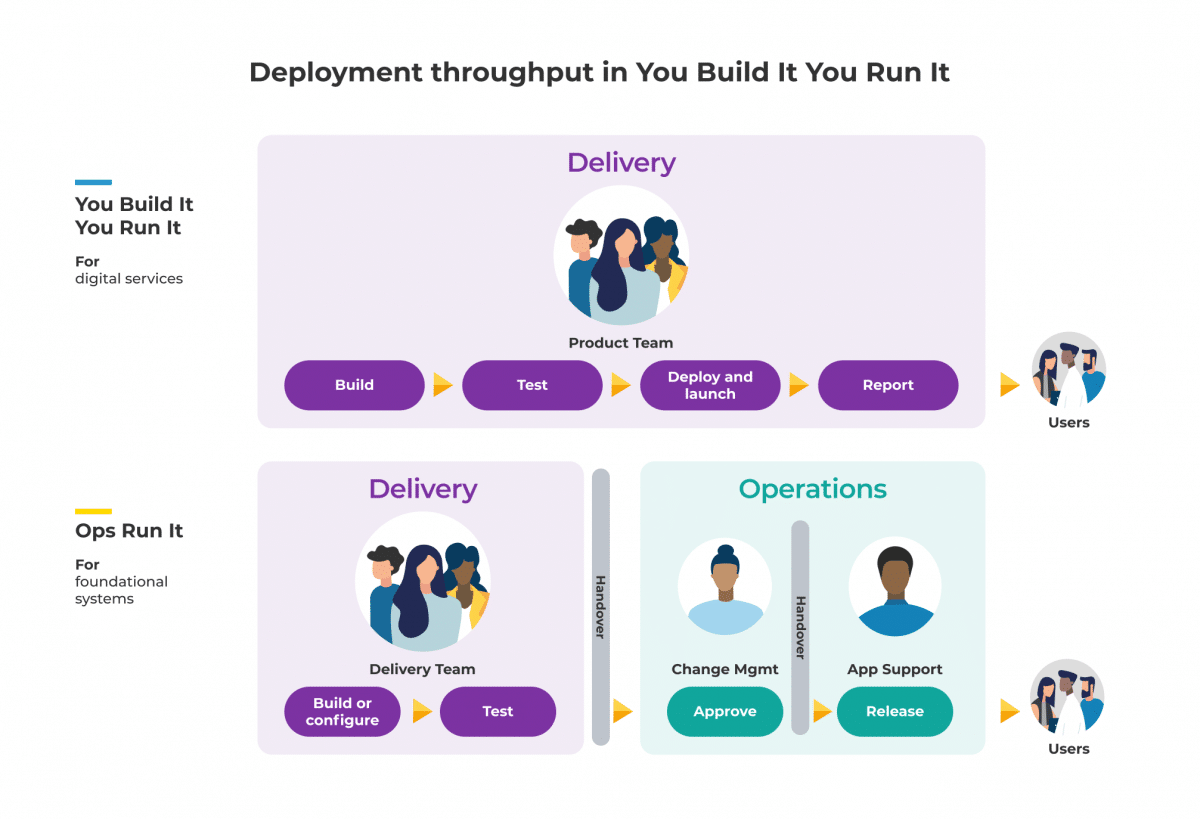
This diagram shows how we think of deployment throughputs for digital services and foundational systems in You Build It You Run It.
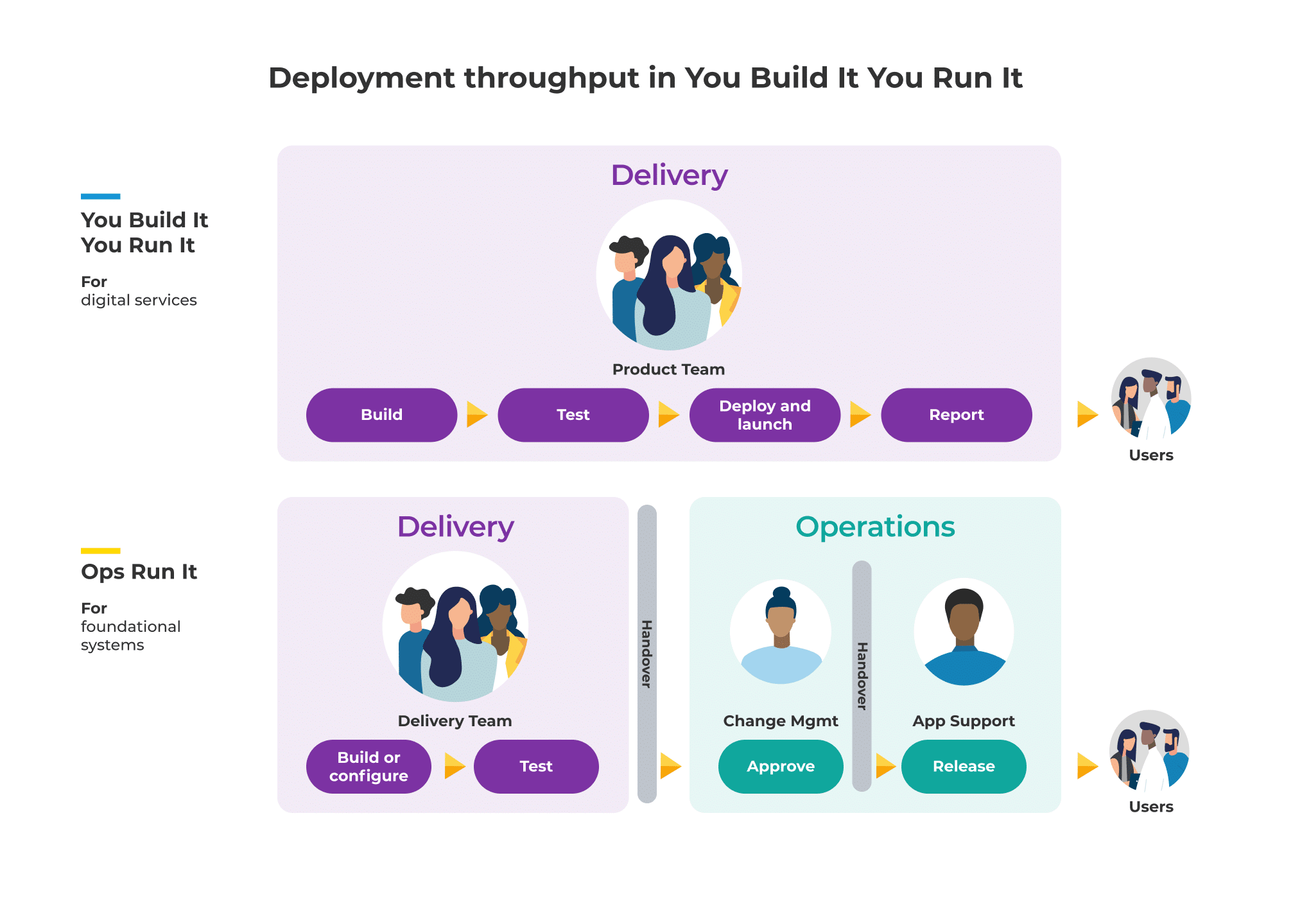
In the diagram, you can see an approval step for foundational systems, prior to the release step. The delivery team has to file a change request to the change management team, who then review the change and approve or reject it. If the change is approved, the application support team performs the production deployment.
“Our change management is too slow” is a complaint we’ve hear often. Now we all recognise the need for change management, it’s necessary for large, complex changes with lots of moving parts. It’s also important that your IT department can produce an audit trail of all production changes, to assist in incident diagnosis and to satisfy internal compliance requirements.
It’s easy to blame slow change management on ITIL. But we’ve helped plenty of organisations to implement daily deployments within ITIL parameters.
In our experience, slow change management is caused by using a heavyweight, one size fits all process. We’ve seen many organisations get stuck when they don’t make the time to rethink how to do it well. But You Build It You Run It depends on a slicker change management process, which still satisfies the needs for change approvals and auditing.
Change management treacle
Bethan and I refer to slow, heavyweight processes as treacle. You can’t move faster, because you’re stuck in sticky syrup where you are.
When you adopt You Build It You Run It, copying and pasting the same reactive change management process causes a lot of treacle. Product teams are empowered to build, test, and deploy their own digital services, but every change still has to be approved by the change management team. This causes a lot of problems:
- The change management team can’t approve changes fast enough for weekly or more frequent deployments, so product features can’t be rapidly tested with customers
- Changesets per deployment become much larger, which makes it harder to test changes and diagnose production failures when they occur
- Product teams suffer from low morale, because their hard work is often trapped in a change request queue for days at a time
- Relationships between product teams and the change management team become frayed, and resentful
This is what we call the change management treacle pitfall. It prevents you from achieving one of the key goals of You Build It You Run It – an acceleration in deployment throughput, as a means to increase product revenues, keep BAU under control, and reduce operational costs.
You need to re-implement change management for digital services and You Build It You Run It – but how?
Here are our 4 suggestions to remove the treacle
We recommend you aim for a twin-track approach to change management. This way you allow digital services to move at a faster pace than foundational systems, while allowing for change approvals and auditing. Try these practices and you will quickly see how you can cut out the treacle.
- Pre-approve low risk, repeatable changes. This is known as ‘standard changes’ in ITIL. Establish a template with your change management team for pre-approving small digital services changes, and retain the regular process for large changes to digital services or foundational systems.
- Encourage frequent, small changes. Incentivise your product teams to make their planned features and changesets as small as possible.
- Automate change auditing. Record all deployment pipeline changes in a persistent store, and create an information portal so your change management team can view ongoing changes.
- Run regular chaos days. Ensure every product team runs Chaos Days, to validate their approach to change management, deployment failures, and incident handling.
This will result in a streamlined change management process for digital services, akin to:
- Product manager creates a pre-approved change request template
- For any low risk and repeatable changes, automate filling in a pre-approved change request whenever a release candidate passes all functional tests
- For any high risk or unrepeatable change, send a change request to the change management team for approval.
- Automatically check prior to a production deployment that an approved change request exists.
- Automatically close the change request when the deployment is completed.
That’s it. It’s the most effective way we have discovered to remove your change management treacle, and allow your You Build It You Run It adoption to be successful! We hope it helps.
To find out more, you can continue our You Build It You Run It pitfalls series:
- 7 pitfalls to avoid with You Build It You Run It
- 5 ways to minimise your run costs with You Build It You Run It
- Why your head of operations shouldn’t be accountable for digital reliability
- How to manage BAU in product teams
- 4 ways to remove the treacle in change management – you are here!
Our You Build It You Run It page has loads of resources on on-call product teams – case studies, conference talks, in-depth articles, and more. Plus our You Build It You Run It playbook gives you a deep dive into how to make it happen! Get in touch, and let us know what you think.
You Build It You Run It operating model is a powerful tool. It empowers product teams to own every aspect of digital service management. This has a number of positive impacts. It accelerates your time to market, increases your service reliability, and grows a learning culture.
However there are some pitfalls which, if not addressed, can drain the confidence of your senior leadership, and ultimately put the success of You Build It You Run It at risk.
In our recent You Build It You Run It playbook, my co-author Steve Smith and I take a deeper look at the BAU pitfall, and the risk of unplanned maintenance work becoming uncontrollable. You can guard against this pitfall. In fact, you can escape it completely, by following these four simple rules.
BAU as unplanned maintenance work
We see the expression BAU (Business as Usual) used a lot. It’s usually a synonym for ‘unplanned maintenance work’, and includes:
- Infrastructure capacity upgrades
- Defect fixes
- Security patches
- Telemetry improvements
- Support tickets, resulting from live incidents
- Minor changes to existing features, due to customer feedback
If you work in an enterprise organisation, and you haven’t adopted You Build It You Run It yet, I’m guessing there’s plenty of BAU. And it causes a these problems:
- Delays to planned work. The more unplanned BAU work you take on, the slower your planned product work will be.
- Risk of reliability problems. The more unplanned BAU work you defer, the higher the risk of production incidents because of the lack of maintenance.
- Low team morale. The more BAU unplanned work you have, the greater the perception that teams are slow delivering planned work. This usually happens because unplanned work (to keep the lights on) isn’t easily visible, and can start teams on the negative spiral of a reactive learning culture.
If you are considering implementing You Build It You Run It, there’s an understandable worry amongst senior leaders. Surely, putting engineers on-call will delay planned work, because engineers will spend their time fixing live maintenance issues? The truth is, it really doesn’t have to be the case. As long as you avoid this important pitfall.
The excessive BAU pitfall
When you adopt You Build It You Run It, your product teams are on-call and responsible for running their own digital services. They already face a lot of BAU in managing their own infrastructure upgrades, applying defect fixes and security patches, and refining the telemetry toolchain. This happens when:
- Digital services aren’t designed to gracefully degrade on failure
- Deployments aren’t applied repeatedly and reliability in all environments
- Monitoring dashboards and alert definitions aren’t fully automated
The easiest way to spot this pitfall is to measure the amount of unplanned work faced by a product team each week. Ask them to fill out a survey of how much time they spend on planned work, each week. If the percentage starts to go down, and team members complain about excessive time spent on intermittent alerts, deployments etc. then you’re sliding into a pitfall.
That really doesn’t have to be the case. We’ve worked with organisations where on-call product teams have gradually eliminated many types of BAU, until it’s only a small amount to handle each week.
Keep product teams proactive and productive
We recommend these practices to cope with BAU:
- Rearchitect digital services for adaptability. Eliminate avoidable dependencies, soften unavoidable dependencies, create availability redundancy, and share behaviours via APIs instead of closed-source libraries.
- Create a fully automated deployment pipeline. Introduce XP development practices such as pair-programming and test-driven development, use dynamic test data to parallelise functional tests, establish zero downtime deployments, and allow a fast revert on failure.
- Establish an automated telemetry toolchain. Implement a telemetry toolchain from engineer laptop to test environments to live traffic, including a logging stack like EFK, a monitoring stack like Victoria Metrics, and an incident response platform like PagerDuty.
- Treat unplanned work as planned work. Visualise BAU work items on the team board, allocate a team member daily to complete urgent items, and measure the impact of BAU items on team progress.
Treating unplanned work as planned work sounds simple. But it needs a change in mindset, and it makes a huge difference. Tracking and prioritising BAU work items, alongside planned product features from the same backlog, ensures you’re always assigned to the most valuable work at any given time. A recent post by product evangelist John Cutler explains the consequences of not treating unplanned work as planned work.
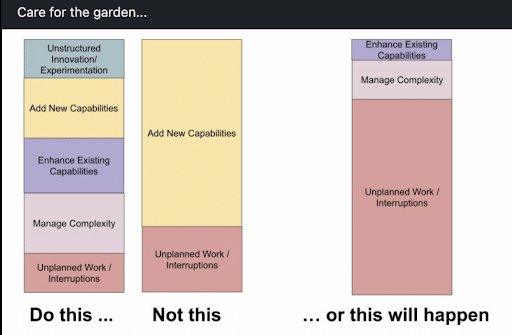
These practices aren’t quick fixes. They might require more time and money than other solutions. Don’t let that put you off. By implementing these practices, you’ll see a dramatic improvement in the amount of time a product team spends on BAU maintenance work. This frees up time to work on product delivery, by adding more capabilities and also having more time for unstructured innovation. And we all know, the truth is you’ve got to stay on top of BAU, at all times.
If you’d like to find out more, you can continue our You Build It You Run It pitfalls series:
-
- 7 pitfalls to avoid with You Build It You Run It
- 5 ways to minimise your run costs with You Build It You Run It
- Why your operations manager shouldn’t be accountable for digital reliability
- How to manage BAU in product teams – you are here!
- 4 ways to remove the treacle in change management
- Why product teams still need major incident management
- Stop trying to embed specialists in every product team
- How to avoid developer burnout on call
Our You Build It You Run It page has loads of resources on on-call product teams – case studies, conference talks, in-depth articles, and more. Plus our You Build It You Run It playbook gives you a deep dive into how to make it happen! Get in touch, and let us know what you think.
The You Build It You Run It operating model empowers product teams to own every aspect of digital service management. When done well, it accelerates your time to market, increases service reliability, and grows a learning culture.
But, as with any operating model, there are pitfalls that need to be avoided. Because if they aren’t, they will drain the confidence of your senior leadership, and ultimately put the success of You Build It You Run It at risk.
In our recent You Build It You Run It playbook, my co-author Steve Smith and I take a deeper look at an accountability pitfall, and product teams lacking strong reliability incentives. Here we take a look at this further, to consider how you can guard against this pitfall, and escape it if necessary.
No responsibilities means weak incentives
We think of You Build It You Run It as a hybrid operating model. Product teams build, deploy, operate, and support their own digital services, such as user-facing microservices. An application support team manages foundational systems, like self-hosted COTS and custom back office applications.
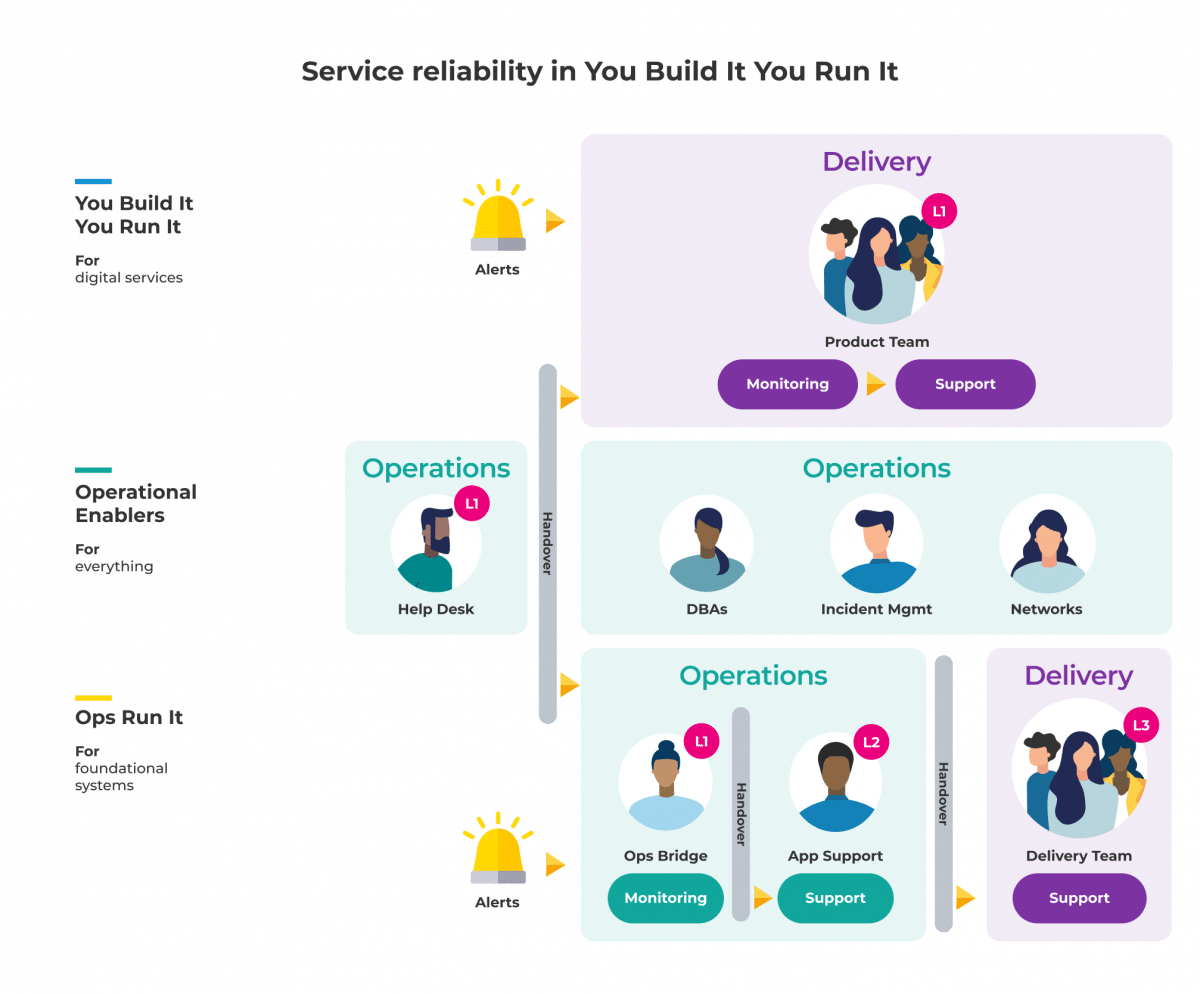
If you work in an enterprise organisation, and you haven’t adopted You Build It You Run It yet, I’ll bet your Head of Operations is accountable for the reliability of all your digital services and foundational systems. You’ve probably got a RACI model to show who’s responsible, accountable, consulted, and informed for service reliability. It’ll look like this:
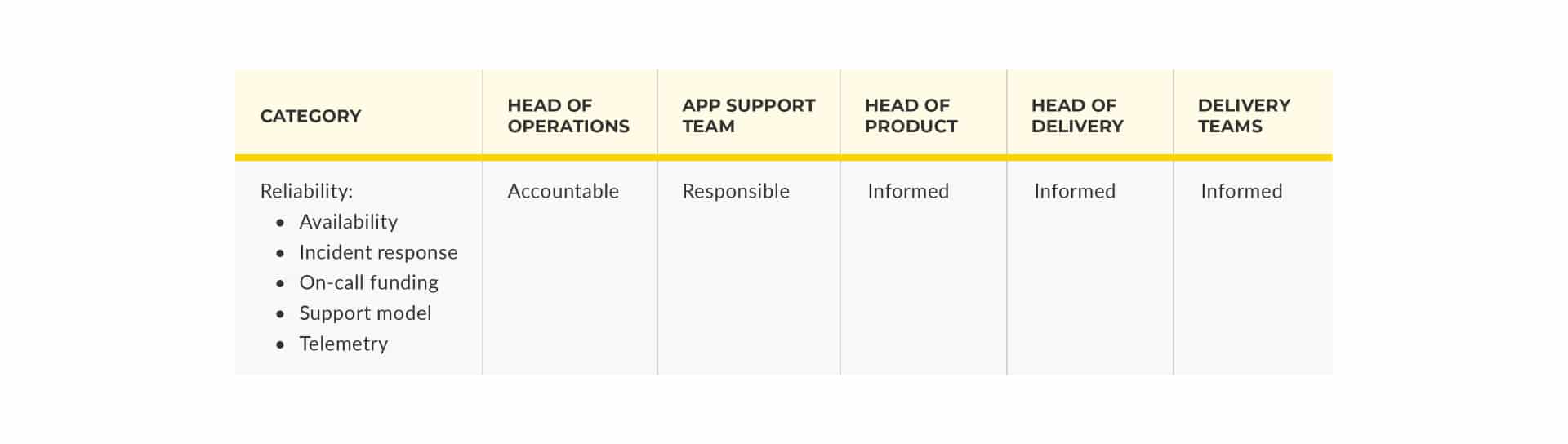
This causes plenty of problems for digital services. For the purpose of this article, I’ll focus on:
- Fragile architectures. Your digital services have a large blast radius, and an inability to gracefully degrade on failure. You’re exposed to multi-hour, multi-million $ outages.
- Inflated availability targets. Your Digital services have higher targets than necessary, and require excessive toil to meet those targets. You spend too much $ on BAU work.
This happens because your well-intentioned delivery teams aren’t responsible, let alone accountable, for the reliability, or run cost, of the digital services they build. Teams lack the operability incentives to prioritise operational features alongside product features, or to balance availability targets with on-call costs.
These problems can be hard to spot, until you suffer a major incident. Then they become hard to ignore. In our You Build It You Run It playbook we describe one customer losing $1.5M in a 5 hour outage, because a series of cascading failures were triggered by someone typing in the wrong character.
You Build It You Run It solves these problems by making product teams accountable, not just responsible, for the reliability of their digital services. But you also need to know that some of our customers have experienced an accountability pitfall along the way.
The responsible but unaccountable pitfall
When you adopt You Build It You Run It, your product teams are on-call and responsible for running their own digital services. However, your senior leadership might want your Head of Operations to remain accountable for all live services. Your RACI becomes:
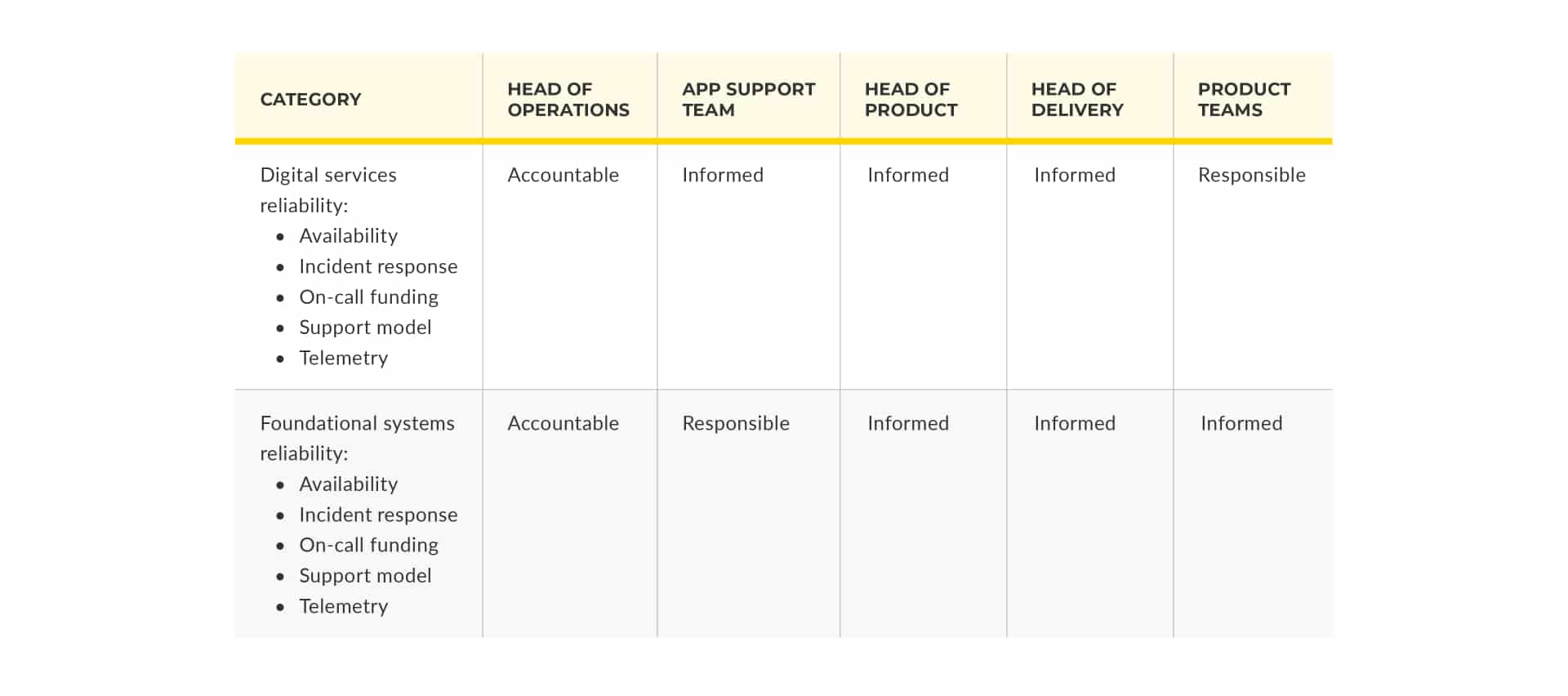
Steve and I call this the responsible but unaccountable pitfall. Your product teams feel some responsibility for reliability and run cost, which is really important. However, in at least some of your product teams, you’ll still see fragile architectures and inflated availability targets. Your operability incentives aren’t as strong as they could be, because product teams aren’t held to account for failures or run cost. This can be mitigated if your Head of Operations is extremely supportive of You Build It You Run It, but that’s pretty rare.
If you want your product teams to consistently achieve 99.0% – 99.99% availability, a time to restore that’s measured in minutes rather than hours, and an appropriate run cost, you need to change your organisational culture. Your teams must own and learn from the consequences of their decisions. Your senior leadership must empower your Head of Operations to reassign their accountabilities for digital services – but to who?
Make your product team budget holders accountable for digital outcomes
Assuming you have separate Product and IT departments, you’ve got two product team budget holders, responsible for two different capex budgets:
- Your Head of Product funds digital services that are new propositions.
- Your Head of Delivery funds digital services that are technology upgrades.
Your Head of Operations needs to split their accountabilities for digital services between your Head of Product and Head of Delivery. That way, the person paying for the digital service is responsible for its reliability and run cost, as well as its feature set. This means your RACI is:
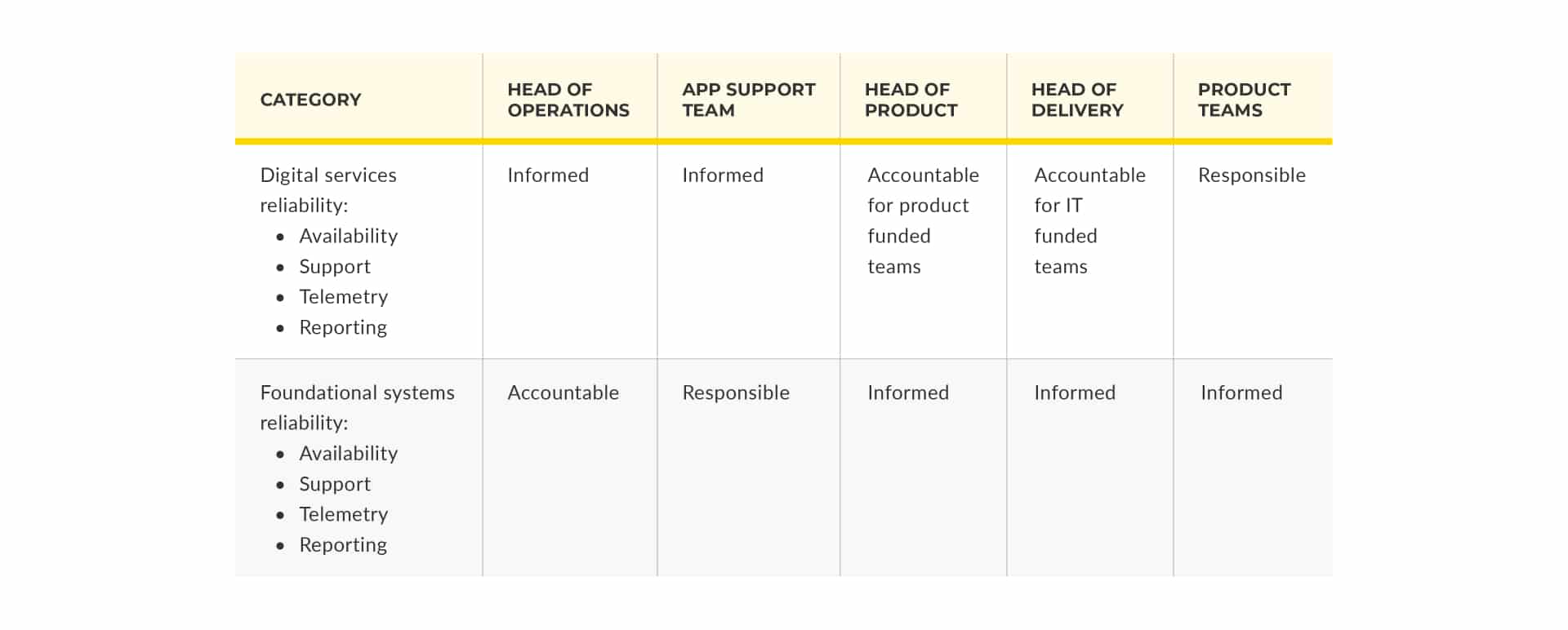
Now your product teams are held to account for failures and run cost. Their operability incentives are strong. Budget holders have to translate their business goals into operational objectives, and encourage product teams to prioritise operational features alongside product features. Developers invest in graceful degradation, because they don’t want to be called out at 0300 if something goes wrong. They will choose availability targets that balance product manager risk tolerance with engineering effort, because they won’t want to spend too much from the on-call out of hours budget.
These changes are a clear, long-term commitment to You Build It You Run It. Steve and I have seen them work well. But we won’t pretend it’s easy. It’s tough to transfer accountabilities from your Head of Operations to your Head of Product and your Head of Delivery. It’s hard to move an opex budget line item for on-call funding into separate capex budgets for the same purpose. This is why we recommend proceeding in small steps. Start by switching one of your delivery teams to using these governance practices, ensure your Head of Operations is happy for someone else to be accountable for digital reliability. And most importantly, test and learn from people as you go. Because, in our experience, it will be worth it in the long run.
To find out more, you can continue our You Build It You Run It pitfalls series:
- 7 pitfalls to avoid with You Build It You Run It
- 5 ways to minimise your run costs with You Build It You Run It
- Why your operations manager shouldn’t be accountable for digital reliability – you are here!
- How to manage BAU in product teams
- 4 ways to remove the treacle in change management
- Why product teams still need major incident management
- Stop trying to embed specialists in every product team
- How to avoid developer burnout on call
Our You Build It You Run It page has loads of resources on on-call product teams – case studies, conference talks, in-depth articles, and more. Plus our You Build It You Run It playbook gives you a deep dive into how to make it happen! Get in touch, and let us know what you think.
You’ve probably heard of You Build It You Run It before. It’s an operating model that empowers product teams to own every aspect of digital service management.
When done well, it accelerates your time to market, increases your service reliability, and grows a learning culture. There are also some pitfalls, which can drain the confidence of your senior leadership, and ultimately put the success of You Build It You Run It at risk.
Today I would like to focus on one of the pitfalls that often stops projects from getting off the ground. The run cost pitfall. This is part of our recent You Build It You Run It playbook, we take a deeper look at the risk of on-call costs becoming uncontrollable, and how you can guard against it, and even escape it.
If you’re in a hurry, our ways to minimise run costs are:
- Understand an operating model is multi-cost insurance for business outcomes
- Make product team budget holders accountable for business outcomes
- Fund on-call costs from product team budgets
- Select availability targets on financial exposure
- Select out of hours schedules on financial exposure
The run cost pitfall
If you work in a large enterprise organisation, you’re probably familiar with the traditional IT operating model. You’ll have a multi-level support hierarchy, with an L1 operations bridge team for monitoring, and an L2 application support team for incident response. Each day, an application support analyst is on-call out of hours.
The names of these teams change, but the operating model doesn’t. It’s so ubiquitous, it doesn’t really have a name of its own! In our playbook, we call it Ops Run It.
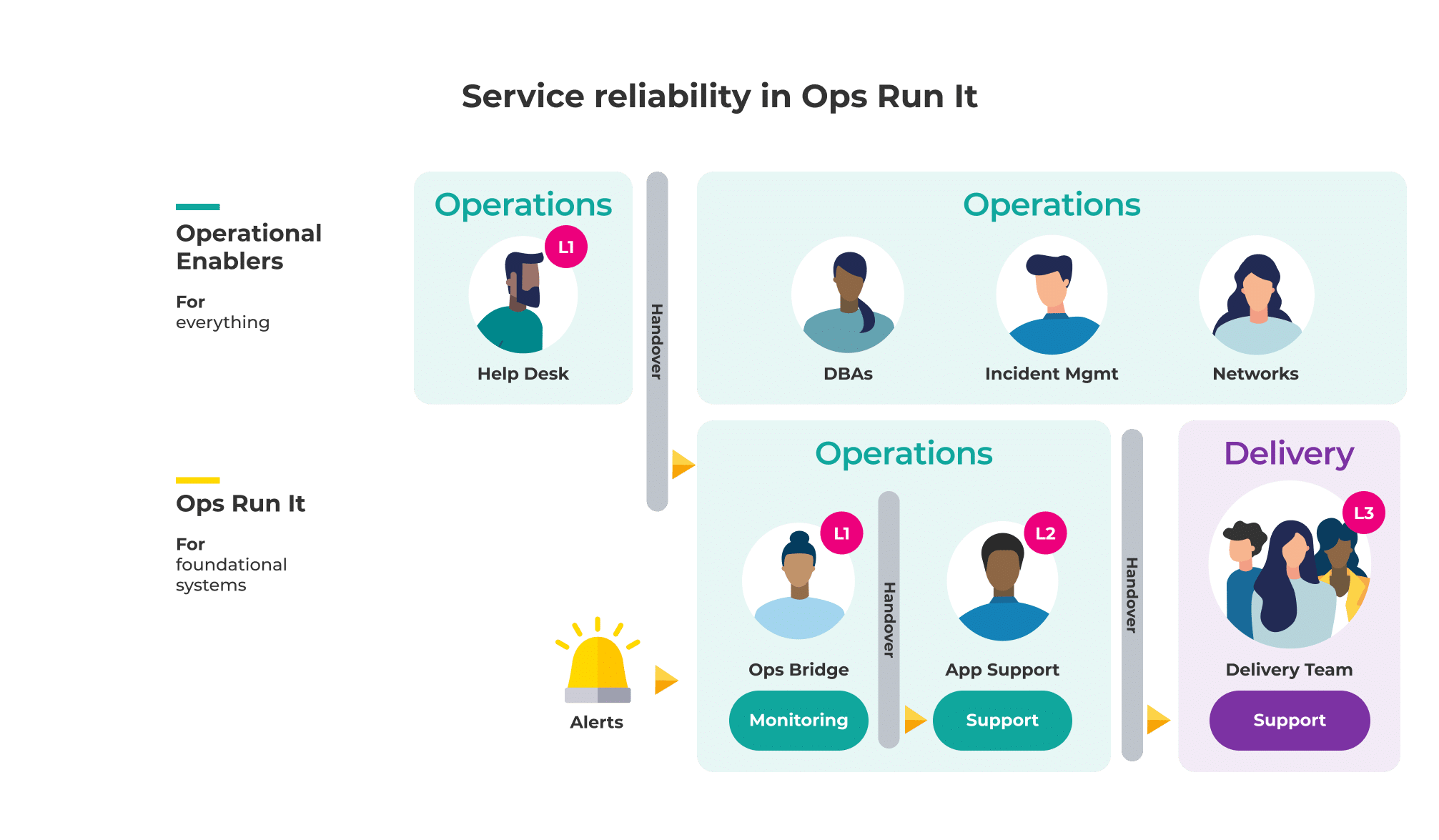
This operating model has a clear benefit in run cost management, due to:
- Low on-call standby costs. You can have one application support analyst on-call for all your software services.
- Low team costs. You can outsource your operations bridge and application support teams to a third-party managed service.
- Predictable forecasting. You can confidently estimate on-call costs a year in advance.
I’ll bet your Head of Operations likes this benefit, as they’ll be responsible for run costs in a strained opex budget. Bethan and I believe it justifies this operating model for foundational systems such as self-hosted COTS and back-office applications.
You can see from this diagram, You Build It You Run It is a superior choice for digital services. It can achieve the throughput, reliability, and learning outcomes you need to sustain innovation.
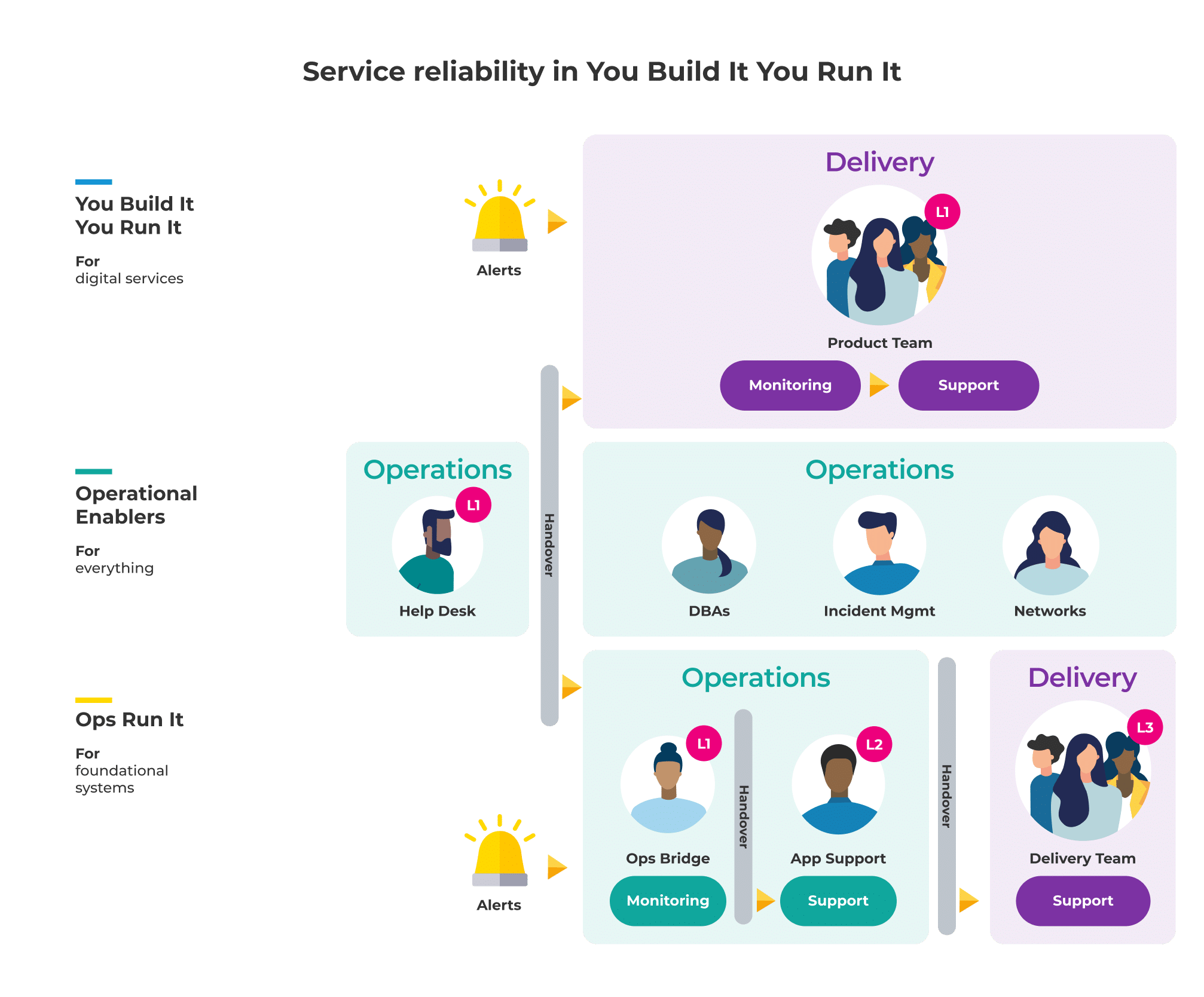
However, your senior leadership may have a perception that You Build It You Run It is too expensive. It’s understandable. Four developers on L1 on-call for four services doesn’t seem to make financial sense, does it? Especially not when compared with one L2 on-call application support analyst for four services. And what if you have 10 teams and 20 digital services?
Bethan and I call this the run cost pitfall – allowing run cost to increase every time you have a new product team on-call for a new digital service. Now, it’s important to pay developers for L1 on-call in You Build It You Run It, to recognise the inconvenience of out-of-hours support, and we’ve got some advice on transparent, fair remuneration but that doesn’t mean a high run cost is inevitable at scale.
Here are five ways to mitigate run costs, without sacrificing on-call compensation or operability incentives for your product teams.
1 – Understand an operating model is multi-cost insurance for business outcomes
Ensure there’s a broad understanding across your organisation that an operating model is an insurance policy. One which protects your business outcomes in exchange for a multi-cost premium.
Different insurance policies offer different levels of protection, at different premiums. And we all understand that the more valuable the contents of your home, the higher the premium you pay for your house insurance. See operating models are insurance for business outcomes.
The multi-cost premium for an operating model is:
You Build It You Run It produces a similar run cost to an application support team. Setup cost is still a concern, but that’s offset by lower transition, incident, and opportunity costs. Here’s a diagram of our relative cost estimates.

2 – Make product team budget holders accountable for business outcomes
Make the budget holder for a digital service accountable for deployment throughput, service reliability, and learning culture. That’ll be your Head of Product if team funding comes from a product budget, or your Head of Delivery if funding is from an IT budget. This encourages product teams to find the right balance between product features, operational features, and engineering effort.
Your Head of Operations has to transfer accountability for the reliability of all digital services onto product team budget holders. In my experience, operability incentives are maximised for a product team when they are held to account for reliability. For more on this, see make product team budget holders accountable for business outcomes.
3 – Fund on-call costs from product team budgets
Pay on-call costs from product team budgets. This incentivises product team budget holders to choose availability targets that balance business outcomes insurance with run costs. It also allows them to prioritise the protection of live product functionality alongside the delivery of new product features. And, it ensures that graceful degradation and adaptability are part of the customer experience.
Your Head of Operations transfers on-call funding for digital services from their opex budget into the distinct capex budgets owned by product team budget holders. This won’t be easy, it won’t be popular, and you need to do it. Good things happen when you empower product teams to incorporate funding choices into their decision making. For more detail, see fund on-call costs from product team budgets.
4 – Select an availability target on financial exposure
Ensure a product team budget holder selects an availability target for their digital service, based on its financial exposure. That’s the maximum revenue loss and operational costs per hour that could be incurred upon failure. This encourages a product team budget holder to translate business goals into operability objectives, and build operability in from the outset.
Selecting availability targets and deployment targets for different software services is often a dark art. It doesn’t have to be that way. See How to decide when to use You Build It You Run It – and when not to use it for a step-by-step guide on how to estimate financial exposure, and consequently select a matching availability target.
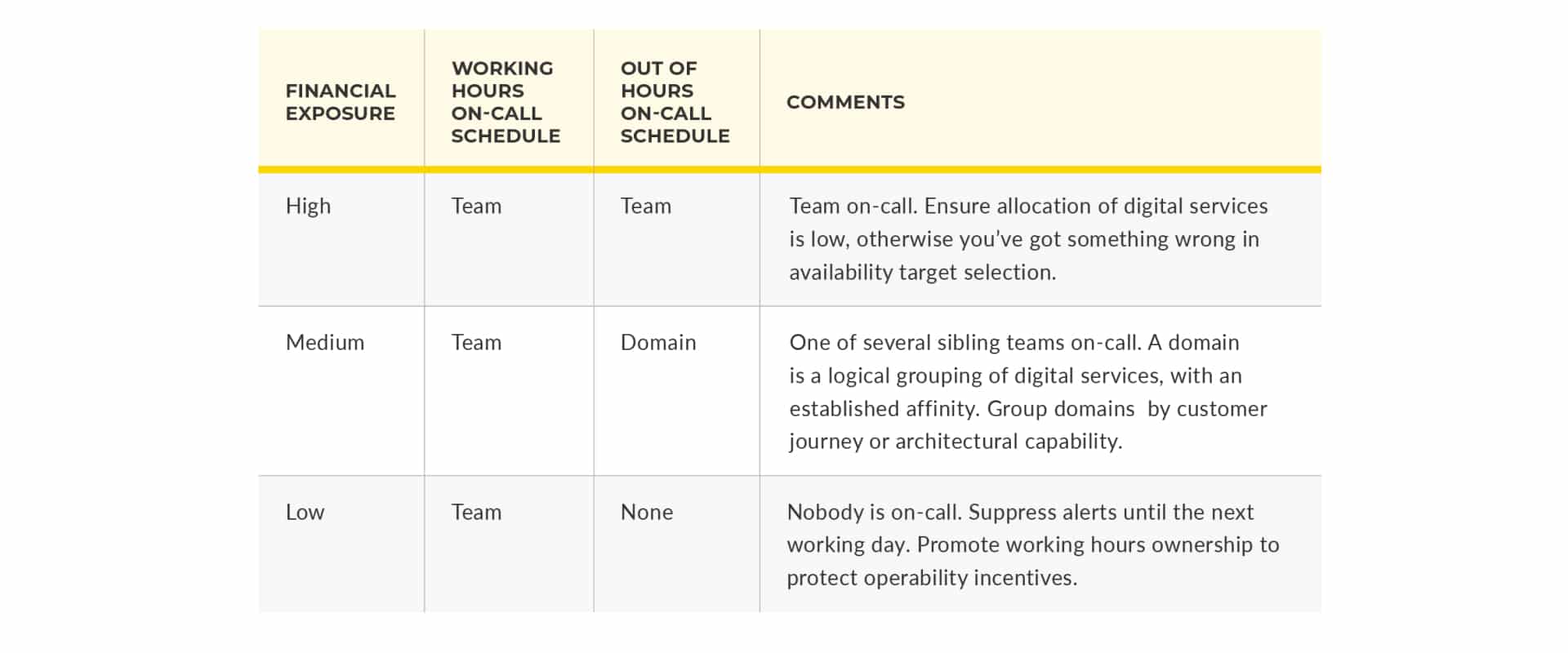
5 – Select out of hours schedules on financial exposure
Our fifth and final way to minimise your run costs is to link availability targets to different types of on-call schedules out of hours, based on financial exposure. This achieves a balance between the cost of failure, on-call costs, and remuneration for on-call developers without weakening operability incentives.
You Build It You Run It protects business outcomes. It doesn’t mean every digital service needs 24×7 on-call support. During working hours, every product team has its own on-call schedule. Out of hours, it’s a different story.
Here’s what You Build It You Run It might look like in your organisation, if you’ve got multiple product teams owning digital services with varying levels of financial exposure.

To find out more, you can continue our You Build It You Run It pitfalls series:
-
- 7 pitfalls to avoid with You Build It You Run It
- 5 ways to minimise your run costs with You Build It You Run It – you are here!
- Why your operations manager shouldn’t be accountable for digital reliability
- How to manage BAU in product teams
- 4 ways to remove the treacle in change management
- Why product teams still need major incident management
- Stop trying to embed specialists in every product team
- How to avoid developer burnout on call
Our You Build It You Run It page has loads of resources on on-call product teams – case studies, conference talks, in-depth articles, and more. Plus our You Build It You Run It playbook gives you a deep dive into how to make it happen! Get in touch, and let us know what you think.
You Build It You Run It is an operating model that empowers product teams to manage every aspect of digital services. It accelerates time to market, increases service reliability, and grows a learning culture.
But it’s not universally applicable, and there’s still an important role for your operations teams. This is why it’s important to understand whether You Build It You Run It is right for your team, and your business outcomes, before you make any major operational decisions.
In our recent You Build It You Run It playbook, Bethan Timmins and I provide an in-depth description of how to make this decision. We look at whether you should use You Build It You Run It, or have a separate operations team for your software services. We’ve evaluated this for our clients many times.
We think of You Build It You Run It as a hybrid operating model. We agree with Martin Fowler that a software service is a strategic differentiator or a utility, based on its business function. We distinguish between digital services (customer-facing microservices or applications), and foundational systems (self-hosted COTS and custom back office applications).
Our criteria for selecting You Build It You Run It or an operations team are:
- Financial exposure on failure. How much money could you lose if the service was unavailable? You can express this as an availability target e.g. 99.9%.
- Product feature demand. How often do users want new features from the service? You can express this as deployment frequency e.g. weekly deploys.
That’s easy enough. The trick is how to calculate those variables, and who makes the selection. We provide step-by-step guidance on this in our playbook.
When to select You Build It You Run It
We recommend You Build It You Run It in two scenarios. The first is common, the second is rare.
Scenario 1
You have one or more digital services with both of these outcomes:
- Financial exposure on failure corresponds to an availability target between 95.0% and 99.9% availability.
- Product feature demand can only be satisfied by weekly, daily, or more frequent deployments.
You Build It You Run It is a good idea for digital services, as they’re strategic differentiators directly tied to your business outcomes. There’s a high level of demand for new features, and they have an immediate impact on revenue growth and/or operational savings. Your goal is to minimise the opportunity cost between having an idea and trialling it with your users, and You Build It You Run It is a key enabler in this. See Select You Build It You Run It for digital services.
Scenario 2
You have one or more software services that truly needs 99.99% availability.
We also recommend You Build It You Run It for any digital service or foundational system that needs extreme reliability. It’s rare for our customers to truly require this, and the engineering effort is enormous. See Select You Build It You Run It for 99.99% availability, and for more information on extreme reliability you can read What you should (and probably shouldn’t) try from SRE by myself and Ali Lotia.
When to select an operations team
So, now we’ve defined situations where You Build It You Run It is a good choice, when do we think it isn’t? We recommend retaining an operations team for one or more foundational systems with both of these outcomes:
- Financial exposure on failure corresponds to an availability target between 95.0% and 99.9% availability.
- Product feature demand can be satisfied by monthly or fortnightly deployments.
Sometimes, you can’t buy a SaaS product for a back office business function, and self-hosted COTS or a custom application are your only choices. An operations team remains the right choice for that situation. Foundational systems have a low level of demand for new features, and they have an indirect impact on revenue streams and/or operational costs. Your goal with a foundational system is to minimise the risk of a catastrophic failure, and an operations team remains a cost-effective option.
And in case it’s not obvious – many of the modern engineering practices we recommend for You Build It You Run It product teams will also help an operations team, such as a fully automated telemetry toolchain.
How to make a decision
If you’d like a more in-depth understanding of our advice, you can follow the guidelines in our You Build It You Run It playbook. The step-by-step approach we recommend for a software service is:
- Estimate its financial exposure on failure.
- Calculate its availability target.
- Estimate its product feature demand.
- Calculate its deployment target.
- Select the operating model
We’ve created an operating model selector to help you out.
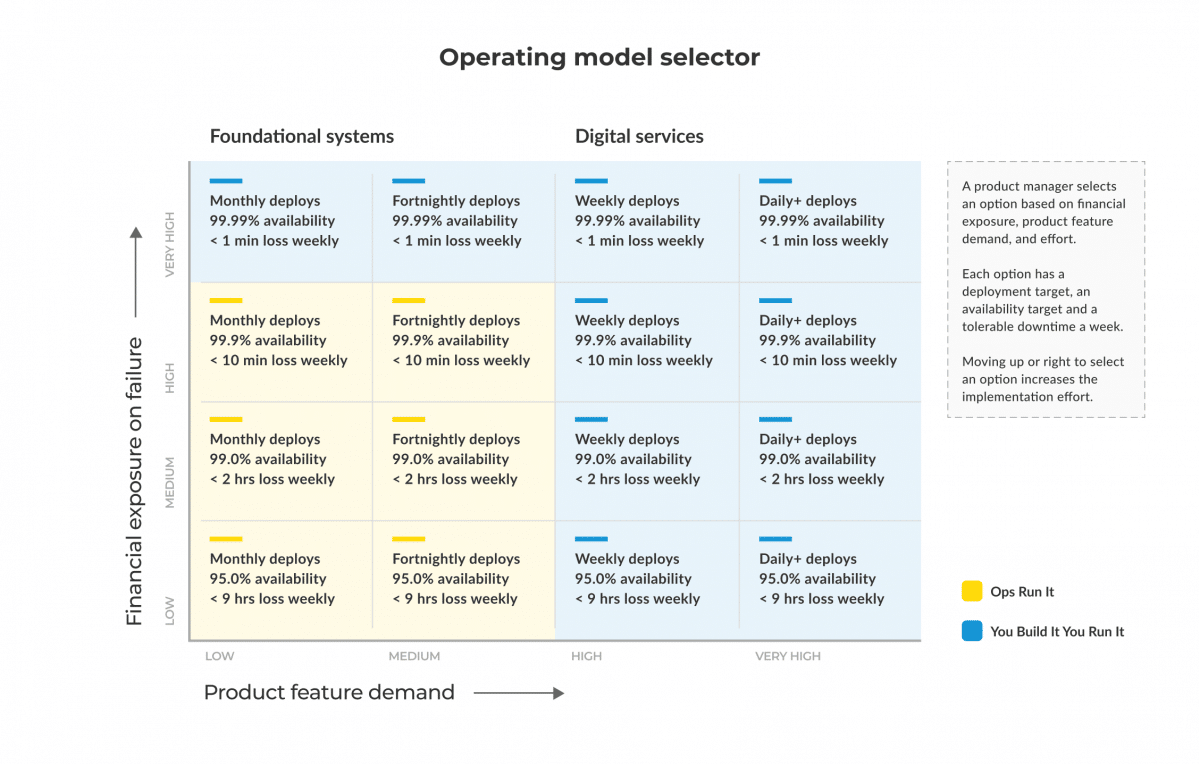
In our playbook we include detailed steps on how to estimate financial exposure on failure and product feature demand, based on your own organisational context. For financial exposure on failure, we describe how to establish exposure bands for 95.0%, 99.0%, 99.9% availability levels. We ask “what’s the maximum revenue loss and operational costs we’ll incur if this software service is unavailable for one hour?”
For product feature demand, we detail how to create feature demand bands for monthly, fortnightly, weekly, and daily deployment frequencies. We ask “what’s the feature demand we’ll see from users, for this particular software service?”
To find out more, you can continue in our What is You Build It You Run It series:
- What is You Build It You Run It
- How to decide when to use You Build It You Run It (and when not to use it) – you are here!
Our You Build It You Run It page has loads of resources on on-call product teams – case studies, conference talks, in-depth articles, and more. Plus our You Build It You Run It playbook gives you a deep dive into how to make it happen! Get in touch, and let us know what you think.
We all know the traditional enterprise IT operating model. Delivery and operations teams are on opposite sides of a wall. A delivery team builds a software service, then hands it over to operations. This causes a lot of problems, and makes it difficult to achieve business outcomes.
In our latest playbook, Steve Smith and I have used our years of experience building digital services and digital platforms with our customers to describe how we’ve helped them to achieve superior IT performance. They’ve used an operating model that empowers product teams to own every aspect of digital service management, including deployments and on-call. It’s called You Build It You Run It.
Drawing on years of experience, we wanted the playbook to be something of real value. A deep piece of content that would explain how to implement the You Build It You Run It operating model for the constantly evolving digital services we work with.
But before you jump into how to implement You Build It You You Run It, I’d like to explain this model of technology operations. I’m going to do this with Simon Sinek’s Golden Circle model. Starting with the why, then looking at the how, and finally working out the what. Here goes.

Why is there a problem?
Our customers want to sustain their own innovation. They want to satisfy the constantly changing needs of their users. And they want to stay ahead in competitive markets. But, many of them are facing tough challenges that prevent this from happening.
- They can’t accelerate their time to market. They need to launch new features to customers at least weekly, and ideally daily. Accelerate by Nicole Forsgren et al found organisations with frequent deployments were twice as likely to exceed profitability expectations.
- They can’t reduce the cost of failure. They need to realise the opportunity costs, but can’t because failures take too long to resolve. A Fortune 1000 survey found the average cost of a critical failure was between $0.5M and $1M per hour.
- They can’t nurture a high-performance culture. They need to foster teams with a high degree of psychological safety and strong decision-making. A typology of organisational cultures by Ron Westrum demonstrated that a bureaucratic culture results in little trust, low collaboration, and poor quality decisions.
We think of an operating model as insurance for business outcomes. In our experience, the traditional IT operating model of one operations team running many digital services on behalf of many delivery teams just can’t achieve the throughput, reliability, and culture required to sustain innovation.
A different operating model is needed. One which offers the right insurance for your digital business outcomes.
How can we think differently?
We can reject the division between delivery and operations teams first recommended by the COBIT framework in 1996. Its pre-Internet rationale simply doesn’t hold true today. Instead, we can look at the entire lifecycle of a digital service from cradle to grave, and ask ourselves: what’s needed to simultaneously achieve high throughput, high reliability, and a learning culture?
With that lens, we want an operating model for digital services to have:
- A focus on customer outcomes, not software outputs
- A minimum of handoffs when building and running live services
- An emphasis on knowledge sharing and learning opportunities
- A powerful incentive to constantly prioritise operational concerns alongside product features
- A means to generate powerful insights, and disseminate them far and wide
This naturally led us to You Build It You Run It.
What is You Build It You Run It?
You Build It You Run It was coined back in 2016, when the CTO of Amazon Werner Vogels said in an interview:
“Giving developers operational responsibilities has greatly enhanced the quality of the services, both from a customer and a technology point of view. The traditional model is that you take your software to the wall that separates development and operations and throw it over and then forget about it. Not at Amazon. You build it, you run it. This brings developers into contact with the day-to-day operation of their software. It also brings them into day-to-day contact with the customer. This customer feedback loop is essential for improving the quality of the service.”
In its simplest form, You Build It You Run It is an operating model for modern engineering and technology operations. It’s the (long) name for on-call product teams owning all aspects of their digital services, from inception to decommissioning. Product teams do their own production deployments, launch features to live traffic, monitor customer behaviours, and respond to incidents themselves. You Build It You Run It transforms technology operations from reactive ticket management to proactive continuous improvement.
Adopting You Build It You Run It means comprehensive changes for people, processes, and technology. It requires the creation of cross-functional teams who are responsible for the development, testing, and production support of digital services. It means redefining roles, streamlining service management processes, and building a fully automated toolchain from deployment pipeline to incident management.
Our You Build It You Run It page has loads of resources on on-call product teams – case studies, conference talks, in-depth articles, and more. Plus our You Build It You Run It playbook gives you a deep dive into how to make it happen! Get in touch, and let us know what you think.
It’s no secret that sustaining innovation is difficult for well-established organisations. By and large, they are not known as innovators. And traditional approaches to operations certainly don’t help them.
Which is why, over the years, many organisations have recognised the need to rethink how they operate their digital services. I know this because I have spent many years helping these large organisations to do this effectively.
I’m Bethan, the Managing Director of Equal Experts in Australia & New Zealand. My colleague, Steve Smith, and I have just finished a playbook on You Build It You Run It, because we want to help organisations to innovate and achieve success.
Before I tell you about the playbook, I’ll give you a little of our back story. Steve and I started in IT software development in the 1990s. At this point, there really was only one way for large organisations to operate software services. It involved multiple delivery teams building multiple services, and one operations team managing live services.
How things have changed. In recent years the emergence of Continuous Delivery, DevOps, and Site Reliability Engineering has led customers to ask us the same question.
“How do we manage the operations of our digital services now the way we build them has changed?”
They knew the traditional approach to operations was not helping them to sustain the innovation they needed. But it wasn’t clear what the alternative could be. Since 2006 there’s been talk of You Build It You Run It, but no real understanding of when, and when not, to use it – or how to implement it in large organisations. If our customers decided to adopt You Build It You Run It, we couldn’t find any references on principles to consider, practices to implement, and pitfalls to look out for.
So, Steve and I decided to combine our years of experience, the operational experiences of our customers, and the knowledge of the 2000+ people in the EE network, and publish this information as a playbook.
So why a playbook? Well, core to the values of Equal Experts is a passion for learning. We don’t pretend to know all the answers – but we are confident in our ability to find them. And when we do, we want to give our community a place to find them too.
At its core, Equal Experts is a haven where this sharing happens freely and happily between like-minded practitioners and our customers. We trade on our ability to learn and share knowledge rather than protecting or ‘guarding’ it. This is why we feel compelled to open-source our playbooks to share this knowledge as widely as possible.
We hope you enjoy reading this playbook as much as we have enjoyed creating it. We welcome your feedback and thoughts, in fact, we encourage them.