Why your head of operations shouldn’t be accountable for digital reliability
The You Build It You Run It operating model empowers product teams to own every aspect of digital service management. When done well, it accelerates your time to market, increases service reliability, and grows a learning culture.
But, as with any operating model, there are pitfalls that need to be avoided. Because if they aren’t, they will drain the confidence of your senior leadership, and ultimately put the success of You Build It You Run It at risk.
In our recent You Build It You Run It playbook, my co-author Steve Smith and I take a deeper look at an accountability pitfall, and product teams lacking strong reliability incentives. Here we take a look at this further, to consider how you can guard against this pitfall, and escape it if necessary.
No responsibilities means weak incentives
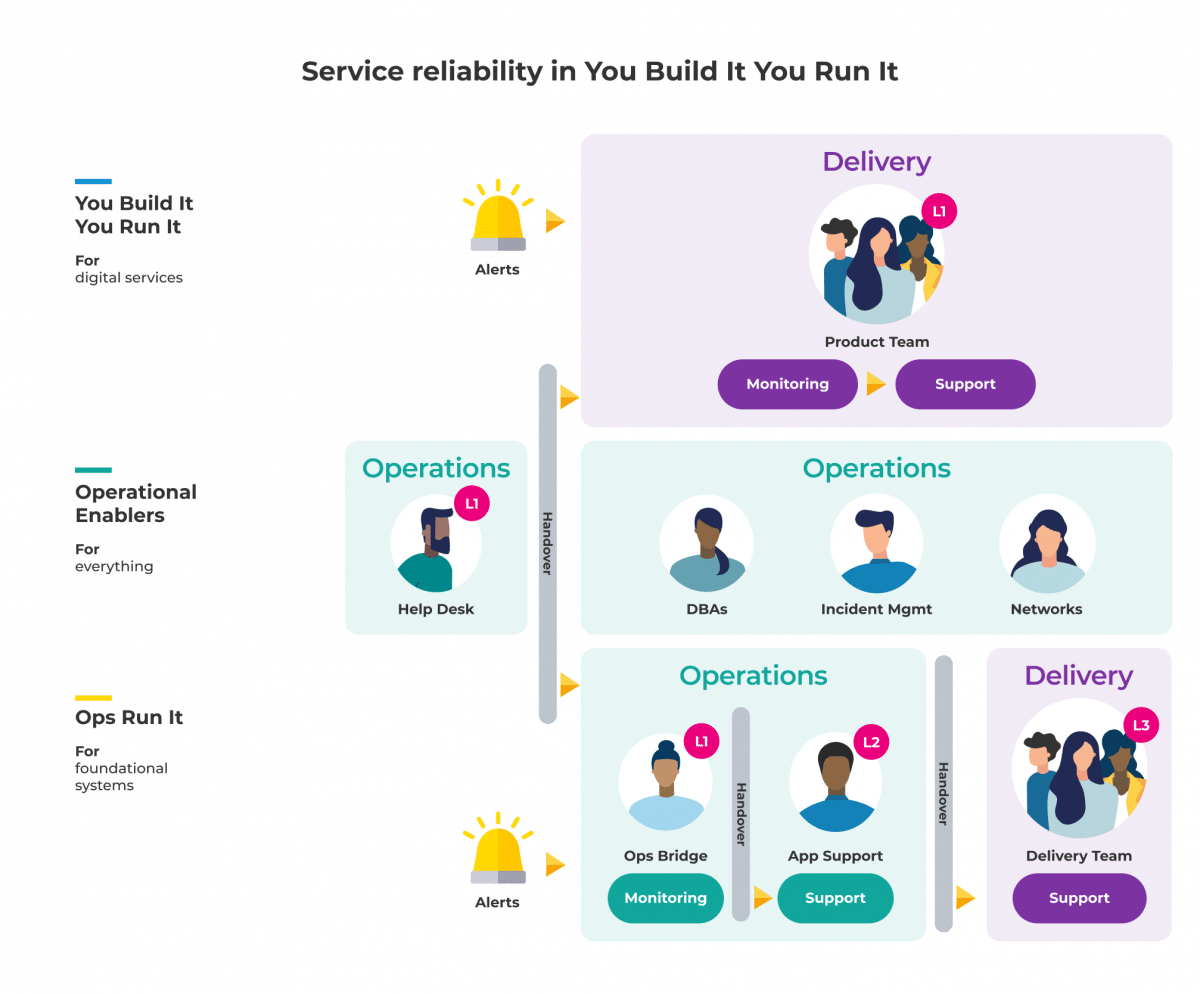
We think of You Build It You Run It as a hybrid operating model. Product teams build, deploy, operate, and support their own digital services, such as user-facing microservices. An application support team manages foundational systems, like self-hosted COTS and custom back office applications.
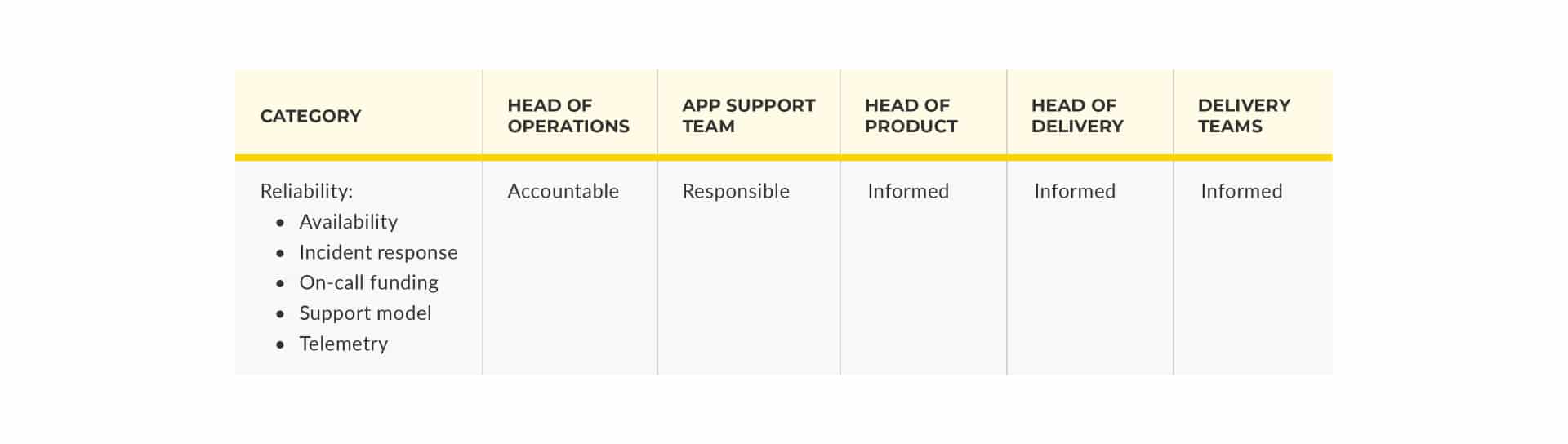
If you work in an enterprise organisation, and you haven’t adopted You Build It You Run It yet, I’ll bet your Head of Operations is accountable for the reliability of all your digital services and foundational systems. You’ve probably got a RACI model to show who’s responsible, accountable, consulted, and informed for service reliability. It’ll look like this:
This causes plenty of problems for digital services. For the purpose of this article, I’ll focus on:
Fragile architectures. Your digital services have a large blast radius, and an inability to gracefully degrade on failure. You’re exposed to multi-hour, multi-million $ outages.
Inflated availability targets. Your Digital services have higher targets than necessary, and require excessive toil to meet those targets. You spend too much $ on BAU work.
This happens because your well-intentioned delivery teams aren’t responsible, let alone accountable, for the reliability, or run cost, of the digital services they build. Teams lack the operability incentives to prioritise operational features alongside product features, or to balance availability targets with on-call costs.
These problems can be hard to spot, until you suffer a major incident. Then they become hard to ignore. In our You Build It You Run It playbook we describe one customer losing $1.5M in a 5 hour outage, because a series of cascading failures were triggered by someone typing in the wrong character.
You Build It You Run It solves these problems by making product teams accountable, not just responsible, for the reliability of their digital services. But you also need to know that some of our customers have experienced an accountability pitfall along the way.
The responsible but unaccountable pitfall
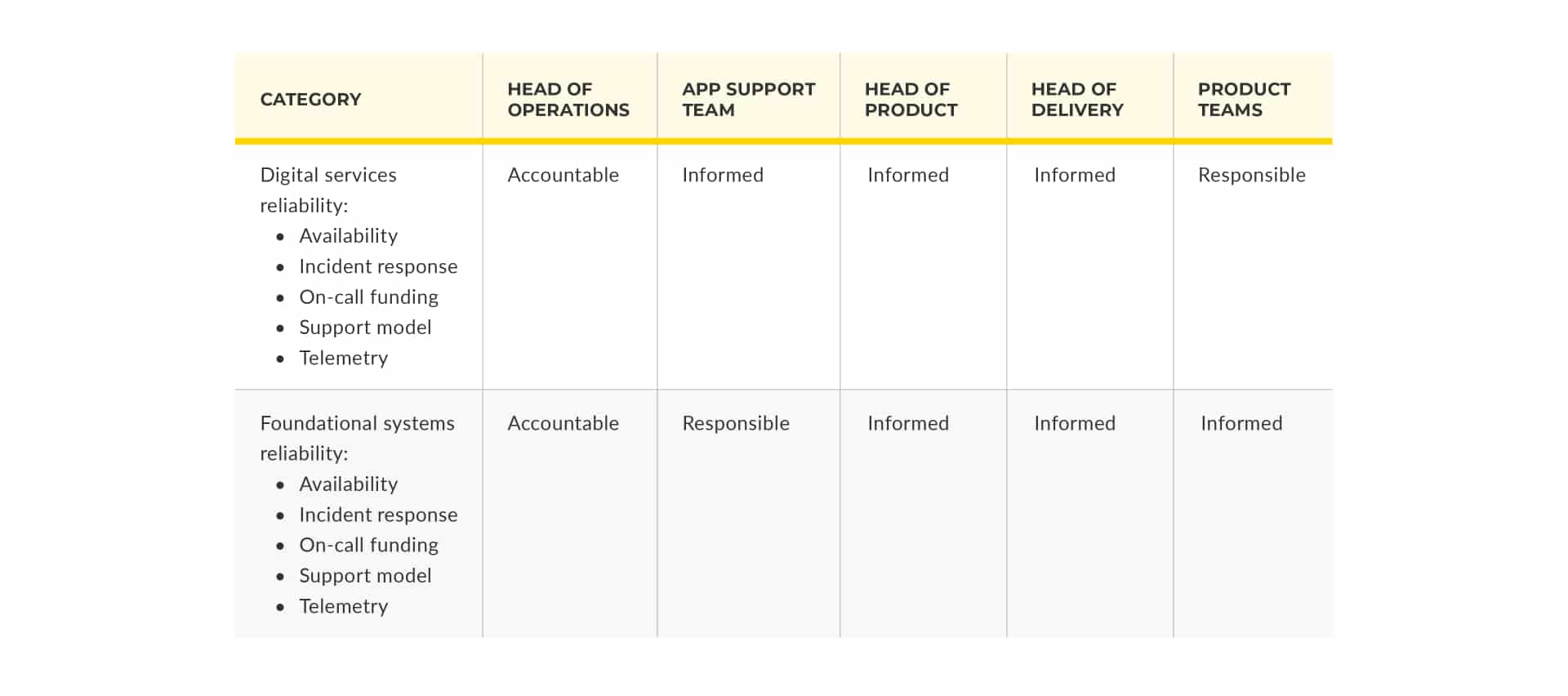
When you adopt You Build It You Run It, your product teams are on-call and responsible for running their own digital services. However, your senior leadership might want your Head of Operations to remain accountable for all live services. Your RACI becomes:
Steve and I call this the responsible but unaccountable pitfall. Your product teams feel some responsibility for reliability and run cost, which is really important. However, in at least some of your product teams, you’ll still see fragile architectures and inflated availability targets. Your operability incentives aren’t as strong as they could be, because product teams aren’t held to account for failures or run cost. This can be mitigated if your Head of Operations is extremely supportive of You Build It You Run It, but that’s pretty rare.
If you want your product teams to consistently achieve 99.0% – 99.99% availability, a time to restore that’s measured in minutes rather than hours, and an appropriate run cost, you need to change your organisational culture. Your teams must own and learn from the consequences of their decisions. Your senior leadership must empower your Head of Operations to reassign their accountabilities for digital services – but to who?
Make your product team budget holders accountable for digital outcomes
Assuming you have separate Product and IT departments, you’ve got two product team budget holders, responsible for two different capex budgets:
Your Head of Product funds digital services that are new propositions.
Your Head of Delivery funds digital services that are technology upgrades.
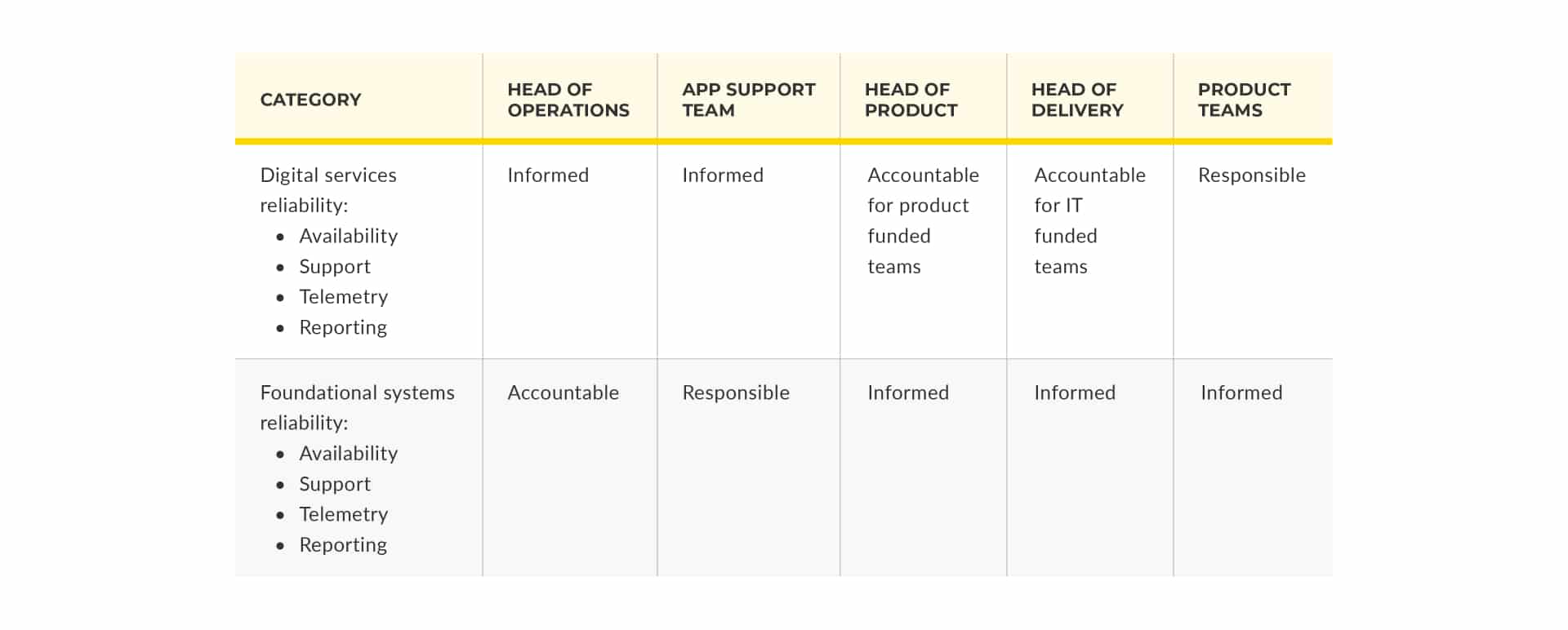
Your Head of Operations needs to split their accountabilities for digital services between your Head of Product and Head of Delivery. That way, the person paying for the digital service is responsible for its reliability and run cost, as well as its feature set. This means your RACI is:
Now your product teams are held to account for failures and run cost. Their operability incentives are strong. Budget holders have to translate their business goals into operational objectives, and encourage product teams to prioritise operational features alongside product features. Developers invest in graceful degradation, because they don’t want to be called out at 0300 if something goes wrong. They will choose availability targets that balance product manager risk tolerance with engineering effort, because they won’t want to spend too much from the on-call out of hours budget.
These changes are a clear, long-term commitment to You Build It You Run It. Steve and I have seen them work well. But we won’t pretend it’s easy. It’s tough to transfer accountabilities from your Head of Operations to your Head of Product and your Head of Delivery. It’s hard to move an opex budget line item for on-call funding into separate capex budgets for the same purpose. This is why we recommend proceeding in small steps. Start by switching one of your delivery teams to using these governance practices, ensure your Head of Operations is happy for someone else to be accountable for digital reliability. And most importantly, test and learn from people as you go. Because, in our experience, it will be worth it in the long run.
To find out more, you can continue our You Build It You Run It pitfalls series:
Our You Build It You Run It page has loads of resources on on-call product teams – case studies, conference talks, in-depth articles, and more. Plus our You Build It You Run It playbook gives you a deep dive into how to make it happen! Get in touch, and let us know what you think.
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.