What you should and (probably) shouldn’t try from SRE
We – Steve Smith and Ali Asad Lotia – are the Heads of Operability at Equal Experts (EE). We’d like to set out EE’s position on Site Reliability Engineering (SRE).
We’ll recommend the bits you should try in your organisation, mention some bits you (probably) shouldn’t try, and explain how SRE is linked to operability.
If you’re in a rush, the EE position on SRE is:
Try availability targets, request success rate measurements, Four Golden Signals, SLIs, and SLOs.
Maybe try an SRE advocacy team.
Don’t try error budgets or an SRE on-call team.
And regardless of SRE, do try putting your delivery teams on call. This is better known as You Build It You Run It.
Introduction
In 2004, Ben Treynors Sloss started an initiative within Google to improve the reliability of their distributed services. He advocated for reliability as a software feature, with developers automating tasks traditionally owned by operations teams. The initiative was called SRE, and it’s become widely known in recent years.
In Site Reliability Engineering by Betsey Byers et al, the authors set the scene for SRE by answering “why can’t I have 100% reliability?:”
100% can’t happen, because your user experience is always limited by your device (your wifi or 4G connection isn’t 100% reliable).
100% shouldn’t be attempted, because maximising availability limits your speed of feature delivery, and increases operational costs.
In The Site Reliability Workbook by Betsey Byers et al, Andrew Clay Shafer talks about reliability at scale, and says, ‘I know DevOps when I see it and I see SRE at Google, in theory and practice, as one of the most advanced implementations’.
Back in 2017, our CEO Thomas Granier explained why DevOps is just a conversation starter at EE. We both believe SRE is a conversation starter as well. It’s an overloaded concept. Phrases such as “SRE practice” and “SRE team” can be really confusing. Within EE, those terms have been clarified to reduce confusion.
The bits of SRE you should try
Based on our experiences, both of us recommend you try these SRE practices:
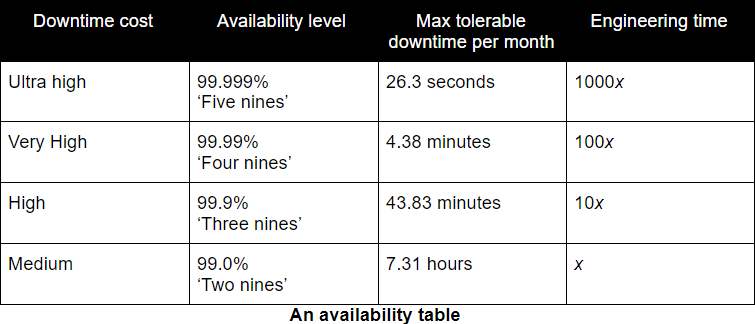
Availability targets. Calculate an availability level on downtime cost, downtime tolerance, and engineering time, to set clear expectations of availability.
Four Golden Signals. Focus dashboards on throughput, error rate, latency, and saturation, so operating conditions are easier to understand.
Service Level Indicators (SLIs). Visualise targets for availability, latency, etc. on dashboards, so operational tolerances can be watched.
Service Level Objectives (SLOs). Implement targets for availability, latency etc. as production alerts, so abnormal conditions are easily identified.
Don’t try them all at once! Run some small experiments, collect some feedback, and then adjust your approach. Availability targets are a good starting point, and Site Reliability Engineering lays out an excellent approach.
An availability target is chosen by a product manager, from a set of availability levels. First, a product manager estimates their downtime cost, based on the revenue and reputational damage of downtime. That cost is then matched to a balance between maximum tolerable downtime and required engineering time.
Engineering time stems from a valuable insight from Betsey Byers et al:
‘Each additional nine corresponds to an order of magnitude improvement toward 100% availability’
This is a powerful heuristic you can use to reason about availability targets. Like all heuristics, it’s enough for a short-term approximation that won’t be perfect. Engineering effort will always vary by service complexity.
For example, a delivery team owns a service with synchronous dependency calls. They spend three days on operational features, to harden the service until it reaches 99.0% availability. For the exact same team and exact same service, it would take up to 30 days to reach 99.9%, maybe by adding blue-green deployments and caching dependency calls. It would take 300 days for 99.99%, perhaps by reengineering dependency calls to be asynchronous and replacing the service runtime. The product manager would have to balance availability needs against three days, one month, or nine months of effort.
The bits of SRE you shouldn’t try
EE consultants strive to advise organisations on what not to try, as well as what to try. We both believe you should (probably) skip these SRE practices:
Error budgets. Turning tolerable downtime into a budget for deployments, and halting deployments for remediation work if too many errors occur.
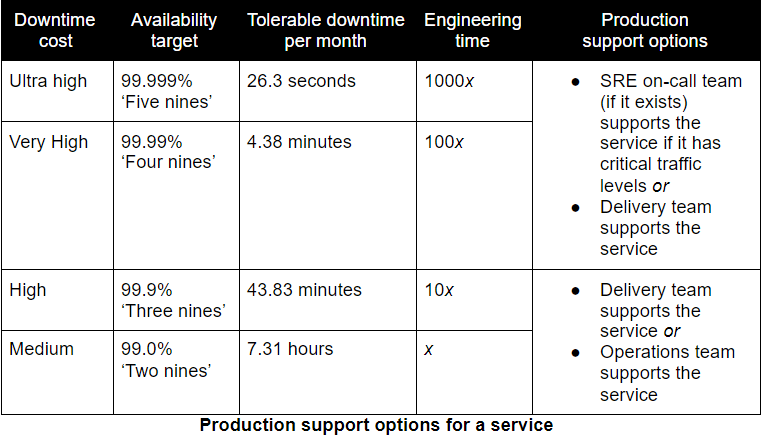
SRE on-call team. Using a central delivery team of SRE developers to support services with critical traffic levels via error budgets, while other services have delivery teams on call.
These aren’t bad ideas. They’re expensive ideas. They require cultural and technology changes that take at least an order of magnitude longer than other SRE practices. We’d only consider an SRE on-call team over You Build It You Run It if an organisation had services with an ultra high downtime cost, relative to its other services. Then a 99.99% availability target and up to 100x more engineering time might be justifiable.
We’ve used the above availability table, in private and public sector organisations. We’ve asked product managers to choose availability levels based on downtime costs, their personal tolerances for downtime, and engineering time. We’ve not seen a product manager choose more than 99.9% availability and 10x engineering time. None of them anticipated a downtime cost that warranted 99.99% availability and up to 100x more engineering time.
EE doesn’t recommend an SRE on-call team, because it’s simpler and more cost effective to put delivery teams on call.
There’s a common misconception you can rebadge an existing operations team as an SRE on-call team, or an SRE advocacy team. Both of us have repeatedly advised organisations against this. Aside from the expensive cultural and technology challenges linked to both types of SRE team, adopting SRE principles requires software engineering skills in infrastructure and service management. That expertise is usually absent in operations teams.
For a given service, we both believe these are valid production support options:
It’s all about operability
In 2017, our colleague Dan Mitchell talked about operability as the value-add inside DevOps. Dan described operability as ‘the operational requirements we deliver to ensure our software runs in production as desired”. He mentioned techniques such as automated infrastructure, telemetry, deployment health, on-call delivery teams, and post-incident reviews.
Operability is a key enabler of Continuous Delivery. Continuous Delivery is about improving your time to market. A super-fast deployment pipeline won’t be much help if your production services can’t be operated safely and reliably. EE helps organisations to build operability into services, to increase their availability and their ability to cope with failures.
Operability is the value-add inside SRE.
The SRE practice of availability targets is an effective way for an organisation to genuinely understand its availability needs and downtime tolerances. Common definitions of availability and downtime need to be established, and a recognition that planned downtime is outside of downtime tolerances. This may impact the architecture of different services, as well as patching and upgrade processes.
Four Golden Signals, SLIs, and SLOs are a great way to improve your ability to cope with failures. Per-service dashboards tied to well-understood characteristics, and per-service alerts tied to availability targets can provide actionable, timely data on abnormal operating conditions.
For example, Steve recently worked with an enterprise organisation to introduce availability targets, SLO alerts, and You Build It You Run It to their 30 delivery teams and £2B revenue website. In the first year, this was 14x cheaper on support costs, 3x faster on incident response time, and 4x more effective on revenue protection. SRE was hardly mentioned.
If your organisation has a few delivery teams, we’d expect them to adopt operability practices for themselves. If you have delivery teams at scale, you might consider an SRE advocacy team, as Jennifer Strejevitch describes in how to be effective as a small SRE practice. We’ve done something similar with Digital Platform Enablement teams, as described in our Digital Platform playbook.
Summary
SRE is a real pick and mix. We believe some of its practices are really good. You should try them, to progress towards Continuous Delivery and operability. We also see some ideas that you (probably) shouldn’t try.
The EE position on SRE is:
Do try availability targets, request success rate measurements, Four Golden Signals, SLIs, and SLOs (and don’t call it SRE if you don’t want to).
Maybe try an SRE advocacy team (if you have delivery teams at scale).
Don’t try error budgets or an SRE on-call team (unless you genuinely need 99.99% availability).
And with or without SRE terminology:
Do try putting your delivery teams on call, to increase service deployments and improve production reliability.
If you’d like some advice on SRE, Continuous Delivery, or operability, get in touch using the form below and we’ll be delighted to help you.
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.