In today’s world, data is an important catalyst for innovation, significantly amplifying the potential of businesses. Given the ever-increasing volume of data being generated and the complexity of building models for effective decision making, it’s imperative to ensure the availability of high quality data.
What is data quality?
Data quality measures how well data meets the needs and requirements of its intended purpose. High data quality is free from errors, inconsistencies and inaccuracies, and can be relied upon for analysis, decision making and other purposes.
In contrast, low quality data can lead to costly errors and poor decision making, and impacts the effectiveness of data-driven processes.
How to ensure data quality
Ensuring high quality data requires a blend of process and technology. Some important areas to focus on are:
Define standards: it’s important to define quality criteria and standards to follow.
Quality assessment: assess criteria and standards regularly using data profiling and quality assessment tools.
Quality metrics: set data quality metrics based on criteria such as accuracy, completeness, consistency, timeliness and uniqueness.
Quality tools: identify and set up continuous data quality monitoring tools.
Data profiling: analyse data to know its characteristics, structure and patterns.
Validation and cleansing: enable quality checks on data to ensure validation and criteria happen in line with criteria
Data quality feedback loop: Use a regular quality feedback loop based on data quality reports, observations, audit findings and anomalies.
Quality culture: Build and cultivate a quality culture in your organisation. Data quality is everyone’s responsibility, not just an IT issue.
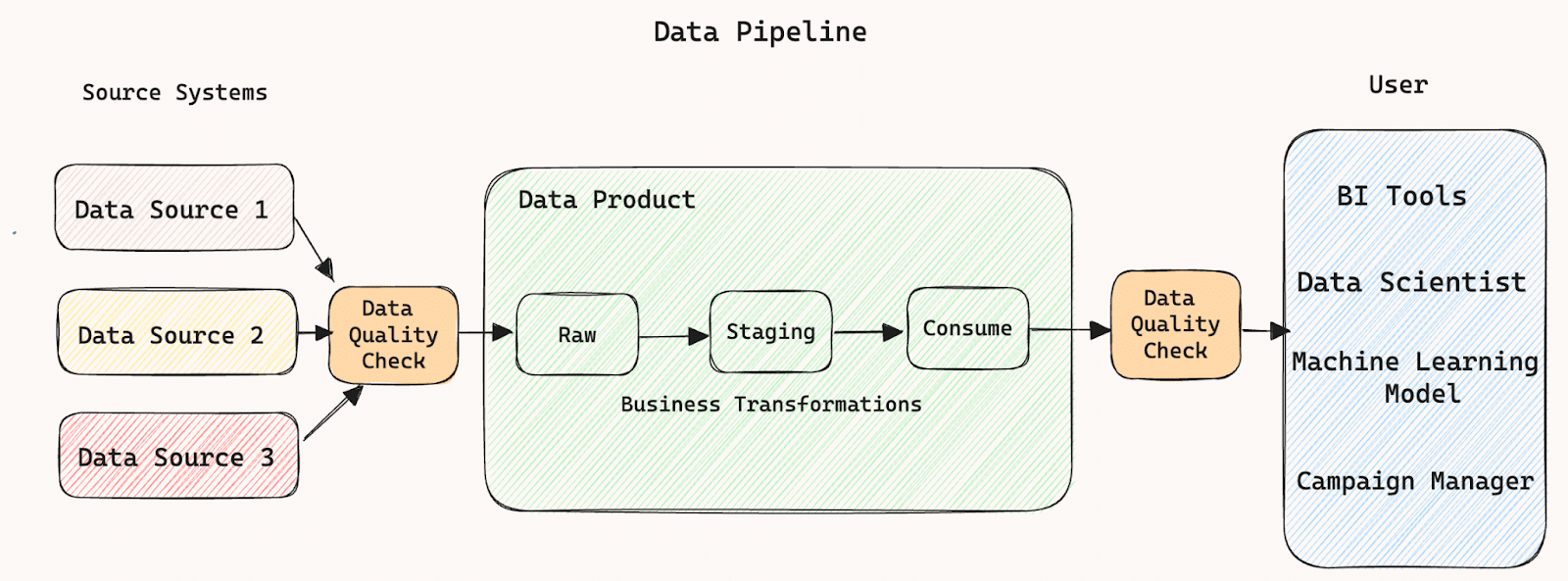
Example Data Pipeline:
This diagram shows a basic data pipeline. It takes data from multiple source systems, putting data into various stages eg. RAW, STAGING and CONSUME. It then applies transformations and makes data available for consumers. To ensure the accuracy, completeness, reliability of the data:
There is a data quality check in between the source systems and data product, which ensures that quality data is being consumed, and
There is a data quality check in between the data product and consumers, which ensures that quality data is being delivered.
Data quality checks can include the following:
Uniqueness and deduplication checks: Identify and remove duplicate records. Each record is unique and contributes distinct information.
Validity checks: Validate values for domains, ranges, or allowable values
Data security: Ensure that sensitive data is properly encrypted and protected.
Completeness checks: Make sure all required data fields are present for each record.
Accuracy checks: Ensures the correctness and precision of the data. Rectify errors and inconsistencies in the data.
Consistency checks: Validate the data formats, units, and naming conventions of the dataset.
Tools/Framework to ensure data quality
There are multiple tools and frameworks available to enable Data Quality and Governance, including:
Alteryx/Trifacta (alteryx.com) : A one stop solution for enabling data quality and governance for data platforms. The advanced capabilities enable best practices in data engineering.
Informatica Data Quality (informatica.com): Offers a comprehensive data quality suite that includes data profiling, cleansing, parsing, standardisation, and monitoring capabilities. Widely used in enterprise settings.
Talend Data Quality (talend.com): Talend’s data quality tools provide data profiling, cleansing, and enrichment features to ensure data accuracy and consistency.
DataRobot (datarobot.com): Offers data preparation and validation features, as well as data monitoring and collaboration tools to help maintain data quality throughout the machine learning lifecycle. Primarily Datarobot is an automated machine learning platform.
Collibra (collibra.com): Collibra is an enterprise data governance platform that provides data quality management features, including data profiling, data lineage, and data cataloging.
Great Expectations (greatexpectations.io): An open-source framework designed for data validation and testing. It’s highly flexible and can be integrated into various data pipelines and workflows. Allows you to define, document, and validate data quality expectations.
Dbt (getdbt.com): Provides a built-in testing framework that allows you to write and execute tests for your data models to ensure data quality.
Data quality in action
We have recently been working with a major retail group to implement data quality checks and safety nets in the data pipelines. The customer has multiple data pipelines within the customer team, and each data product runs separately, consuming and generating different Snowflake data tables.
The EE team could have configured and enabled data quality checks for each data product, but this would have made configuration code redundant and difficult to maintain. We needed something common that would be available for the data product in the customer foundation space.
We considered several tools and frameworks but selected Great Expectations to enable DQ checks for several reasons:
Open source and free
Support for different databases based on requirement
Community support on Slack
Easy configuration and support for custom rules
Support for quality checks, Slack integration, data docs etc
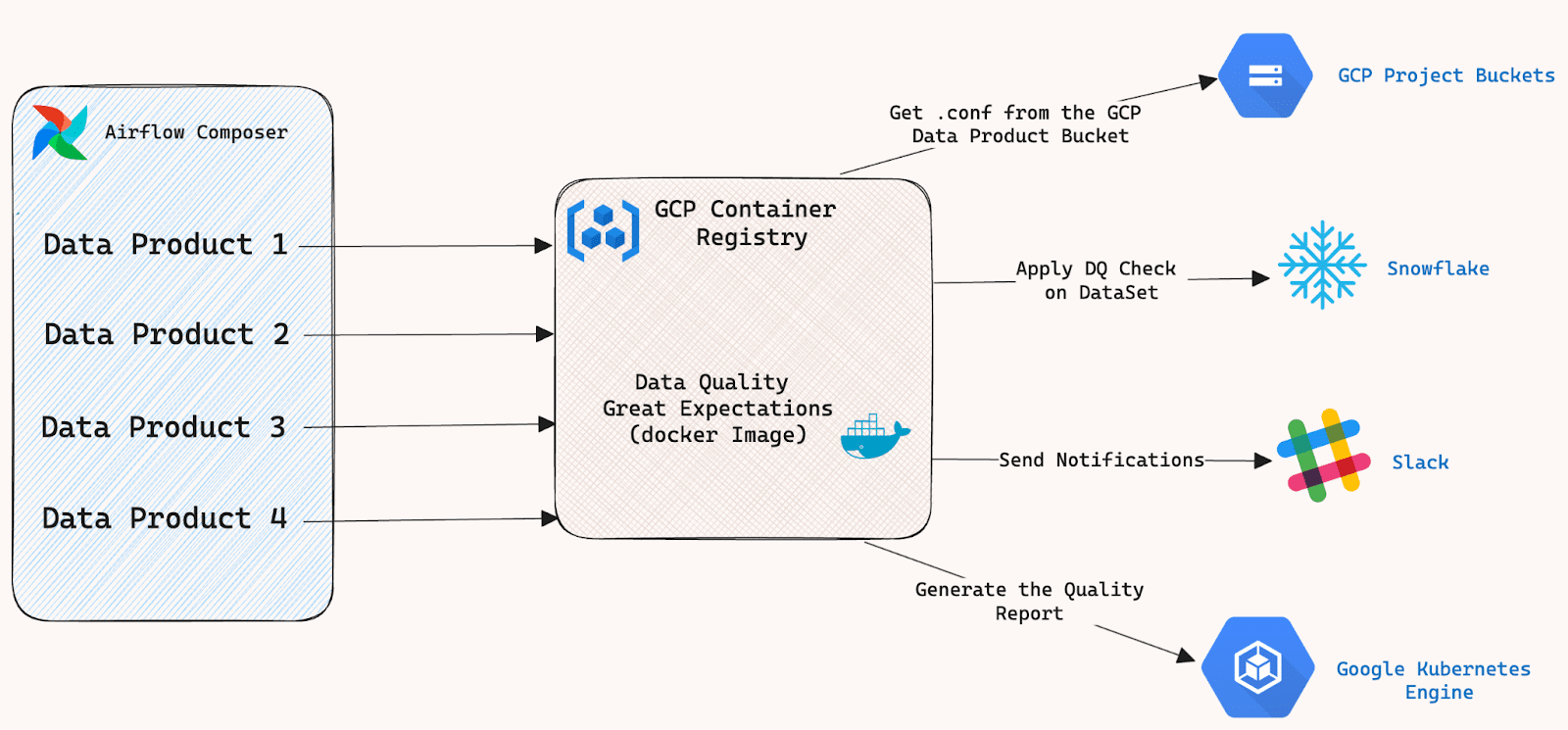
We helped the retailer to create a data quality framework using docker image, which can be deployed in the GCR container registry and made available across multiple groups.
All the project specific configuration, such as Expectation Suite and Checkpoint file are kept in the data product’s GCS Buckets. This means the team can configure required checks based on the project requirement. Details about GCP Bucket are shared in the DQ image. The DQ image is capable of accessing the project specific configuration from Bucket and executing the Great Expectation suite on Snowflake tables in one place.
Flow Diagram:
The DQ framework can:
Access the configuration files from the data product’s GCP Buckets
Connect to Snowflake Instance
Execute Great Expectation suites
Send the Slack notification
Generate the quality report using Data Docs (In progress)
Quality assurance is a continuously evolving process and requires constant monitoring and audit. By doing this, we not only safeguard the credibility of the data but also empower our customer with the insights needed to thrive in a data-centric world.
You may also like
Case Study
Solving the data pipeline puzzle at John Lewis & Partners
Case Study
Breaking down a data pipeline monolith
Blog
‘But I’ve already paid for the data!’ Talking to your finance director about continuing investment in data
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.