The role of LLMs in evaluating Gen AI applications
We are experiencing unprecedented complexity and unpredictability in applications that pose unique challenges in evaluation and testing. Transitioning a minimum viable product (MVP) to a stage where it’s ready for production poses particularly challenging tasks.
In a previous blog post, our exploration into behaviour-driven development (BDD) for evaluating Gen AI applications showed some innovative methodologies in this space, such as dialogue simulation. This blog will focus on the role of LLMs as evaluators, illustrating their critical contribution to unlocking test automation for these intricate systems.
Understanding the challenges of LLMs
The “nature” of LLMs
The inherent non-determinism of LLMs enriches conversational agents with dynamic and varied responses. But they also present significant hurdles in achieving consistent testing outcomes. Adjusting an LLM’s temperature parameter can make the model “more deterministic,” yet the challenge of variability remains. This variability, though desirable for engaging dialogues, complicates evaluation, particularly when deterministic outcomes are essential.
The complexity of natural language
The use of natural language in Gen AI applications introduces additional layers of complexity in testing. Language’s inherent ambiguity and subjectivity make it challenging to assess the quality and appropriateness of responses. This challenge is amplified in evaluating conversational agents, where dialogue nuances critically impact user satisfaction. Emphasising the importance of LLMs’ contextual understanding can provide a bridge over these complexities, offering a path to more refined and sophisticated evaluation metrics.
Judging LLMs….with LLMs
Perception
The concept of using an LLM to test another LLM application may seem paradoxical from a software engineering viewpoint, raising concerns about the overlap between production and testing environments. The goal, however, is not to evaluate the LLM itself, but to assess the interplay between prompts and the model to produce desired outcomes, considering the ethical implications and biases that may arise in such evaluations.
Evaluation metrics have advanced
Significant strides in evaluating generative models have been made. Traditional metrics like BLEU and ROUGE (which commonly use methods that rely on surface-form similarity only fail to account for meaning-preserving lexical and compositional diversity) proved to be ineffective in evaluating generative text, giving way to newer, more advanced methods like BERTScore and recently GPTScore. These newer metrics leverage the semantic capabilities of models like BERT for a deeper insight into the semantics of the text. BERTScore uses pre-trained contextual embeddings from BERT and matches words from a candidate and a reference text. GPTScore proposed a highly flexible evaluation framework using LLMs to evaluate. Subsequent research introduced new perspectives: LLM Eval focused on evaluating open domain conversations using a single prompt, and G-EVAL proposed a framework using chain-of-thought to assess the quality of the generated text. However, it’s important to note that these evaluation strategies are not without their biases. For example, the order of a pairwise comparison can significantly influence results (position bias). Strategies such as employing an alternative LLM for evaluative purposes have been explored to mitigate such biases.
Recently, it was evaluated how this kind of evaluation correlates with human judgement in Judging LLM-as-a-Judge, and the result was outstanding:
Our results reveal that strong LLMs can achieve an agreement rate of over 80%, on par with the level of agreement among human experts, establishing a foundation for an LLM-based evaluation framework.
Putting prompts to practise
To evaluate LLM responses with an LLM, we need to use a prompt (or multiple prompts) depending on the approach. In LLM-as-a-judge research, there are strategies for different scenarios: pairwise comparison when we have a reference answer, single answer evaluation and multi-turn evaluation. For instance, the prompt for multi-turn evaluation is the following:
The prompt looks simple, but as with any other prompt, every token was crafted to achieve the best results. Note that the prompt asks for the explanation which helps the LLM to output the reasoning and achieve a more reliable rating.
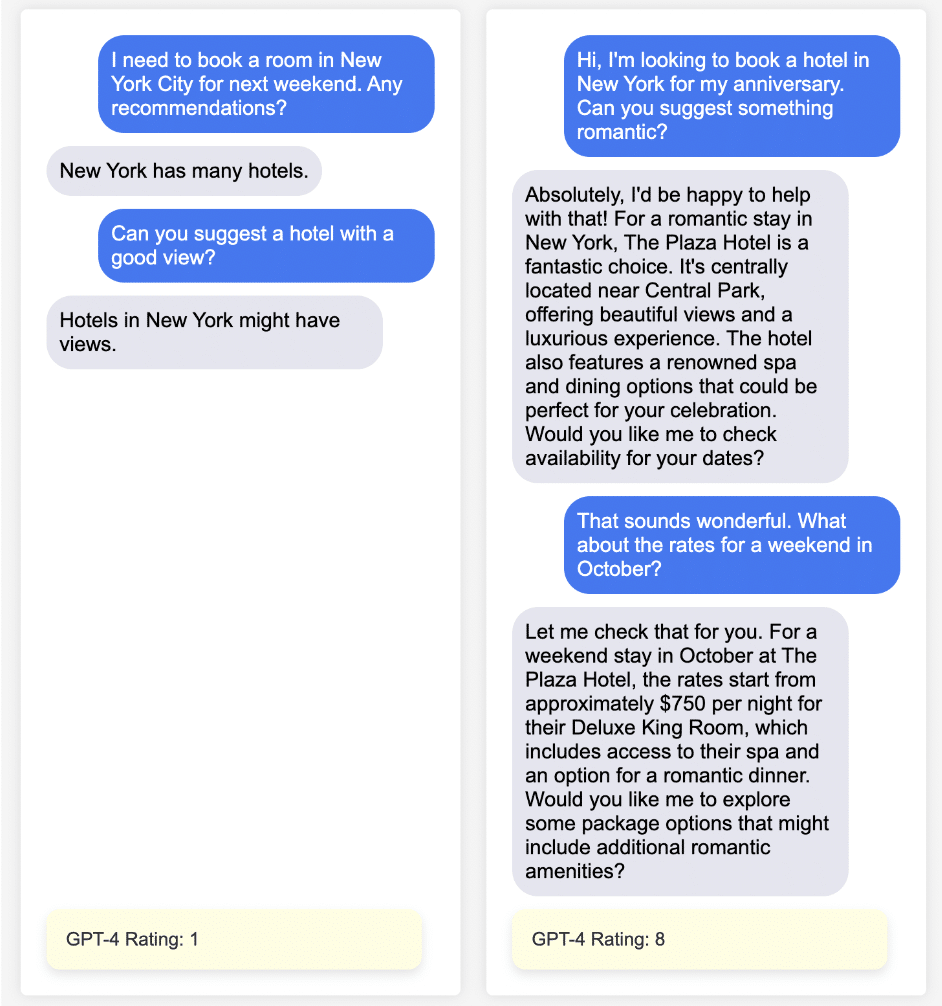
Picking up the example from our previous blog post, we can use the prompt to evaluate some dialogues:
The ratings make sense to me. Rating scales are tricky – but it is for humans, too (i.e. central tendency bias, scale granularity, etc).
From the evaluation details of the first chat, the following is an excerpt of the output:
The response from Assistant A is notably lacking in specificity and utility. The statement “Hotels in New York might have views” is both obvious and non-informative. It does not address the user’s request for recommendations, nor does it offer any actionable advice or information that would aid in making a booking decision. There’s no mention of specific hotels, areas within New York City known for good views, nor any attempt to qualify what might constitute a “good view” (e.g., city skyline, Central Park, rivers).
It shows clearly that GPT-4 was able to provide good reasoning about the dialogue.
Impact on Gen AI application development
Automating evaluation methods, as discussed, facilitates the integration of testing into the development lifecycle of Gen AI applications, enhancing practices like Continuous Integration/Continuous Deployment (CI/CD). Nonetheless, the associated costs of testing warrant careful consideration. The use of advanced models like Claude or GPT-4, while beneficial, can introduce significant overhead during development phases.
The existence or creation of a gold dataset for a specific problem allows for a comparative analysis between high-end, costly models and their more economical counterparts, such as llama3. For example, in our previous dialogue examples, llama3 and GPT-4 yielded comparably effective scores. While this alone does not conclusively determine superiority, it highlights a noteworthy potential. A key benefit of employing smaller models is their feasibility for local execution by developers, eliminating the dependency on external services. This aspect is incredibly valuable during the development phase. For stages like Continuous Integration (CI), where efficiency and accuracy are paramount, selecting the most suitable models becomes crucial.
Enhancing reliability in Gen AI testing: Mitigation strategies and the human element
Achieving complete certainty in testing outcomes for Gen AI applications is challenging if not unachievable. Therefore adopting a mitigation strategy can significantly enhance reliability. An effective approach involves integrating human evaluation and feedback loops into the testing process, emphasising the “human-in-the-loop” paradigm, where real users or subject matter experts interact with the Gen AI system and provide feedback on its responses. Through this process, we can leverage human intuition and judgement to identify nuances or issues that automated testing may overlook, including evaluations based on LLMs.
Final thoughts
While human evaluation remains the most accurate evaluation strategy, LLM-based evaluation provides a good and scalable way to evaluate applications, enhancing early and iterative testing phases.
It does come at a cost, and it might not be sufficient, therefore the collaborative interplay between human insight and LLM evaluations will be key to developing more reliable, engaging, and valuable AI applications which can go from an MVP into production.
You may also like
Blog
The role of LLMs in evaluating Gen AI applications
Case Study
How Travelopia improved customer wait time from 24 hours to instant with GenAI
Blog
3 AI regulation questions you need to address in 2024
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.