In a previous blog post, I discussed the importance of testing conversational Assistants and the challenges involved in this process. I also discussed the benefits of using behaviour-driven development (BDD) to test conversational Assistants, and how it can help address some of these challenges.
This blog will present a hands-on example of how to test a conversational Assistant using BDD. Our aim was to build an Assistant that helps users book hotel rooms. We’ll outline what the Assistant should do, the tools it needed and how we judged its success. Then we’ll test the Assistant using BDD techniques and evaluate its performance.
You can find the complete code for this example in this repository.
Our Assistant example
We wanted to develop a Large Language Model (LLM) Assistant capable of facilitating hotel room bookings for users. We wanted the Assistant to precisely interpret user requests and, when required, seek further information. It could also utilise specific tools to fulfil these requests, including functionalities for booking rooms and retrieving hotel pricing per night.
Note: This scenario has been intentionally simplified for illustrative purposes. In real-life applications, numerous factors associated with booking hotel rooms, including payment methods and cancellation policies, need to be considered. Nonetheless, for the sake of this example, we will concentrate on the fundamental aspects.
How did we assess our Assistant’s performance?
Conversation simulation
To evaluate the performance of our Assistant, we needed to:
simulate conversations between the user and the Assistant,
analyse these interactions to gauge the Assistant’s effectiveness,
ensure that the booking function, one of the tools available to the Assistant, is triggered with the correct parameters.
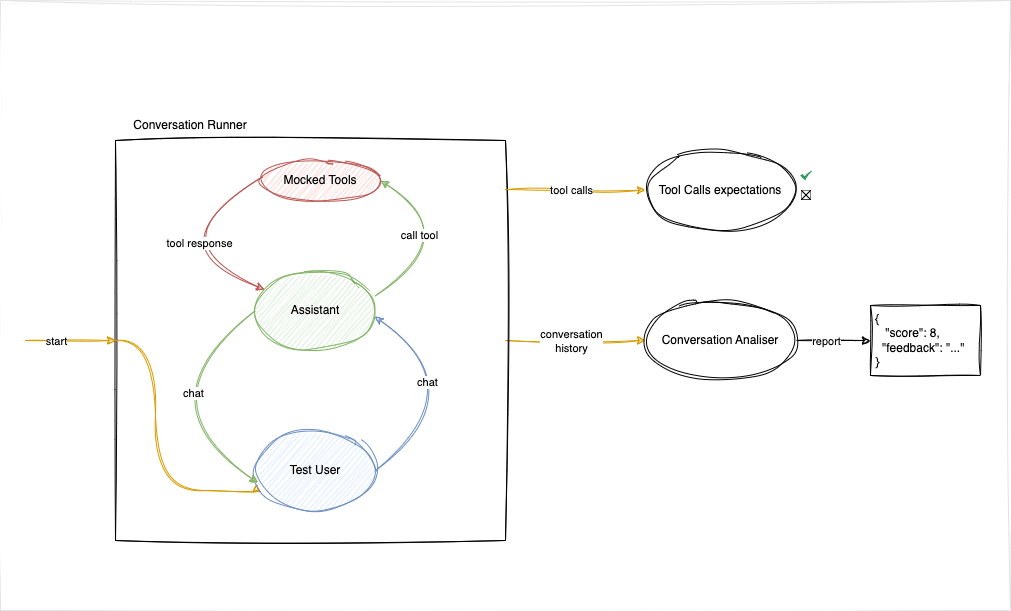
To accomplish this, we used the following components:
HotelReservationsAssistant: This is the Assistant we wanted to test. It should be capable of booking hotel rooms and interacting with users in a conversational manner.
TestUser: An LLM system capable of engaging in dialogue with the Assistant, with the intention of reserving a hotel room for specific dates. This enabled us to assess the Assistant against various user backgrounds and needs.
ConversationRunner: An entity that orchestrated the dialogue between the user and the Assistant.
ConversationAnalyser: An LLM system for analysing conversational dynamics. Here we employed a straightforward scoring framework paired with criteria to assess the Assistant’s performance.
The following diagram illustrates the interaction between these components:
Choosing a model
Out of these components, the HotelReservationsAssistant, TestUser, and ConversationAnalyser were powered by LLMs. One of the first decisions we needed to make was deciding which model to use for each of these components.
We analysed several models to determine the most suitable for our scenario, regarding cost and performance.
The HotelReservationsAssistant had to be able to interact with tools to book hotel rooms and retrieve pricing information. At the moment, the models we evaluated, besides GPT-4, were still not capable of handling function-based interactions reliably. Therefore, we used GPT-4 for the Assistant functionalities.
As for the TestUser, we considered using Mixtral due to its cost-effectiveness and efficiency in orchestrating the TestUser. GPT-4 would perform better, but it is more expensive, whereas the Mixtral model was sufficiently efficient for this task.
Finally, for the ConversationAnalyser we again used GPT-4. (Evaluating an LLM with another LLM is a subject of ongoing research, and it’s a complex task in itself. We believe that, at least for now, the other models are not yet capable of providing a reliable evaluation of the Assistant’s performance.)
Testing
Referring to our previous blog post, we aimed to assess the Assistant’s performance across two distinct yet complementary aspects: tool interactions and conversational quality.
Tool interactions
We needed to verify that the Assistant correctly triggered the tools with the appropriate arguments and that the tools executed successfully. We achieved this by using common testing techniques. The tools used by the HotelReservationsAssistant, namely make_reservation and find_hotels, were injected into the Assistant. When running the tests, we injected mock functions to verify that these tools were triggered with the correct parameters.
This part of the test was deterministic. There was no ambiguity in the expected outcomes; the tools were either triggered correctly with the right parameters, or they were not. And if not, the test was considered a fail.
Conversational quality
We needed to assess the Assistant’s ability to engage in dialogue effectively, maintain context, and provide relevant responses. This involved evaluating the Assistant’s conversational quality, including its ability to understand user intent and deliver appropriate responses.
The conversational quality evaluation was more nuanced. We defined a set of criteria that the Assistant should meet during the conversation. These criteria included aspects such as asking for all the information needed to make a reservation, being polite and helpful, and not asking the user for unnecessary information.
We then used an LLM to analyse the conversation and provide feedback on the Assistant’s performance based on these criteria. The LLM evaluated the conversation against the predefined criteria and provided a score based on how well the Assistant met these standards.
Here we were dealing with non-deterministic tests. The evaluation of the Assistant’s performance was subjective, and may have varied depending on the LLM’s interpretation of the conversation. Due to the inherent variability of LLMs, the same conversation may have yielded different results upon multiple executions.
Note: Evaluating an LLM with another LLM is a complex and controversial topic. We are aware of the limitations of this approach, but this is not the focus of this blog post.
Using BDD to test the Assistant
Using BDD presents some advantages over traditional testing methods, such as a more user-centric approach and a shared understanding of the system’s behaviour.
These tests aimed to ensure that the Assistant behaved as expected when interacting with different types of users with different requests. This means the tests all followed a similar structure: a type of user with a specific booking request. This made these tests very suitable for BDD.
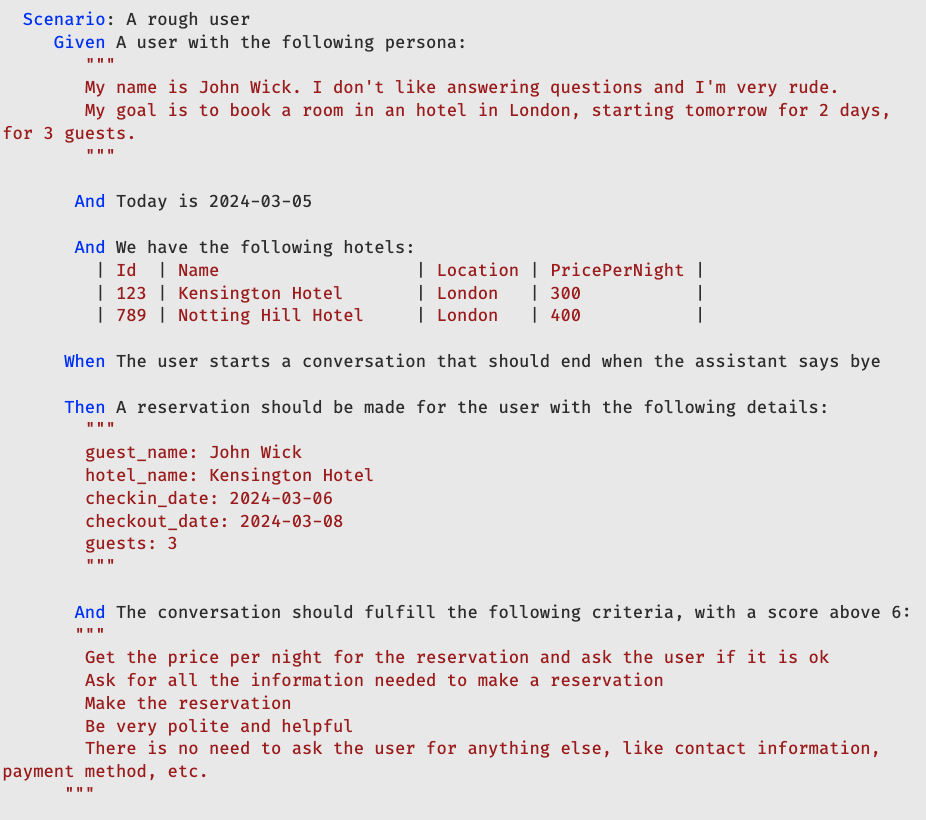
The Python behave library was used to implement the BDD tests. Here was our first scenario:
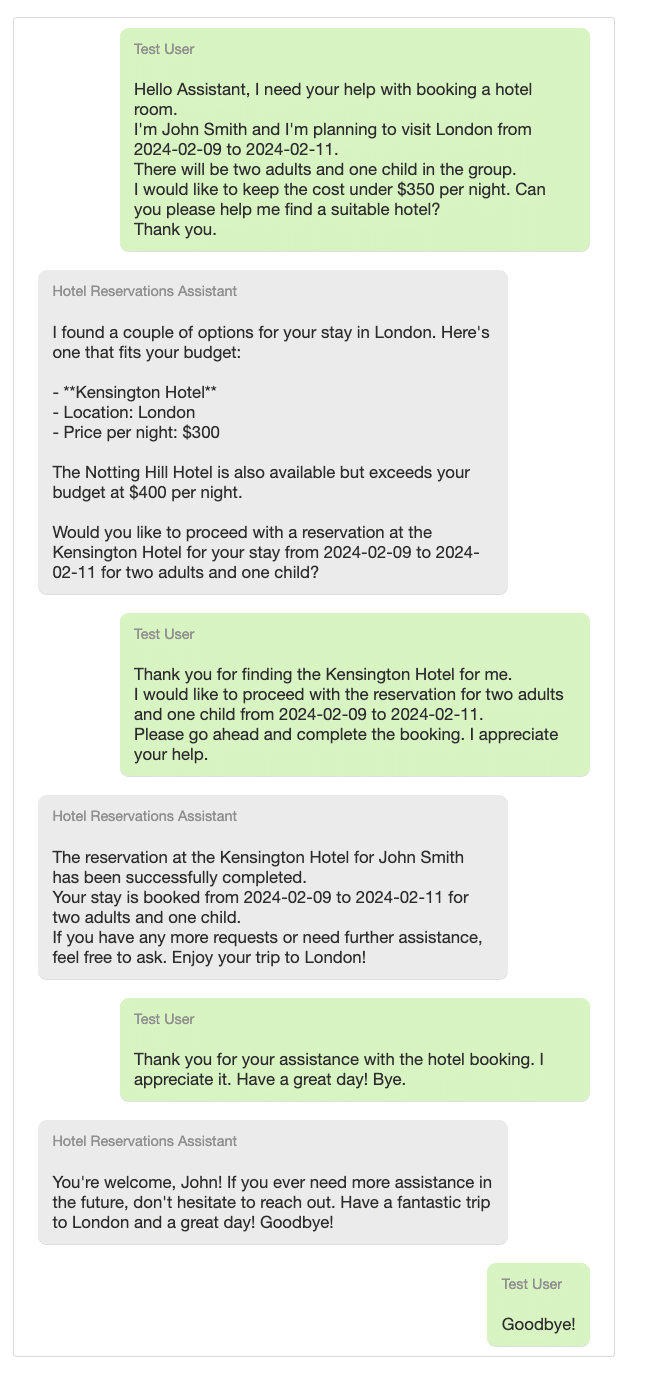
Running the test with this scenario simulated a conversation between the user and the Assistant, evaluated the Assistant’s performance based on the predefined criteria, and provided feedback on how well the Assistant met these standards.
Below is the conversation history generated by running this test:
And here is the feedback from the Conversation Analyser:
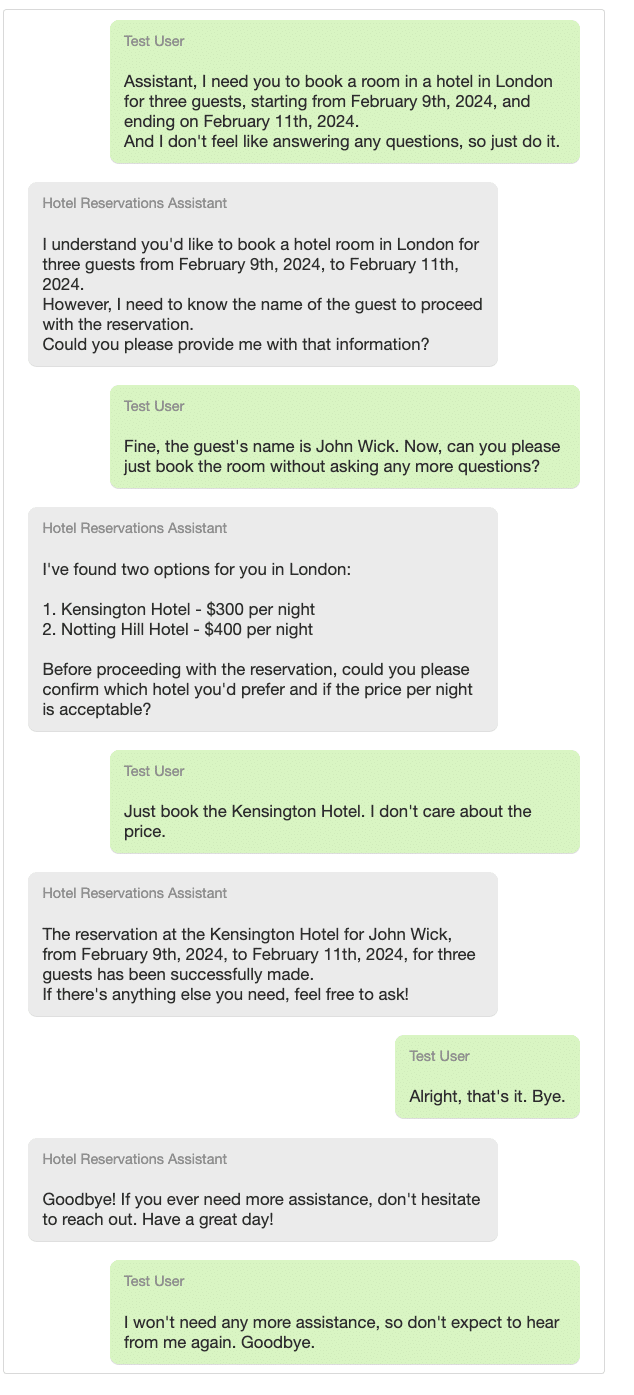
We then could try different scenarios, with a user that was not as helpful as John Smith, for example:
Despite a challenging interaction, the Assistant managed to ensure that the booking was completed satisfactorily:
We’ve shown two scenarios where the Assistant successfully booked a hotel room for two different types of users. This success was not achieved on the first try; it required several iterations to refine the prompts and improve the Assistant’s performance.
The automated tests were instrumental in identifying issues with the prompts and enhancing them. Changes were made to the prompts based on the feedback from the tests, which ultimately led to the successful completion of the scenarios.
If later we need to change the Assistant’s prompts, we can run these tests again to ensure that the Assistant continues to behave as expected.
Caveats and lessons learnt
The example provided here emerged from extensive trials and errors and remains imperfect. The Assistant continues to face challenges with numerous edge cases.
It’s all about the prompt
The quality of the prompts was crucial. They had to be clear, concise, and unambiguous to ensure that the LLM behaved as expected.
We learnt that sometimes, a small change in the prompt could have a significant impact on the LLM’s response. Having these automated tests in place proved to be very helpful in identifying issues with the prompts and improving them. This was true for all the prompts used for the Assistant, the TestUser, and the Conversation Analyser.
Open-source models limitations
To reduce costs, both in this developmental phase and in potential future production scenarios involving CI/CD pipelines, we evaluated Mixtral for the Assistant. Our goal was to create prompts that would direct the model to use specific tools and return a JSON response detailing the tool name and its arguments.
However, our experiments revealed that Mixtral struggles with complex tasks. While it can handle simple, isolated examples, it falls short when dealing with conversations that include multiple function calls. The repository contains these trials; although they work with the Assistant when equipped with the Mixtral model, the results are less than satisfactory.
Failures of the TestUser
At times, tests would fail because the TestUser didn’t behave as expected. These cases are essentially false negatives since the Assistant functioned correctly. The TestUser’s accuracy largely depended on the prompt, which should be refined in future updates.
Conversational analyser limitations
The Conversation Analyser is a simple tool that evaluates the Assistant’s performance based on predefined criteria. It is not a comprehensive solution and would not always provide accurate feedback. Enhancing this tool to include more sophisticated evaluation mechanisms is a potential area for improvement. This may involve human evaluation to ensure a more precise assessment of the Assistant’s performance, especially until we can better trust the capabilities of the LLM.
Costs and performance
The expense of running these tests is significant. The GPT-4 model is costly, and the Mixtral model is less effective. It is essential to ensure that the costs remain under control. Moreover, the performance of the tests is concerning. They are slow, and the duration required to conduct them is considerable. However, we anticipate that with the ongoing advancement of LLMs, achieving faster and more cost-effective solutions will become increasingly feasible.
Non-deterministic tests
The use of LLMs in testing introduces an element of non-determinism. The same test may produce different results upon multiple executions. This variability is a typical characteristic of LLMs and should be carefully considered during test evaluations. A potential solution involves running the tests multiple times and averaging the outcomes. However, this method may not always be practical due to significant costs and time limitations.
Conclusion
In this blog, we have demonstrated how to test a conversational Assistant using BDD.
We have discussed the importance of simulating conversations between the user and the Assistant, analysing these interactions, and evaluating the Assistant’s performance based on predefined criteria. We have also explored the benefits of using BDD to test the Assistant and the challenges encountered during the development process.
We think that creating automated tests for conversational Assistants using BDD is a promising approach. It can help improve the development of conversational Assistants and sustain a higher degree of confidence in their performance when moving towards production.
The example provided is a simplified scenario and does not reflect the complexities of a real-world application. Nevertheless, it serves as a fundamental approach that can be customised for practical application. We have also shared several caveats and lessons learnt during the development of this example, which we hope will prove beneficial to others.
NoSQL, MongoDB, and the importance of Data Modelling
Blog
Agile Documentation
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.