
The importance of observability in MLOps
ML solutions need to be monitored for errors and performance just like any other software solution. ML driven products typically need to meet two key observability concerns:
- Monitoring the model as a software product that includes metrics such as the number of prediction requests, its latency and error rate.
- Monitoring model prediction performance or efficacy, such as f1 score for classification or mean squared error for regression.
Monitoring as a Software Product
As a software product, monitoring can be accomplished using existing off the shelf tooling such as Prometheus, Graphite or AWS CloudWatch. If the solution is created using auto-generated ML this becomes even more important. Model code may be generated that slows down predictions enough to cause timeouts and stop user transactions from processing.
You should ideally monitor:
- Availability
- Request/Response timings
- Throughput
- Resource usage
Alerting should be set up across these metrics to catch issues before they become critical.
Monitoring model prediction performance
ML models are trained on data that’s available at a certain point in time. Data drift or concept drift happens when the input data changes its distributions, which can affect the performance of the model. Let’s imagine we have a user signup model that forecasts the mean basket sales of users for an online merchant. One of the input variables the model depends on is the age of the new users. As we can see from the distributions below, the age of new users has shifted from August to September 2021.
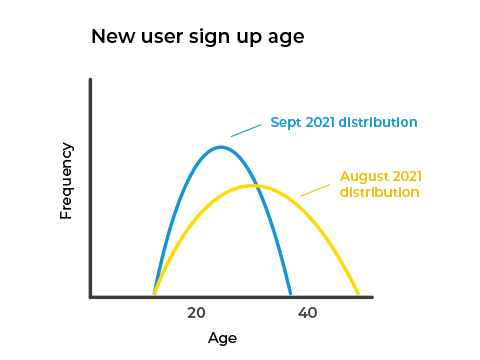
It is important to monitor the live output of your models to ensure they are still accurate against new data as it arrives. This monitoring can provide important cues when to retrain your models, and dashboards can give additional insight into seasonal events or data skew.
There are a number of metrics which can be useful including:
- Precision/Recall/F1 Score.
- Model score outputs.
- User feedback labels or downstream actions
- Feature monitoring (Data Quality outputs such as histograms, variance, completeness).
The right metrics for your model will depend on the purpose of the model and the ability to access the performance data in the right time frame.
Below is an example of a classification performance dashboard that tracks the precision and recall over time. As you can see, the model’s performance is becoming more erratic and degrading from 1st April onwards.
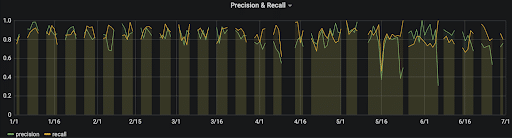
Alerting should be set up on model accuracy metrics to catch any sudden regressions that may occur. This has been seen on projects where old models have suddenly failed against new data (fraud risking can become less accurate as new attack vectors are discovered), or where an auto ML solution has generated buggy model code. Some ideas on alerting are:
- % decrease in precision or recall.
- variance change in model score or outputs.
- changes in dependent user outputs e.g. number of search click throughs for a recommendation engine.
The chart below illustrates that model A’s performance degrades over time. A new challenger model, B, is re-trained on more recent data and becomes a candidate for promotion.
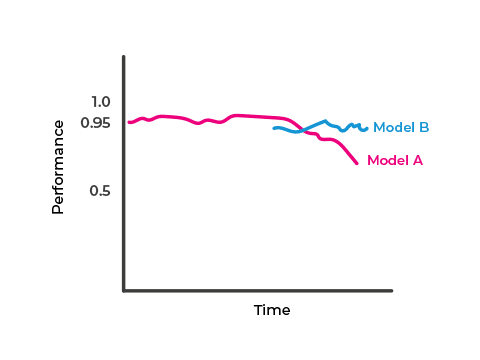
Data Quality
A model is only as good as the data it’s given, so instrumenting the quality of input data is crucial for ML products. Data quality includes the volume of records, the completeness of input variables and their ranges. If data quality degrades, this will cause your model to deteriorate.
To read more about monitoring and metrics for MLOps, download our new MLOps playbook, “Operationalising Machine Learning”, which provides comprehensive guidance for operations and AI teams in adopting best practice.
If you’re new to the world of MLOps, here’s what you need to know: MLOps (which stands for machine learning operations) is a set of tools and ideas that help data scientists and operations teams to develop, deploy and monitor models in the AI world.
That’s a big deal because organisations that want to deliver AI projects often struggle to get projects off the ground at scale, and to deliver effective return on investment (ROI). Using MLOps helps those organisations to create machine learning models in a manner that is effective, consistent and scalable.
Over the last decade, machine learning has become a critical resource for many organisations. Using ML models, companies can create models that can analyse vast quantities of structured and unstructured data, making predictions about business outcomes that can be used to inform faster, better decisions. The challenge, increasingly, is how those organisations monitor and manage multiple ML models and iterations.
MLOps brings discipline and structure to AI
That’s where MLOps comes in. While DevOps focuses on how systems are developed with regard to security, compliance and IT resource management, MLOps focuses on the consistent development of scalable models. Blending machine learning with traditional devops models creates an MLOps process that streamlines and automates the way that intelligent applications are developed, deployed and updated.
Examples of how MLOps is being used include:
- Telecoms – using MLOps systems to manage network operations and customer churn models.
- Marketing – in advertising, MLOps is being used to manage multiple machine learning models in production to present targeted ads to consumers.
- Manufacturing – Using machine learning models to predict asset maintenance needs and identify performance and quality problems.
With MLOps, Data scientists can place models into production, then monitor and record their performance to ensure they’re working well. With MLOps they can also capture information on all ML models in a standard form that allows other teams to use those models or revise them later.
How MLOps can deliver higher ROI
This isn’t just about making life easier. We know that 90% of AI projects fail under current development frameworks. MLOps provides a far more reliable, cost-effective framework for development that can deliver successful projects much more quickly. By adopting MLOps, it becomes easier for organisations to make the leap from small-scale development to large-scale production environments. By increasing the speed and success of ML models being deployed, MLOps can improve the ROI of AI projects.
It’s also worth considering that models – by their nature – need to change. Once an ML model is created and deployed, it generally won’t continue operating in the same way forever. Models need to be constantly monitored and checked, to ensure they’re delivering the right insights and business benefits. MLOps helps data scientists to make faster inventions when models need to be revised – such as during a global pandemic or supply chain crisis – with changes deployed at a faster rate.
If organisations want to adopt MLOps they must first build the relevant skills within data and operations teams. This includes skills such as full lifecycle tracking and a solid AI infrastructure that enables the rapid iteration of new ML models. These will need to support both main forms of MLOps – predictive (charting future outcomes based on past results) and prescriptive (making recommendations for future decisions).
Need more guidance?
The key thing to understand about MLOps is that it can’t guarantee success, but it will lower the cost of experimentation and failure.
Ensuring you get the best results from MLOps isn’t always easy, and our MLOps Playbook is a good place to start for guidance on how to maximise the ROI and performance of models in your organisation. The playbook outlines the basic principles of effective MLOps, including creating solid data foundations, creating an environment where data scientists can create and the pitfalls to avoid when creating MLOps practices.
Our experience of working on AI and ML projects means that we understand the importance of establishing best practices when using MLOps to test, deploy, manage and monitor ML models in production.
Considering that 87% of data science projects never make it into production, it’s vitally important that AI projects have access to the right data and skills to solve the right problems, using the right processes.
Below, we outline six fundamental principles of MLOps that should be at the heart of your AI strategy.
1 – Build solid data foundations
Your data scientists will need access to a store of good quality, ground-truth (labelled) historical data. ML models are fundamentally dependent on the data that’s used to train them, and data scientists will rely on this data for monitoring and training.
It’s common to create data warehouses, data lakes or lake houses with associated data pipelines to capture this data and make it available to automated processes and data teams. Our data pipeline playbook covers our approach to providing this data. Make sure to focus on data quality, security, and availability.
2 – Provide an environment that allows data scientists to create
Developing ML models is a creative, experimental process. Data scientists need a set of tools to explore data, create models and evaluate their performance. Ideally, this environment should:
- Provide access to required historical data
- Provide tools to view and process the data
- Allow data scientists to add additional data in various formats
- Support collaboration with other scientists via shared storage or feature stores
- Be able to surface models for early feedback before full productionisation
3 – ML services are products
ML services should be treated as products, meaning you should apply the same behaviours and standards used when developing any other software product.
For example, when building ML services you should identify and profile the users of a service. Engaging with users early in the development process means you can identify requirements that can be built into development, while later on, users can help to submit bugs and unexpected results to inform improvements in models over time.
Developers can support users by maintaining a clear roadmap of features and improvements with supporting documentation, helping users to migrate to new versions and clearly explaining how versions will be supported, maintained, monitored and (eventually) retired.
4 – Apply continuous delivery of complex ML solutions
ML models must be able to adapt when the data environment, IT infrastructure or business needs change. As with any working software application, ML developers must adopt continuous delivery practices to allow for regular updates of models in production.
We advise that teams should use techniques such as Continuous Integration and Deployment (CI/CD), utilise Infrastructure as Code and work in small batches to have fast, reasonable feedback.
5 – Evaluate and monitor algorithms throughout their lifecycle
It’s essential to understand whether algorithms are performing as expected, so you need to measure the accuracy of algorithms and models. This will add an extra layer of metrics on top of your infrastructure resource measurements such as CPU and RAM per Kubernetes pod. Data scientists are usually best placed to identify the best measure of accuracy in a given scenario, but this must be tracked and evaluated throughout the lifecycle, including during development, at the point of release, and in production.
6 – MLOps is a team effort
What are the key roles within an MLOps team? From our experience we have identified four key roles that must be incorporated into a cross-functional team:
- Platform/ML engineers to provide the hosting environment
- Data engineers to create production data pipelines
- Data scientists to create and amend the model
- Software engineers to integrate the model into business systems
Remember that each part of the team has a different strength – data scientists are typically strong at maths and statistics, while they may not have software development skills. Engineers are often highly-skilled in testing, logging and configuration, while data scientists are focused on algorithm performance and accuracy.
At the outset of your project consider how your team roles can work together using clear, defined processes. What are the responsibilities of each team member, and does everyone recognise the standards and models that are expected?
To learn more about MLOps principles and driving better, more consistent best practices in your MLOps team, download our Operationalising Machine Learning Playbook for free.
Despite huge adoption of AI and machine learning (ML), many organisations are still struggling to get ML models into production at scale.
The result is AI projects that stall, don’t deliver ROI for years, and potentially fail altogether. Gartner Group estimates that only half of ML models ever make it out of trials into production.
Why is this happening? One of the biggest issues is that companies develop successful ML prototype models, but these models aren’t equipped to be deployed at scale into a complex enterprise IT infrastructure.
All of this slows down AI development. Software company Algorithmia recently reported that most companies spend between one and three months deploying a new ML model, while one in five companies took more than three months. Additionally, 38% of data scientists’ time is typically spent on deployment rather than developing new models.
Algorithmia found that these delays were often due to unforeseen operational issues. Organisations are deploying models only to find they lack vital functionality, don’t meet governance or security requirements, or need modification to provide appropriate tracking and reporting.
How MLOps can help
Enter MLOps. While MLOps leverages DevOps’ focus on compliance, security, and management of IT resources, MLOps add much more emphasis on the consistent development, deployment, and scalability of models.
Organisations can accelerate AI adoption and solve some of their AI challenges by adopting MLOps. Algorithmia found that where organisations were using MLOps, data scientists were able to reduce the time spent on model deployment by 22%, and the average time taken to put a trained model into production fell by 31%.
That’s because MLOps provides a standard template for ML model development and deployment, along with a clear history and version control. This means processes don’t need to be reinvented for each new model, and standardised processes can be created to specify how all models should meet key functional requirements, along with privacy, security and governance policies.
With MLOps, data teams can be confident that new code and models will meet architecture and API requirements for production usage and testing. By removing the need to create essential features or code from scratch, new models are faster to build, test, train and deploy.
MLOps is being widely used for tasks such as automation of ML pipelines, monitoring, lifecycle management and governance. MLOps can be used to monitor models to sense any fall in performance or data drifts that suggest models might need to be updated or retrained.
Having a consistent view of ML models throughout the lifecycle in turns allows teams to easily see which models are live, which are in development, and which require maintenance or updates. These can be scheduled more easily with a clear overview of the ML landscape.
Within MLOps, organisations can also build feature stores, where code and data can be re-used from prior work, further speeding up the development and deployment of new models.
Learn more about MLOps
Our new playbook, Operationalising Machine Learning, provides guidance on how to create a consistent approach to monitoring and auditing ML models. Creating a single approach to these tasks allows organisations to create dashboards that provide a single view of all models in development and production, with automated alerts in case of issues such as data drift or unexpected performance issues.
If you’re struggling to realise the full potential of machine learning in your organisation, the good news is that you’re not alone. According to industry analysts VentureBeat, 87% of AI projects will never make it into production.
MLOps emerged to address this widespread challenge. By blending AI and DevOps practices, MLOps promised smooth, scalable development of ML applications.
The bad news is that MLOps isn’t an immediate fix for all AI projects. Operationalsing any AI or machine learning solution will present its own challenges, which must be addressed to realise the potential these technologies offer. Below we’ve outlined five of the biggest MLOps challenges in 2022, and some guidance on solving these issues in your organisation.
You can read about these ideas in more detail in our new MLOps playbook, “Operationalising Machine Learning”, which provides comprehensive guidance for operations and AI teams in adopting best practice around MLOps.
Challenge 1: Lack of user engagement
Failing to help end users understand how a machine learning model works or what algorithm is providing an insight is a common pitfall. After all, this is a complex subject, requiring time and expertise to understand. If users don’t understand a model, they are less likely to trust it, and to engage with the insights it provides.
Organisations can avoid this problem by engaging with users early in the process, by asking what problem they need the model to solve. Demonstrate and explain model results to users regularly and allow users to provide feedback during iteration of the model. Later in the process, it may be helpful to allow end users to view monitoring/performance data so that you can build trust in new models. If end users trust ML models, they are likely to engage with them, and to feel a sense of ownership and involvement in that process.
Challenge 2: Relying on notebooks
Like many people we have a love/hate relationship with notebooks such as Jupyter. Notebooks can be invaluable when you are creating visualisations and pivoting between modelling approaches.
However, notebooks contain both code and outputs, along with important business and personal data, meaning it’s easy to inadvertently pass data to where it shouldn’t be. Notebooks don’t lend themselves easily to testing, and cells that can run out of order means that different results can be created by the same notebook based on the order that cells are run in.
In most cases, we recommend moving to standard modular code after creating an initial prototype, rather than using notebooks. This results in a model that is more testable and easier to move into production, with the added benefit of speeding up algorithm development.
Challenge 3: Poor security practice
There are a number of common security pitfalls in MLOps that should be avoided, and it’s important that organisations have appropriate practices in place to ensure secure development protocols.
For example, it’s surprisingly common for model endpoints and data pipelines to be publicly accessible, potentially exposing sensitive metadata to third parties. Endpoints must be secured to the same standard as any development to avoid cost management and security problems caused by uncontrolled access.
Challenge 4: Using Machine Learning inappropriately
Despite the hype, ML shouldn’t always be the default way to solve a problem. AI and ML are essentially tools that help to understand complex problems like natural language processing and machine vision.
Applying AI to real-world problems that aren’t like this is unnecessary, and leads to too much complexity, unpredictably and increased costs. You could build an AI model to predict whether a number is even or odd – but you shouldn’t.
When addressing a new problem, we advise businesses to try a non-ML solution first. In many cases, a simple, rule-based system will be sufficient.
Challenge 5: Forgetting the downstream application of a new model
Achieving ROI from machine learning requires the ML model to be integrated into business systems, with due attention to usability, security and performance.
This process becomes even longer if models are not technically compatible with business systems, or do not deliver the expected level of accuracy. These issues must be considered at the start of the ML process, to avoid delays and disappointment.
A common ML model might be used to predict ‘propensity to buy’ – identifying internet users who are likely to buy a product. If this downstream application isn’t considered when the model is built, there is no guarantee that the data output will be in a form that can be used by the business API. A great way to avoid this is by creating a walking skeleton or steel thread (see our Playbook for advice on how to do this).
Find out more about these challenges and more in our new Operationalising Machine Learning Playbook, which is available to read here.