This blog describes the exploration that Cláudio Dinizand I have been doing around the dbt tool, trying to find a way to write unit tests using TDD. You can check this post to understand how it all started.
This is not a tutorial on dbt, and it’s not a detailed technical document on our framework. You can check our demo dbt project here if you want to see the details.
Note: What we are calling a framework is a set of Jinja macros. Throughout this document, we will call it a framework for simplicity.
Why do we need unit tests in dbt?
One of the software engineering practices that we follow is TDD. We strongly believe that it helps us create better code and achieve a good level of confidence in its correctness. So, why not use this in our dbt projects?
Dbt is code
A dbt project, like a “regular” software project, consists of several files of SQL code. And we want to be sure that the logic of this code is correct before it jumps to production.
We think that using TDD can also help us to write better SQL code. Using TDD, we write the test, make it pass with the simplest SQL code we can think of, and then refactor it, knowing we have a test to assure it still works. It would be awesome if we could do this on our dbt projects!
But wait, dbt already has tests
That’s right, but dbt tests were mainly designed for data tests. They are used to check the correctness of the data produced by the models. We want to write unit tests on our SQL code. We want to be sure that the logic of the code is correct.
A word on unit tests
The line between unit and integration tests is sometimes a bit blurred. This is also true with these tests in dbt.
We can think of a dbt model as a function, where the inputs are other models, and the output is the result of its SQL. A unit test in dbt would be a test where we provide fake inputs to a model, and then we check the results against some expectations.
However, a model in dbt can belong to a long chain of models (see image below), each transforming the data in its own rules. We could test a model by providing fake inputs to the first models in that chain and asserting the results on the final model. We would be checking all the intermediate transformations along the way. This, on the other end, could be called an integration test.
A complex dbt model hierarchy
These integration tests are harder to write because we have to think of how the data is transformed throughout all those models until it reaches the model we want to test. However, they provide an extra level of confidence. As usual, we need to keep a good balance between these two types of tests.
As we will see, using this definition, our framework will allow us to create both unit and integration tests.
What do you want to achieve?
We came up with a list of requirements that we would like to fulfill when writing tests in dbt:
Use fake inputs on any model
Focus the test on what’s important
Provide fast and valuable feedback
Write more than one test on a dbt test file
We want to write dbt tests using TDD and receive fast feedback on the results. Running one or more dbt models each time we change them, as we were doing on the previous approach, was not the best way to do it, and we wanted to remove this step.
The goal is to write the test, write the model, and then run the test (with “dbt test”).
Use fake inputs on any model.
In a typical dbt model hierarchy, a model is dependent on other models.
We can test our models by providing fake inputs to its “parent” models. However, sometimes we want to go a bit higher in the hierarchy (up to the sources, if we wish to) to have a more integratedtest.
Focus the test on what’s important
We want to test our models by providing fake input only to the relevant models for the scenario being tested. It should be possible to keep other models with no data as long as they don’t interfere with the test (for instance, when using a LEFT JOIN on some model).
It is also essential that we shouldn’t have to specify all the columns when we provide fake input data. Only the columns that are important for the test should be set.
Provide fast and valuable feedback
We want the test feedback to be fast and helpful. We need to understand which test is failing and why. It should present the name of the model that failed along with its description.
Write more than one test on a dbt test file
A dbt test file usually contains just one test. It would be nice to have more than one test on the same file if they are somehow related.
How did you do it?
In a word, with some pain (two words, I know…). Many experiments and iterations were developed and tested until we reached the state where we are now. Fortunately, the powerful Jinja macros and the dbt engine helped us achieve what we were looking for.
Before we run into the details of how it is done, let’s have a look at how a test looks like:
In a nutshell:
First, we define the model to be tested with the “test” macro.
Then we define the fake inputs using the “mock_ref” or “mock_source” macros.
Finally, we describe our expectations for the model with the “expect” macro.
That’s it!
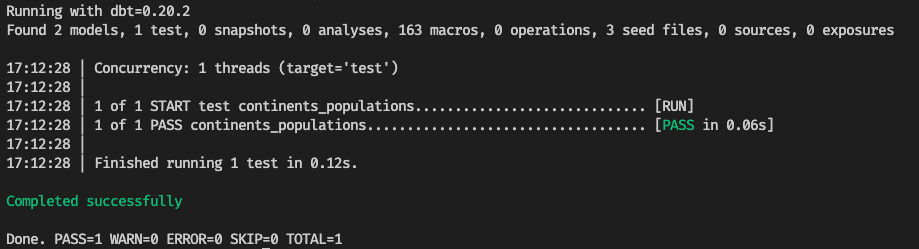
If we now run this test with the “dbt test” command (assuming we have a “covid19_cases_per_day” model), we will see this report:
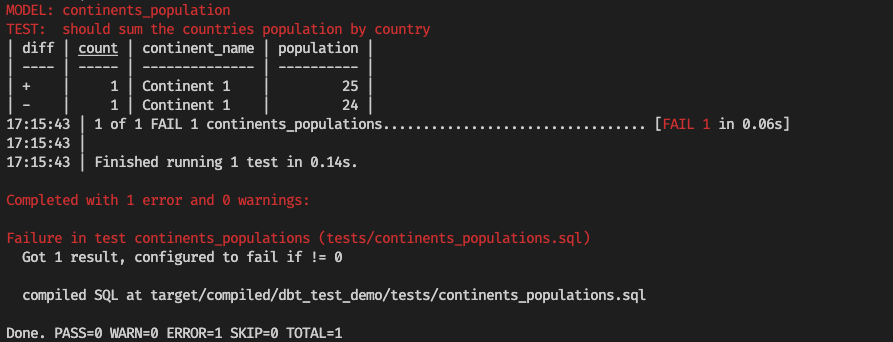
Now imagine we made a mistake and typed 24 instead of 25 on the expectations. We rerun the test, and now we see the test failing:
The test output displays the name of the model being tested and the description of the test. This is helpful when we have several tests running with the “dbt test” command.
How does it work?
Our strategy is supported by these four items:
The dbt “render” function.
The dbt “graph.nodes” internal structure.
SQL Common Table Expressions (CTE).
The ability to override the dbt “ref” macros functionality.
Let’s check one by one:
1. The dbt “render” function
This function returns the compiled SQL for a model. It allows us to fetch the SQL of the model being tested and the SQL for all the other models.
2. The dbt “graph.nodes” internal structure
This structure keeps track of a lot of information related to each of the dbt models in runtime. It contains the raw SQL for the model (the SQL before compilation, with the ref and other dbt macros) and the list of models from which this one depends (it contains a lot of different things, but they are not essential for us right now).
3. SQL Common Table Expressions (CTE)
We use CTEs to build a fully compiled SQL of the model being tested. The dependencies of the model are transverse recursively to generate a group of nested CTEs that builds up the entire model.
4. The ability to override the dbt ref macro functionality
We can override the ref macro on dbt. This allows us to change the default behavior of emitting a fully qualified table name, like “dbt_test_demo.models.countries”, to a simplified one that will match the name of the CTEs.
Let’s see an example. Imagine we have the following (oversimplified and dumb) 3 models:
If we are testing “model3”, our framework builds the following SQL:
Notice how the SQL for “model3” now depends only on the CTEs defined before the final SELECT. This will be the SQL that dbt will execute when running the test and later compare its results with the expectations.
What about fake inputs?
Good question. We need to be able to inject our fake inputs into this SQL. How? Again, using CTEs.
Suppose we want to insert fake inputs on “model2”. And assume we don’t care about “model1” because it’s on a LEFT JOIN, and our test does not depend on “model1” columns. So we don’t need to define fake inputs for this model (focus the test on what’s important).
The SQL for “model3” defined above is wrapped with a CTE to define the fake inputs for “model2”, like this:
However, this wouldn’t work. There are two CTEs named “model2” in this SQL, and the model being tested will use the innermost one and not the one that defines the fake inputs. An extra step is needed to remove from the model SQL the CTEs used as faked inputs.
The final SQL will then be:
Now the fake inputs for “model2” will be used in the test.
(this is a simplified version of the actual SQL used for testing. For instance, a few extra steps are necessary to prevent the need to specify all the columns in the fake inputs. We simplified it here for explanation purposes)
More than one test on the same file
It’s possible to specify more than one test on a single dbt test file. We just need to join all the tests with a UNION ALL statement:
The test output will show which tests have failed, along with their name and description.
What about the cons?
Nothing comes for free. Using this framework has its downsides.
The first one would be a slightly more complicated syntax to describe our tests. We did our best to keep it as simple and straightforward as possible, but the level of boilerplate is still a bit high.
We are relying on some dbt internal details. The dbt render function is not documented. If it changes in the future, it could break our framework. (We have this response from the dbt team saying that this is very unlikely to happen).
Conclusion
We are always trying to improve, and there is still some space for improvements here. Currently, our macros are running against a BigQuery database. We know we need to change a few things to make them compatible with Postgres, for instance.
All in all, we can create our dbt tests comfortably, using TDD with fast feedback, and we are gaining confidence in the correctness of our models.
If you want to learn more about the technical details of how this works, you can check our dbt test demo project on Github.
We hope we are helping other teams to write unit tests for dbt projects.
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.