
Bringing TDD to the Data Warehouse
As a follow-up from Language Agnostic Data Pipelines, the following post is focused on the use of dbt (data build tool).
Dbt is a command-line tool that enables us to transform the data inside a Data Warehouse by writing SQL select statements which represent the models. There is also a paid version with a web interface, dbt cloud, but for this article let’s consider just the command-line tool.
The intent of this article is not to make a tutorial about dbt – that already exists here, nor one about TDD, the goal is to illustrate how one of our software development practices, test-driven development, can be used to develop the dbt models.
Testing strategies in dbt
Dbt has two types of tests:
- Schema tests: Applied in YAML, returns the number of records that do not pass an assertion — when this number is 0, all records pass and therefore your test passes.
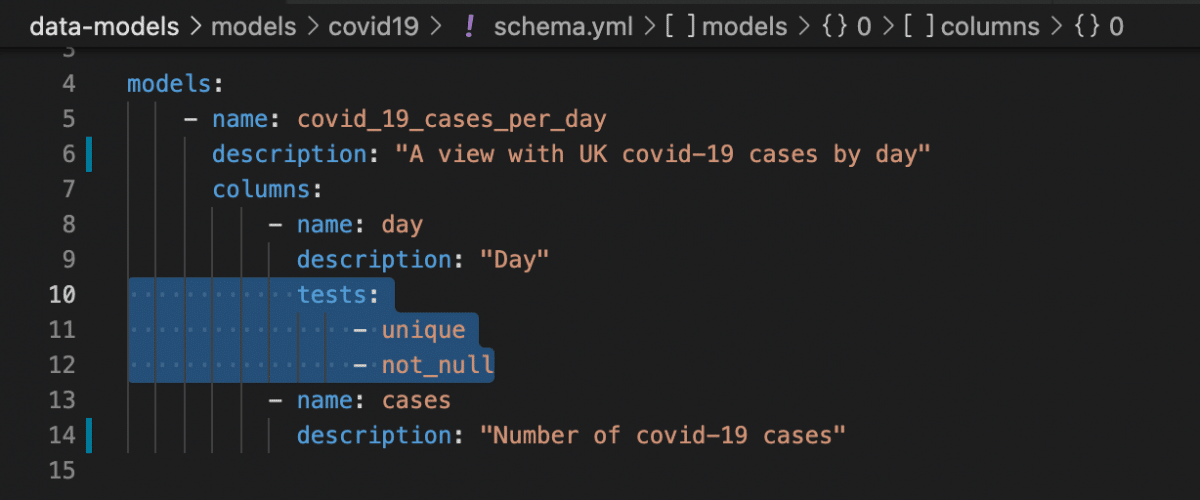
- Data tests: Specific queries that return 0 records.

Both tests can be used against staging/production data to detect data quality issues.
The second type of test gives us more freedom to write data quality tests. These tests run against a data warehouse loaded with data. They can run on production, on staging, or for instance against a test environment where a sample of data was loaded. These tests can be tied to a data pipeline so they can continuously test the ingested and transformed data.
Using dbt data tests to compare model results
With a little bit of SQL creativity, the data tests (SQL selects) can be naively* used to test model transformations, comparing the result of a model with a set of expectations:
with expectations AS ( select 'value' as column1, union all Select 'value 2' as column1 ) select * from expectations except select * from analytics.a_model
The query returns results when the expectations differ, so in this case dbt reports a test failure. However, this methodology isn’t effective to test the models due to the following facts:
- The test input is shared among all the tests (this could be overcome by executing dbt test and the data setup for each test, although it’s not practical due to the lack of clarity and the maintainability of test suites).
- The test input is not located inside the test itself, so it’s not user friendly to code nor easy to understand the goal of each test.
- The dbt test output doesn’t show the differences between the expectations and the actual values, which slows down the development.
- For each test, we need to have a boilerplate query with the previous format (with expectations as…).
Considering these drawbacks, It doesn’t seem like the right tool to make model transformation tests.
A strategy to introduce a kind of ‘data unit tests’
It’s possible and common to combine SQL with the templating engine Jinja (https://docs.getdbt.com/docs/building-a-dbt-project/jinja-macros). Also, It’s possible to define macros which can be used to extend dbt’s functionalities. That being said, let’s introduce the following macro:
unit_test(table_name, input, expectations)
The macro receives:
- A table name (or a view name).
- An input value that contains a set of inserts.
- A table of expectations.
To illustrate the usage of the macro, here is our last test case refactored:
{% set table_name = ref('a_model') %} {% set input %} insert into a_table(column1) values (‘value’), (‘value2’); {% endset %} {% set expectations %} select 'value' as column1, union all select 'value 2' as column1 {% endset %} {{ unit_test(table_name, input, expectations) }}
There is some boilerplate when using Jinja to declare the variables to call the unit test macro. Although, it seems a nice tradeoff, because this strategy enables us to:
- Simplify the test query boilerplate.
- Setup input data in plain SQL and in the same file.
- Setup expectations in plain SQL and in the same file.
- Run each test segregated from other tests.
- Show differences when a test fails.
To illustrate the usage of this approach, here is a demo video:
The previous macro will be available in the repo published with the Language Agnostic Data Pipelines.
*naively coded because the use of EXCEPT between both tables fails to detect if duplicate rows exist. It could be fixed easily, but for illustrative purposes, we preferred to maintain the example as simple as we can.
Bringing software engineering practices to the data world
It is also easy to apply other standard software development practices such as integration with a ci/cd environment in dbt. This is one of the advantages of using it over transforming data inside ETL tools which use a visual programming approach.
Wrapping up, we advocate that data oriented projects should always use the well-known software engineering best practices. We hope that this article shows how you can apply TDD using the emerging DBT data transformation tool.
Pedro Sousa paired on this journey with me. He is taking the journey from software engineering to data engineering in our current project, and he helped on the blog post.
Contact us!
For more information on data pipelines in general, take a look at our Data Pipeline Playbook. And if you’d like us to share our experience of data pipelines with you, get in touch using the form below.
Whatever your role, you might come into contact with a data warehouse at some point. They’re incredibly powerful tools that I’ve frequently seen ignored or used in ways that cause problems. In this post, I’ll share a few tips for handling data in your data warehouse effectively. Whilst the focus here is helping data scientists, these tips have helped other tech professionals answer their own data questions and avoid unnecessary work, too.
Gaps in traditional data science training
Traditional data science training focuses on academic techniques, not practicalities of dealing with data in the real world. The odds are you’ll learn five different ways to perform a clustering, but you’ll not write a test or a SQL query.
Fresh data scientists, landing in their first professional roles, can find that the reality of data science is not what they expected. They must deal with messy and unreliable terabyte-scale datasets that they can’t just load into a Pandas or R dataframe to clean and refine. Their code needs to run efficiently enough to be useful and cost-effective. It needs to run in environments other than their laptop, robustly interact with remote services and be maintained over time and by other people.
This mismatch between training, expectation and reality can cause real problems*. At one end of the scale, you get data scientists producing code that needs to be “productionised” (well, rewritten) – by “data engineers” to be fit for its real-world purpose. At the scarier end of the scale you get data science time investments that have to be thrown in the bin because a couple of early mistakes mean it just doesn’t work in practice.
(* this blog post isn’t about the other big expectation mismatch – how you’ll likely be spending a good chunk of your time doing pretty basic things like writing simple reports, not the cool data science stuff… sorry )
Data science training is adapting to make more room for practical skills. Here’s a few tips to avoid making mistakes I’ve helped fix for fresh and seasoned data scientists out there in the field today.
Use your data warehouse effectively
There’s a good chance that your data science is applied to data that came from a SQL-based analytics system like Google BigQuery, AWS Redshift, Azure Analytics, Snowflake or even Spark SQL. These systems are engineered to efficiently answer complex queries against big datasets, not to serve up large quantities of raw data. You might be able to:
SELECT * FROM client_transactions
…streaming out fifty columns by ten million rows to find the top ten clients by spend in Pandas, but it’ll be an awful lot faster and more robust if you do more work in the data warehouse and retrieve just the ten rows and two columns you’re really interested in:
SELECT client_id, SUM(transaction_value) total_spend FROM client_transactions GROUP BY client_id ORDER BY total_spend DESC LIMIT 10
As the table you’re accessing grows, the benefits of doing the work in the data warehouse will too.
I recall working with a data scientist, fresh out of university, who did not want to learn SQL and took the former approach. It worked well enough while the product was in development and soft launch. Three months after public launch, they were trying to download tens of gigabytes of data from the data warehouse. We ran out of hardware and networking options to keep the complex analytics pipeline they had built on their laptop running and it ground to an undignified halt.
Often, some of the work has to be done in your code outside the data warehouse. These tips encourage you to do as much of the work as you can in your data warehouse before you pull just what you need out to process in your code. Modern data warehouses are capable of doing more right there in the warehouse, including building machine learning models.
We’ll focus on SQL for the next few tips as it’s so prevalent, but similar principles and capabilities are often available in whatever data storage and parallel processing capability you are using. The tips apply in principle to any query language, so you may be able to apply some of them when working with systems like Neo4J or MongoDB. I’ll typically refer to Google’s BigQuery data warehouse, as I find it has excellent SQL feature coverage and the documentation is clear and well-written.
Tip 1: Learn and use the query language
SQL has been around for a long time – even older than I have (just). The foundations were laid back in 1970. It’s an enormously expressive and powerful language. You can probably do more than you think with it, and making the effort to try and push as much work as you can into the database, building your SQL knowledge as you go, will pay dividends quickly. You get the added bonus that non-data scientists could understand and be able to help with your queries, as SQL is commonly used by other data folk that perform analytics and reporting functions.
There’s a lot more power and flexibility in modern SQL than the basic SELECT, WHERE, and GROUP BY would suggest. Every database has a query optimiser that looks at your query and statistics about the tables involved before selecting a strategy to answer most efficiently. Self-joins, nested columns, STRUCT types, user-defined functions and window or analytic functions are a few capabilities common to many data warehouses that I’ve found very helpful in expressively solving trickier problems, and they are less-well known amongst data scientists.
I found the first couple of paragraphs in BigQuery’s window function documentation provided a really useful mental model of what they are, how they differ from normal aggregations and when they might be useful.
Once you start using SQL, you’ll find yourself writing larger and more complex queries. Let’s talk about how you can control that complexity and keep your queries manageable.
Tip 2: Use common table expressions
You can think of Common Table Expressions (CTEs) as virtual tables within your query. As your simple query becomes more complex, you might be tempted to bolt together multiple sub-queries like this:
SELECT a, b, c FROM (SELECT ...) INNER JOIN (SELECT ...)
This will work, and I’ve seen plenty of queries done this way. They can easily grow into SQL behemoths hundreds of lines long that are really difficult to understand and reason about. The sub-queries are a big part of the problem, nesting complex logic inside other queries. Instead of creating a large, monolithic query, you can pull out those complex queries into CTEs and give them meaningful names.
WITH clients AS (SELECT ....), transactions AS (SELECT …) SELECT a, b, c FROM clients INNER JOIN transactions
Now you can see what that query is all about. As well as making your queries easier to understand, breaking up a large query like this means you can query the CTEs to see what they are producing while you develop and debug your query. Here is a more in-depth tutorial on CTEs.
Equal Experts Associate Dawid du Toit highlights one thing to watch out for when using CTEs. If you use the CTE multiple times during your query (for example, a self-join from the CTE back onto itself) you may find the CTE evaluated twice. In this, materializing the data into a temporary table may be a better option if the cost of the query is a significant concern.
Tip 3: Use views
So you’ve started using CTEs and you’re writing much more expressive queries. Things can still become complicated, and it’s not always convenient to change your query to inspect your CTEs – for example, when your query is running out there in production and can’t be modified.
Once you’ve got a CTE, it’s straightforward to convert into a database view. A view is just a query you define in the database, so you can just take your CTE and wrap it in a CREATE VIEW statement. You can then use the view as if it were a table – which means you can query it and inspect the data it contains at any time without modifying your deployed queries.
Views are usually heavily optimised and don’t have to introduce any performance or cost penalty. For example, implementing “predicate pushdown” allows a data warehouse to optimise the data and computation the view uses based on how it is queried – as if the view was just part of the query.
Views are logical infrastructure, and lend themselves to deployment with an “infrastructure as code” mindset the same way as we might deploy a server or the database itself.
CREATE VIEW clients AS (SELECT ....); CREATE VIEW transactions AS (SELECT …);
Then, we can use these views in queries, whether executed ad-hoc or as part of a data pipeline.
SELECT a, b, c FROM clients INNER JOIN transactions
Database views provide a much more flexible interface to underlying tables. The underlying data will eventually need to change. If consumers access it through views, the views can adapt to protect those consumers from the change, avoiding broken queries and irate consumers.
Views are also a great way to avoid data engineering complexity. I’ve seen plenty of complex data processing pipelines that populate tables with refined results from other tables, ready for further processing. In every case I can recall, a view is a viable alternative approach, and it avoids managing the data in intermediate tables. No complex data synchronisation like backfilling, scheduling or merging challenges here! If your data warehouse supports it, a materialized view can work where there are genuine reasons, such as performance or cost, to avoid directly querying the source table.
Tip 4: Use user defined functions
Databases have supported User Defined Functions (UDFs) for a long time. This useful capability allows you to capture logic right in the database, give it a meaningful name, and reuse it in different queries. A simple example of a UDF might parse a list from a comma-separated string, and return the first element. For example, given a function like this (using the BigQuery SQL dialect)
CREATE FUNCTION my_dataset.get_first_post(post_list STRING) RETURNS STRING AS ( SPLIT(post_list, ',')[SAFE_OFFSET(0)] )
Specify the return type of your query, even if it can be inferred. That way, you’ll know if you’re returning something totally different to what you expected.
We can use the function in other queries:
WITH post_lists AS (
SELECT ‘a,b,c,d’ AS post_list
)
SELECT
post_list,
my_dataset.get_first_post(post_list) first_post
FROM post_lists
The result would be as follows:
| post_list | first_post |
| a,b,c,d | a |
The benefits might not be clear from this simple function, but I recently implemented a Levenshtein Distance function using BigQuery’s JavaScript UDF capability, allowing us to find likely typos in a large dataset in the data warehouse.
Dawid recalls seeing UDFs that take a parameter which then go and query another table. This can completely kill your query performance, for example, where you could just have just joined with the other table. Be wary of using UDFs in this way!
A benefit that might not be immediately obvious is that you can deploy a fix or improvement to your UDF and all queries using it pick up the change when they are next executed. Be aware that there may be little of the structural flexibility you might be used to in other programming languages. For example, you might not be able to “overload” a UDF to handle an additional argument, nor can you provide a default value to an argument.
These limitations can make handling change even harder than in other languages – but I’ve found it’s still a big improvement over copying and pasting.
Tip 5: Understand what’s efficient
Doing your number-crunching in your data warehouse is likely to be the most cost-efficient place to do it. After all, modern data warehouses are really just massively parallel compute clusters.
There are typically ways to make your processing more efficient – which always means cheaper and usually means faster. For example, a clickstream table might stretch back five years and be 150Tb in total size. Partitioning that table by the event date means that the data warehouse can just scan yesterday’s data rather than the whole table to give you a total of some metric for yesterday – so long as you construct your query to take advantage of it. In this case, it’s likely as straightforward as ensuring your query WHERE clause contains a simple date constraint on the partition column.
Understanding how your data warehouse is optimised (or how to optimise it, if you’re setting up the table), can make a real difference to your query performance and cost.
Writing better SQL, faster
As you gain competency in writing SQL (or any language), you’ll find your queries and programs becoming more complex. That will make tracking down problems more difficult. Here’s a few tips to help you find and squash your bugs more easily, be more confident that your code does what it’s supposed to, and avoid the problems in the first place!
Tip 6: Test your UDFs
You can quite easily test your UDFs. Here’s a cut-down version of the query I wrote to test that Levenshtein distance function I mentioned earlier:
--- create a virtual table of function inputs and expected outputs, via a CTE WITH examples AS ( SELECT 'kittens' AS term_1, 'mittens' AS term_2, 1 AS expected UNION ALL SELECT 'kittens', 'kittens', 0 ) --- create a new CTE that injects the actual outputs from the function , test AS ( SELECT *, my_dataset.levenshtein_distance(term_1, term_2) actual FROM examples ) SELECT *, IF(TO_JSON_STRING(actual) = TO_JSON_STRING(expected), 'pass', 'fail') result FROM tes
Results:
| term_1 | term_2 | expected | actual | result |
| kittens | mittens | 1 | 1 | pass |
| kittens | kittens | 0 | 0 | pass |
If the query produces any rows that do not contain ‘pass’ in the result column, we know that there was an issue – that the actual function output did not match our expectation.
Although not needed for these examples, I typically use a function like
TO_JSON_STRINGthat “stringifies” the expected and actual content in a deterministic manner so that structured values and NULL are compared correctly. Be aware that the documentation for TO_JSON_STRING does not guarantee deterministic order of keys in STRUCTs, but I’ve seen no problems in practice.
Tests have one more huge benefit that might not be immediately obvious. When you do data science for an organisation, it’s likely that someone else will one day need to understand your work. They might even need to make changes. Having some runnable tests means that both of those things will be easier, and that person will be much more likely to think fondly of you.
Tip 7: Test your views
Your views will depend on tables, and as you use these techniques you’ll find that you end with views that depend on other views. It’s handy to know that your views actually do what they are supposed to. You can test views in a similar fashion to UDFs, but it is a little more involved because unlike a UDF, a view must explicitly refer to the tables or views that provide the data it uses.
I have rolled my own testing solutions for these networks of views before. You can create test data, for example in the form of CSV files, that you upload to temporary tables. You can then create a temporary version of your views that use these tables with known, fixed content. The same testing approach outlined for UDFs can now check that your views produce the right data, for the same benefits!
A templating engine like Jinja templates and envsubst can provide a relatively straightforward way to change values in queries and views that vary between environments using environment variables. A query containing
{{my_dataset}}.tablecan be adjusted totest.my_tablein the test environment andprod.my_tablein production.
Tip 8: Use dbt
I’ll also mention some tooling here. We’ve found dbt quite effective for managing networks of views, like those described above. It directly supports flexible references for source views and tables, provides built-in data and view testing capabilities and can even generate documentation, as in this example. Dataform is an alternative providing similar capabilities. Given that it’s recently been acquired by Google, it’ll likely be making an appearance as part of GCP soon, (thanks to Equal Experts Associate Gareth Rowlands for pointing this out!)
Data Studio team member Cláudio Diniz has also been using dbt. You can find more details in his post and the related example Github repo.
Tip 9: Your time is valuable
Organisations often promote directives to save costs wherever possible. It’s not the first time I’ve come across posters, screens and mailshots for employees that remind staff to think about how much things cost and save every penny they can. In principle, that’s a great directive. Unfortunately, it can create focus on small costs that are easy to quantify at the expense of larger costs that are more obscure.
It’s great to create focus on a query that would process 10Tb but could execute for 1/1000th that cost with the addition of a WHERE clause that takes advantage of partitioning. Why not save easy money?
On the other hand, I’ve seen occasions when hours or days of work are invested to make a query more efficient, perhaps saving 2p per day at the expense of – let’s be conservative – two days of a data scientists’ time. At an average salary of £50k, that means we’re looking at a £400 investment to save £7.30 per year – and we’re ignoring the opportunity cost that your time could be spent working on something else.
This is a naive estimate. How much you cost your company is complicated. I’m using the gross salary as an estimate of employee cost. I think the true cost of a typical employee to a typical company is still likely to be higher than the gross salary after factors like tax breaks and equipment costs are taken into account.
Don’t forget to consider what your time is worth!
Bonus Tip: Google it!
The last tip I’d share with you is to check for existing solutions before you build it yourself. The odds are that the problem you are thinking about isn’t novel – others have likely come across that problem before. If you’re lucky, you’ll be able to understand and use their solution directly. If not, you’ll learn about someone else’s experience and you can use that to inform your solution.
Reading about a solution that didn’t work is a lot quicker than inventing it and discovering that it doesn’t work yourself.
The end…?
If you got this far, thanks for reading this post! I hope some of the tips here will be useful.
There’s more to productive data science than effective use of your data warehouse, so watch this space for more hints and tips in future.