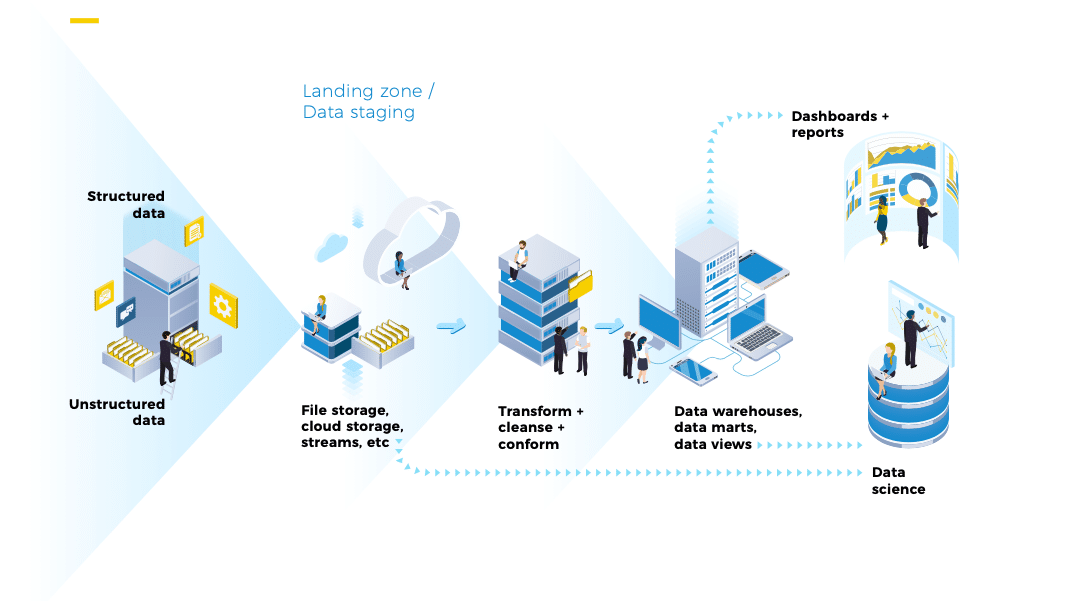
A Data Pipeline is created for data analytics purposes and has:
Data sources – these can be internal or external and may be structured (e.g. the result of a database call), semi-structured (e.g. a CSV file or a Google Sheet), or unstructured (e.g. text documents or images).
Ingestion process – the means by which data is moved from the source into the pipeline (e.g. API call, secure file transfer).
Transformations – in most cases data needs to be transformed from the input format of the raw data, to the one in which it is stored. There may be several transformations in a pipeline.
Data Quality/Cleansing – data is checked for quality at various points in the pipeline. Data quality will typically include at least validation of data types and format, as well as conforming against master data.
Enrichment – data items may be enriched by adding additional fields such as reference data.
Storage – data is stored at various points in the pipeline. Usually at least the landing zone and a structured store such as a data warehouse.
Functional requirements
Pipelines that are:
Easy to orchestrate
Support scheduling
Support backfilling
Support testing on all the steps
Easy to integrate with custom APIs as sources of data
Easy to integrate in a CI/CD environment
The code can be developed in multiple languages to fit each client skill set when python is not a first class citizen.
Our strategy
In some situations a tool like Matillion, Stitchdata or Fivetran can be the best approach, although it’s not the best choice for all of our client’s use cases. These ETL tools work well when using the existing pre-made connectors, although when the majority of the data integrations are custom connectors, it’s certainly not the best approach. Apart from the known cost, there is also an extra cost when using these kinds of tools – the effort to make the data pipelines working in a CI/CD environment. Also, at Equal Experts, we advocate we should test each step of the pipeline, and if possible, develop them using test driven development – and this is near impossible in these cases.
That being said, for the cases when an ETL tool won’t fit our needs, we identified the need of having a reference implementation that we can use for different clients. Since the skill set of each team is different, and sometimes Python is not an acquired skill, it was decided not to use the well known python tools that are used these days for data pipelines like Apache Airflow or Dagster.
So we designed a solution using Argo Workflows as the orchestrator. We wanted something which allowed us to define the data pipelines as DAGs like Airflow.
Argo Workflows is a container-native workflow engine for orchestrating parallel jobs on Kubernetes. Argo represents workflows as Dags (Directed Acyclic Graphs), and each step of the workflow is a container. Since data pipelines can be easily modeled as workflow it is a great tool to use. Also, we have freedom to choose which programming language to design the connectors or the transformations, the only requirement is that each step of the pipeline should be containerised.
For the data transformations, we found that dbt was our best choice. Dbt allows the transformations needed between the staging tables and the analytics tables. Dbt is SQL centric, so there isn’t a need to learn another language. Also, dbt has features that we wanted like testing and documentation generation and has native connections to Snowflake, BigQuery, Redshift and Postgres data warehouses.
With these two tools, that is how we ended up with a language agnostic data pipelines architecture that can be easily reused and adapted in multiple cases and for different clients.
Reference implementation
Because we value knowledge sharing, we have created a public reference implementation of this architecture in the github repo which shows a pipeline for a simple use case of ingesting UK COVID-19 data (https://api.coronavirus.data.gov.uk) as an example.
The goal of the project is to have a simple implementation that can be used as an accelerator to other teams. It can be easily adapted to make other data pipelines, to integrate in a CI/CD environment, or to extend the approach and make it work for different scenarios.
The sample project uses a local kubernetes cluster to deploy Argo and the containers which represent the data pipeline. Also a database where COVID-19 data is loaded and transformed and an instance of Metabase to show the data in a friendly dashboard.
We’re planning to add into the reference implementation infrastructure as code to deploy the project on AWS and GCP. Also, we might also work in aspects like facilitating the monitoring of the data pipelines when deployed in a cloud, or using Great Expectations.
Transparency is at the heart of our values
We value knowledge sharing and collaboration, so we hope that this article, along with the data pipelines playbook will help you to start creating data pipelines in whichever language you choose.
Contact us!
For more information on data pipelines in general, take a look at our Data Pipeline Playbook. And if you’d like us to share our experience of data pipelines with you, get in touch using the form below.
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.