At Equal Experts, we pride ourselves on helping our customers to create a culture of excellence. That culture is built upon organizational learning – how teams can continually improve themselves, and their ability to deliver business outcomes. And a big part of that is how a team learns from the successes and surprises of teams elsewhere in the organization.
Incident reviews (also known as post-mortems) contribute to organizational learning by building understanding of the multiple human and technical factors that contributed to an incident. Incidents are messy, painful, and expensive, and an incident review is an opportunity to learn from experience. The idea is to explore the operational surprises, sources of data, improvised actions, requests for help, and service behaviors that contributed to an incident. Those insights can then be turned into improvement actions, and shared with other teams.
This is in contrast to the traditional root cause analysis (RCA) method, which we don’t recommend. There’s plenty of academic research and industry experience on why RCA doesn’t work. And that chimes with our customers’ experiences – it’s never as simple as one person made a mistake or one deployment was faulty (see ‘Why stopping deployments doesn’t stop incidents‘ by my colleague Caitlin Smith.)
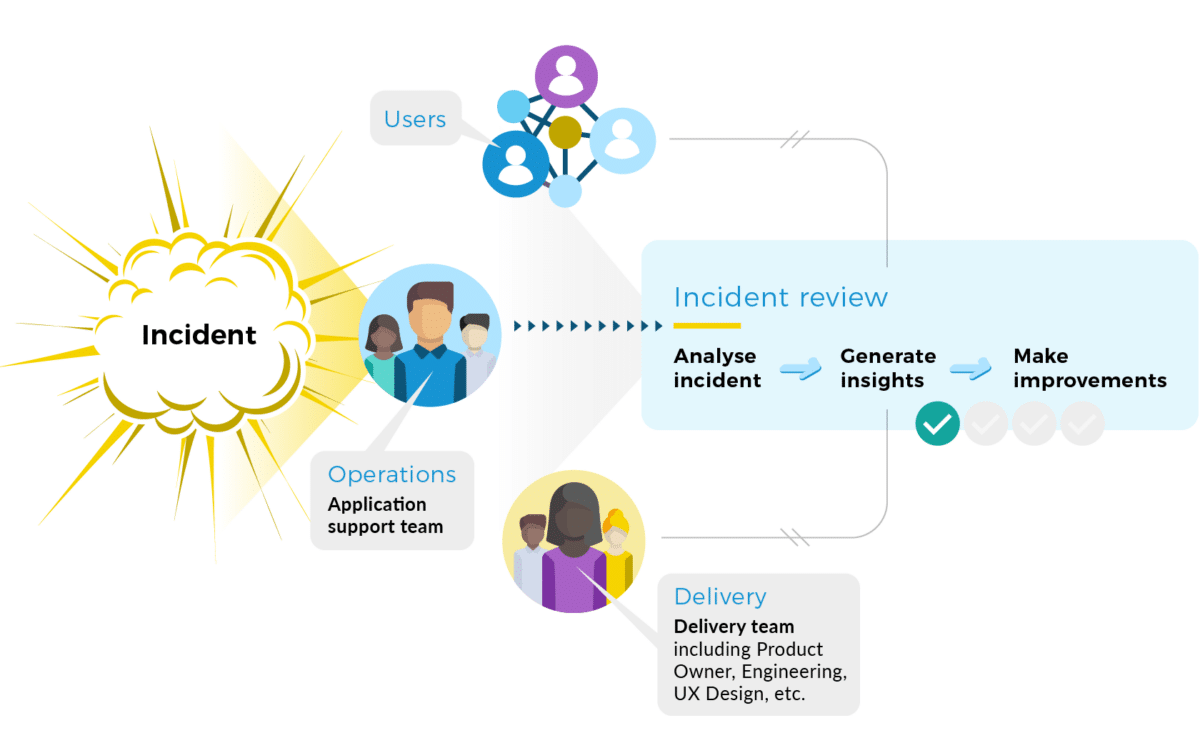
There’s a lot involved in setting up an incident review process that’s capable of generating actionable insights across the teams in your whole organization. It starts with ensuring the right people participate in the review, whether it’s for a Chaos Day or a live incident. Our recommended roles for an incident review would be:
A facilitator
The delivery team
The operations team
Some users (or user proxies, such as Product Managers)
Let’s look at some ways we’ve seen incident reviews not work very well, followed by our recommendation in a bit more detail.
Don’t exclude the delivery team
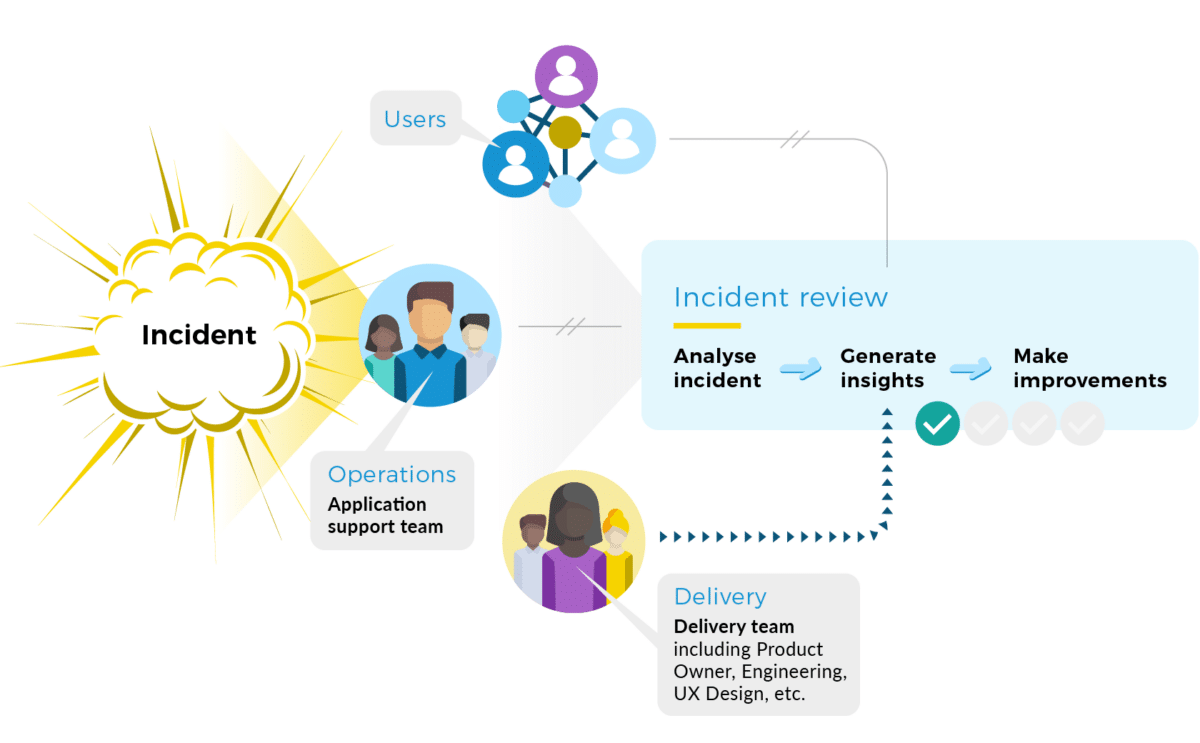
This applies to one or more delivery teams building services, and a central operations team who run those services. By operations team, I mean analysts and responders who operate live services. In this scenario, an incident review is conducted solely by the operations team, e.g. after a live website outage.
Incident reviews that don’t include the product manager or engineers can’t generate any product or engineering insights. Organizational learning is severely limited, because the operations team can’t access delivery team knowledge about why the service was designed and developed in a certain way. It’s possible delivery teams won’t even know that an incident review has taken place.
At a financial services company, the operations team conducted an incident review into a service outage caused by a faulty deployment. They weren’t aware an in-memory cache within the service was misconfigured, as it had no logging and was known only to the developers. The operations team wrote up their report as a wiki page in their own Confluence space, which meant delivery teams lacked the necessary permissions to read the incident report.
Don’t exclude the operations team
This scenario also applies to one or more delivery teams and a central operations team running all those services. An incident review is conducted solely by a delivery team, perhaps after their service is unavailable in a test environment.
Incident reviews that don’t include operators can’t produce any operational insights. A delivery team can’t obtain any operations team knowledge about how their service is actually operated in a live environment. The operations team might see the same issue in production later on, and not know the delivery team has fixed it in an upcoming release.
At a telecommunications company, a delivery team ran an incident review after their authentication platform became unavailable in a test environment, and other delivery teams were blocked from testing. They weren’t aware the operations team had a monitoring dashboard in production that could be applied back into test environments. The delivery team wrote up their report as a Google document and shared it with the operations team, who hadn’t known there was an issue at all.
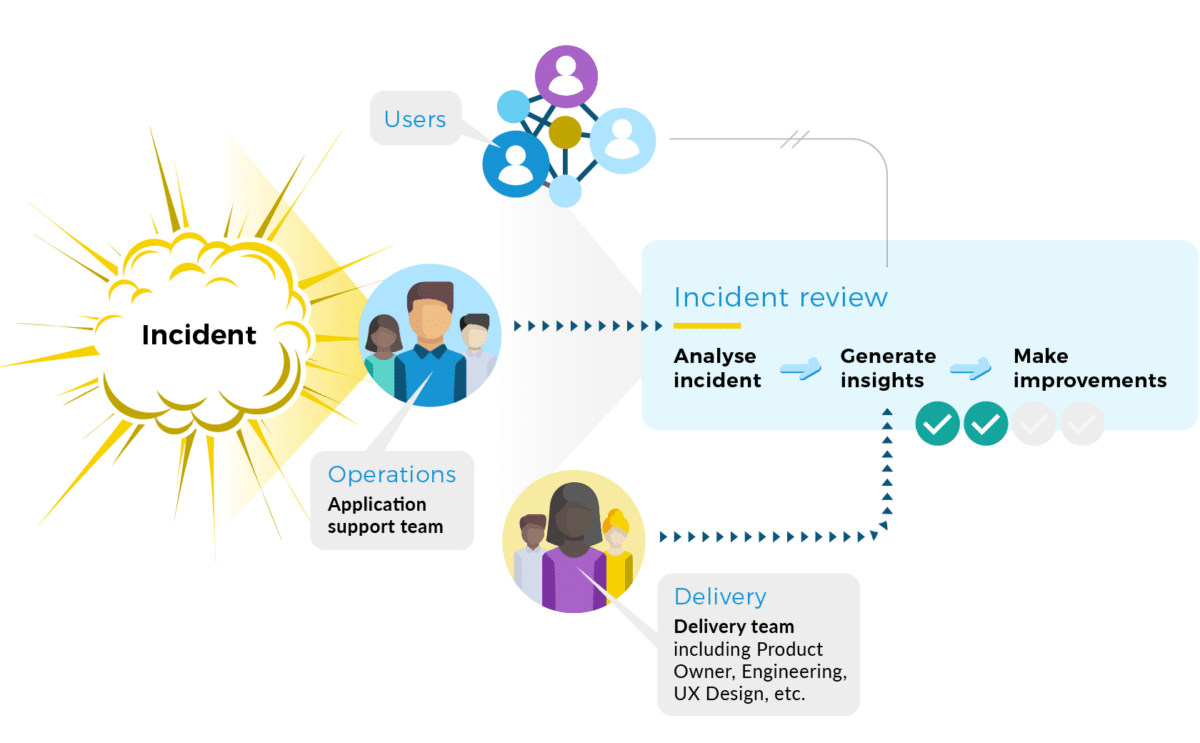
Don’t exclude users
This scenario is relevant to delivery teams with one central operations team. By users, I mean either upstream consumers for an API service, or end-users of an app or web interface. If users are external to the organization, then a user-proxy, such as the relevant domain’s Product Manager should be involved instead. An incident review is run by members of a delivery team and the operations team.
Incident reviews that don’t include users can’t result in any usage insights. A delivery team and an operations team, or an empowered product team, can’t understand in isolation how users actually experience an incident. Vital data on user experience during service degradation is unavailable, and any negative impact upon reputation is missed entirely.
This scenario can also happen with empowered product teams who’ve adopted the You Build It You Run It operating model. An incident review that’s solely run by the product team without upstream teams or end-users will result in similarly limited insights.
At a healthcare company, a product team doing You Build It You Run It saw an increase in live traffic errors. They diagnosed a performance problem due to a missing database index, and watched their circuit breaker start to handle errors. They updated their infrastructure code, and rolled out a fix to all environments within minutes. But when the incident review didn’t include any users, attendees didn’t know how the circuit breaker had impacted users. They weren’t sure if users had experienced a partial or total loss of service. They’d missed an opportunity to share with their organization how graceful degradation impacted users, and if it was worth other teams investing in a similar architecture.
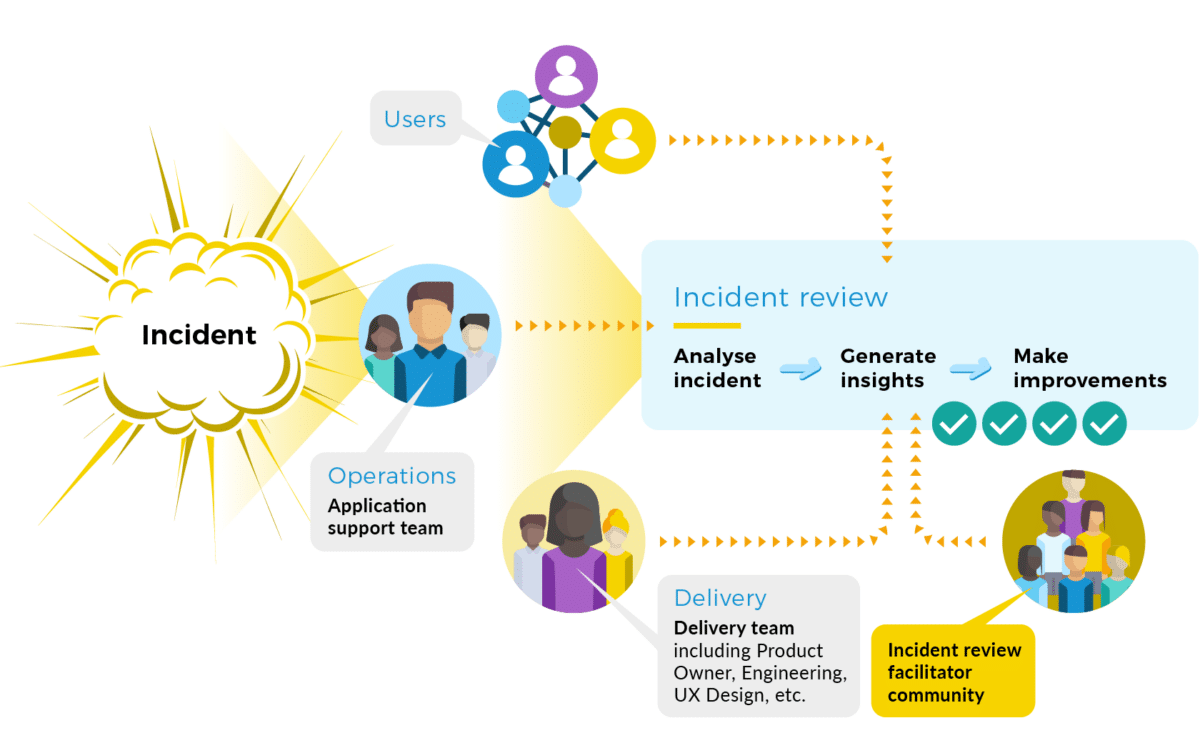
Have a facilitator bring people together
An effective incident review has representatives from the engineers, operators, and users associated with the service(s) that triggered or were associated with the incident. If you have delivery teams with an operations team, it looks like this.
It’s crucial that an external facilitator is present, to ensure adequate representation, minimize bias where possible, and encourage different perspectives. Incident review facilitation is a skill, and we suggest to our customers that they gradually build up a community of like-minded practitioners to act as facilitators.
Weaving together usage, engineering, and operational knowledge makes it easier to identify discrepancies in each person’s mental model of the incident, and uncover the surprises that made it harder (or easier!) to resolve the incident. Sharing the human and technical factors that contributed to events across the organization offers a rich source of learning, and guards against multiple teams enduring similar incidents.
Conclusion
A culture of excellence is built upon organizational learning, and it’s important that teams can learn from the successes and surprises of other teams, as well as their own. Part of that is an effective incident review process, and it’s not enough for any one team to run an incident review, because an incident affects more than one team. We recommend to our customers that an incident review include:
A facilitator
The delivery team
The operations team
Some users
You may also like
Blog
Migration and modernisation options for your heritage services – Rethinking the AWS 6Rs
Blog
Engineering Data Platforms for next-generation innovation in superannuation
Blog
Optimising cloud for superannuation funds: Driving greater business value
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.