It’s understandable when people say after an outage ‘let’s stop deployments, so we can stop incidents’. But it doesn’t work out that way. Most incidents are triggered by surprise events, not planned changes, and my colleague Steve Smith and I have historical data from 3 large organisations to demonstrate this.
The wrong solution for a real problem
I’ve worked in cross-team delivery roles at government agencies, media companies, and broadcasters, and I often see the same thing happen after outages. It’s suggested that we restrict deployments to prevent any more incidents.
When I worked at a broadcaster, there was a serious performance issue caused by a planned Postgres upgrade. It hadn’t happened in test upgrades, and a worried operations manager said afterwards ‘all future deployments are now at risk’. However, I pointed out it hadn’t happened before because our test data was so limited, so we couldn’t have known in advance. We focussed instead on implementing the DORA metrics to rebuild confidence.
Stopping deployments is the wrong solution for a real problem, because most incidents aren’t triggered by deployments. There’s no such thing as a root cause, it’s always multiple faults that cause an incident, but there’s usually a trigger that forces the faults together. I’ll bet most of your incidents are triggered by surprises, not deployments.
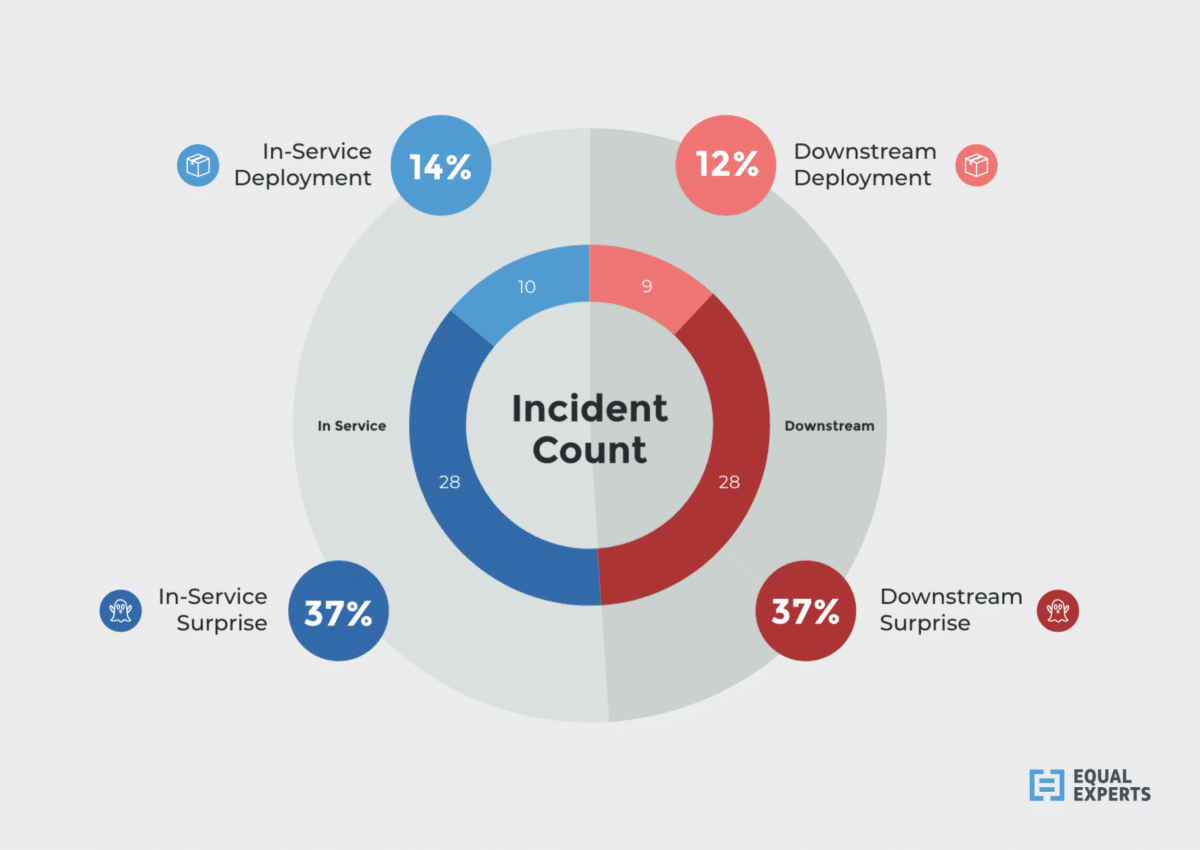
My colleague Steve Smith and I have looked at the data from three large organisations, with 10-30 teams and 15-40 digital services. Combining 71 P1 and P2 incidents from 1 year into a composite organisation gives these results.
74% of incidents at this composite organisation were caused by surprise events, in-service and downstream. Examples included database performance issues, firewall problems, out of memory errors, and downstream service bus errors. So, why is this a problem?
Services aren’t built to handle surprises
I’ve seen many different kinds of surprise events. The one thing they have in common is when they go wrong, they really go wrong!
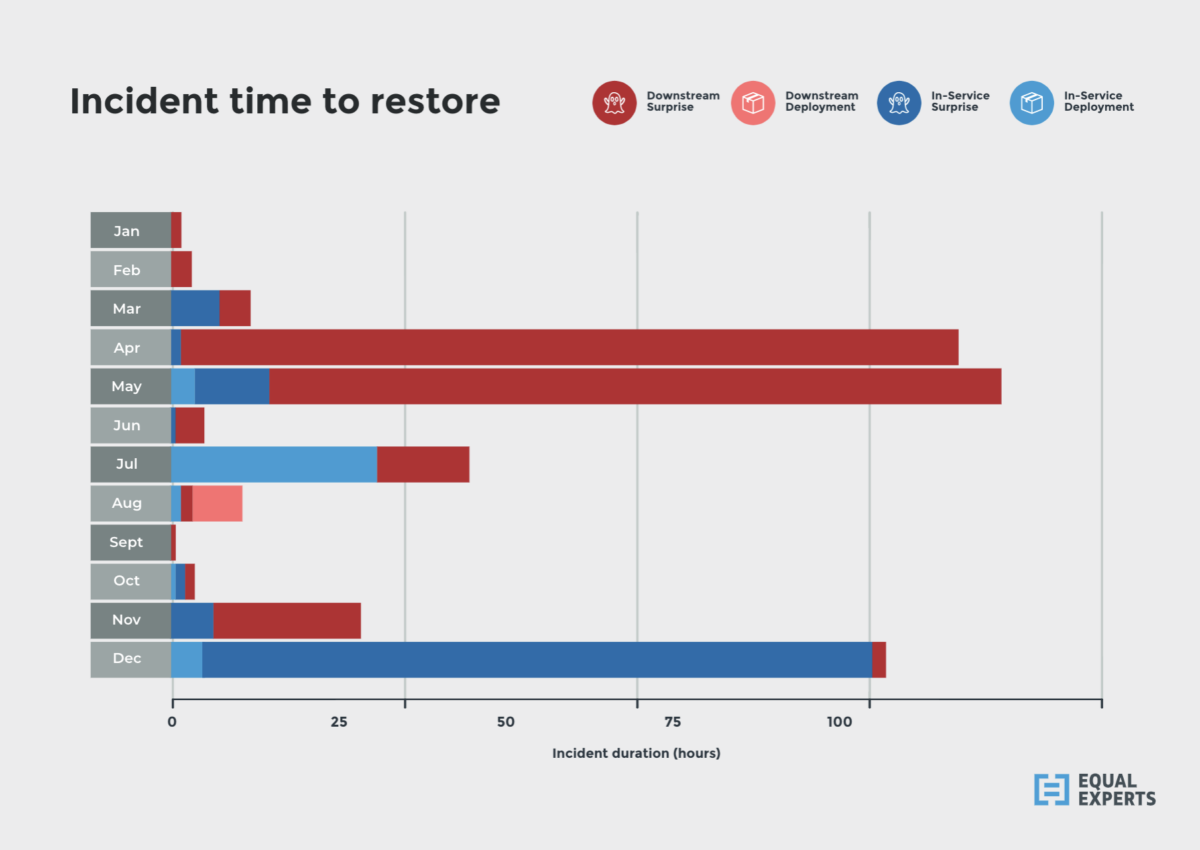
Time to restore is one of the DORA metrics we always recommend for delivery assurance. At our composite organisation, the data has already shown most incidents are triggered by surprises. It also shows those incidents have a much longer time to restore, up to 20x worse.
It takes longer to detect, diagnose, and resolve a loss of service availability when it isn’t preceded by a planned deployment. There’s no sense of heightened awareness, no obvious time period to investigate, and no option of a rollback. Services are extremely vulnerable to operational surprises, because they aren’t built to handle them.
Optimise for time to restore, not incident count
In my experience, developers aren’t able to build services that can adapt to surprises. They’re tasked to complete new features as soon as possible, and they lack access to learn from live traffic trends or observability data.
You can change that culture by optimising for a faster time to restore, not fewer incidents. It’s the minutes of lost availability that cause financial losses and reputational damage, not the number of incidents. Our recommendations here include:
Switch to on-call product teams. Adopting the You Build It You Run It operating model incentivises product managers to prioritise reliability alongside functionality, encourages developers to add adaptive capacity, and accelerates time to restore
Add some chaos. Running Chaos Days and injecting faults into services allows teams to identify vulnerabilities before any incidents happen
More deployments. Increasing deployments means smaller change sets to test, smaller time windows to observe, and a smaller probability of introducing faults
Stopping deployments doesn’t stop incidents, because most of your incidents are triggered by operational surprises, not planned changes. Unexpected, unplanned events can happen at any time, so it’s important to build services that can adapt to surprises. And optimising for a faster time to restore, not fewer incidents, is the starting point on that journey.
You may also like
Blog
Migration and modernisation options for your heritage services – Rethinking the AWS 6Rs
Blog
Engineering Data Platforms for next-generation innovation in superannuation
Blog
Optimising cloud for superannuation funds: Driving greater business value
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.