


Want to know more?
Are you interested in this project? Or do you have one just like it? Get in touch. We’d love to tell you more about it.
In early 2018, retailer John Lewis & Partners needed to accelerate its time to market, improve website reliability, and create a learning culture at scale. It was the start of a journey with Equal Experts to adopt the You Build It, You Run It operating model, where product teams build and run their own digital services. John Lewis & Partners has now successfully scaled up You Build It You Run It to 40 product teams and 75 digital services, while the operations team focussed on critical backend COTS applications. This resulted in higher deployment throughput, greater service reliability, and continuous learning, which enabled product teams to keep up with a fast-paced business landscape.

concurrent digital teams
deployments a year
in-incident revenue protection effectiveness
John Lewis & Partners is one of the UK’s oldest, largest and most popular retailers. They operate 34 stores across the UK, as well as johnlewis.com. It has total trading sales of £4.93 billion, a workforce of 38,000 Partners (employees), and is part of the John Lewis Partnership – the largest employee-owned business in the UK.



In early 2018, John Lewis & Partners committed to reducing its annual multi-million pound opportunity costs, by replacing the monolithic COTS ecommerce platform behind johnlewis.com with tens of teams building user-centric digital services. The goal was to:
As part of this work, Equal Experts was asked to help create a step change in technology operations. At the time, John Lewis & Partners had separate Delivery and Operations functions, with the application support team provided as a third-party managed service. Deployments could not be accelerated, johnlewis.com reliability could not be improved any further, and the vendor feared being overwhelmed by the number of planned digital services. In addition, there was a support backlog with hundreds of tasks, with an estimated revenue impact in the tens of millions. The challenge set by John Lewis & Partners was how to re-design technology operations, and embed operability into teams at scale.
Equal Experts recommended moving to a You Build It You Run It operating model, in which autonomous product teams would run their own digital services and focus on business outcomes. The plan was to maximise incentives for engineers to build operability into digital services, and free up the application support team to concentrate on critical COTS applications.
At the time, John Lewis & Partners and Equal Experts were building the John Lewis & Partners Digital Platform (JLDP), to handle the ever-growing number of product teams and digital services. A digital platform is a collection of paved roads, providing fault-free and frictionless user journeys for product teams.
It was important to add an incident response paved road to JLDP. To be comfortable with the You Build It You Run It principle of on-call product teams, engineers needed incident response to be streamlined. The existing workflow involved multiple handoffs:
A fully automated workflow was implemented for digital services in JLDP, which used the PagerDuty incident response platform to connect microservices with Slack and ServiceNow. JLDP automatically provisions a new digital service as an on-call policy and team rota in PagerDuty. When an alert is fired:
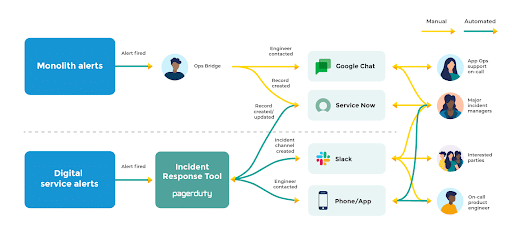
Incorporating as-is incident management was vital. John Lewis & Partners had incident managers who were skilled facilitators and communicators, and they lightened cognitive load for on-call engineers during incident response. Incident managers were modelled as a PagerDuty on-call team rota, and could be phoned during an incident with a single button click in PagerDuty.
The incident response paved road was a key step in the operability journey for John Lewis & Partners. Replacing spreadsheets and phone calls with PagerDuty alerts reduced Time To Acknowledge (TTA) from 5-20 minutes to a consistent 60 seconds. Switching from private to public chat rooms allowed anyone to learn from response efforts, during and after incidents. Implementing bi-directional sync between PagerDuty and ServiceNow improved data capture quality in incident tickets, and allowed customer service teams to contact product teams by simply raising a ServiceNow ticket.
The run cost of You Build It You Run It at scale was a concern at the outset for John Lewis & Partners. It was assumed 20, 30, or 40 product teams would require 20, 30, or 40 on-call engineers, and incur a linear run cost.
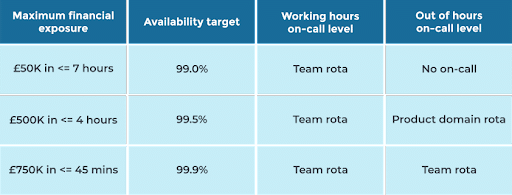
Early conversations focused on You Build It You Run It as an insurance policy for business outcomes, and the need to optimise run costs without weakening operability incentives for engineers. The answer was to link availability level and on-call level to a financial exposure band – the expected revenue loss and operational costs in an incident. Financial exposure bands and availability levels were sourced from a pre-existing John Lewis & Partners policy.
Product managers were asked to estimate the maximum financial exposure for each digital service. A service availability calculator was then used to assign an availability target and on-call level. This process incentivised product managers to prioritise operational features alongside product features, and brought opportunity costs into the same conversations as run costs. An example calculator is shown below, with some artificial financial exposure bands.
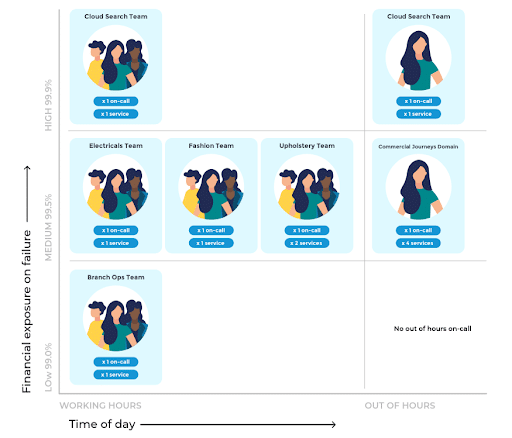
All product teams are on-call during working hours for their own digital services. This incentivises engineers to minimise BAU maintenance work, and implement operational features such as monitoring dashboards, message queues, and circuit breakers. Out of hours, teams have the following guidelines:
The below example shows some digital services at John Lewis & Partners. The basket, electricals, fashion, and upholstery services are part of the same Commercial Journeys product domain, so each night one person is on-call from the three teams for the four services.
Initially, You Build It You Run It caused some concerns from product team engineers, who had not been on-call before. Understanding and overcoming their fears, by openly discussing and addressing them, was just as important as changes to processes and tools. The operating model now receives very positive feedback from product teams, who are constantly learning by building and running their own digital services at scale.
The rate of deployments has dramatically increased, and in-incident financial losses have fallen. A good example of this was Black Friday 2020, which saw record user traffic due to the COVID-19 pandemic. The johnlewis.com website performed well, and online sales were 50% higher than 2019.
In 2021, John Lewis & Partners and Equal Experts ran a cost/benefit analysis on two years of data, which validated the value proposition of You Build It You Run It. In deployment throughput, product teams averaged one deploy every 3 days, whereas the application support team averaged weekly deployments with high variability.
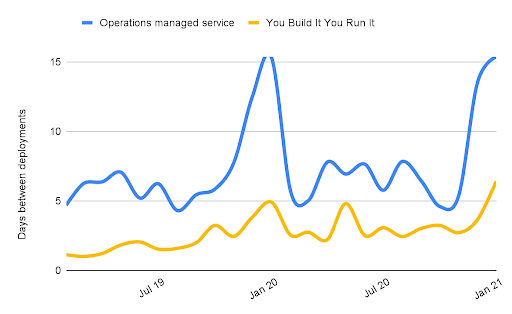
In service reliability, on-call product teams had fewer incidents with a financial loss than the third party managed service, and their time to restore was much faster. 44 digital services had a Mean Time To Recovery (MTTR) of 27 mins with low variability. The application support team had an MTTR of 1 hour with high variability.
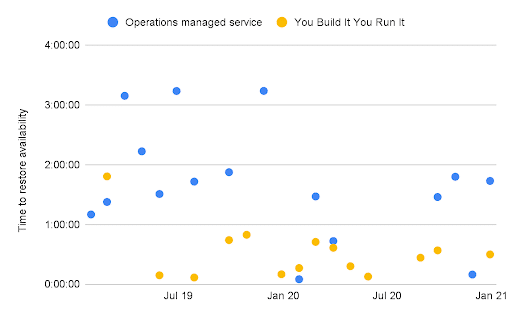
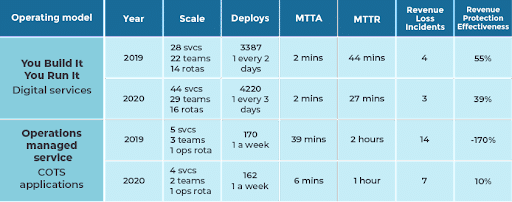
The table below shows that You Build It You Run It was superior in terms of scale, throughput, and reliability. It includes a revenue protection effectiveness measure, which was devised for a fair comparison between the two operating models despite their differing teams, services, and ranges of financial exposure. Revenue protection effectiveness was defined as the % of expected revenue loss per incident that was realised, based on the time to restore. You Build It You Run it was more effective, year on year.
With over 30 years in IT, and 10 years leading Operations teams, it’s been hard for me to let go of having direct control of a single Ops team. However, I’ve been amazed that You Build It You Run It has provided a step change compared to traditional ITIL best practice, and the outcomes we’ve demonstrated speak for themselves.
Are you interested in this project? Or do you have one just like it? Get in touch. We’d love to tell you more about it.