
What’s the difference between a Data Scientist and a Data Engineer?
In the mid 2010’s there was a step change in the rate at which businesses started to focus on gaining valuable insights from data.
As the years have passed, the importance of data management has started to sink in throughout the industry. Organisations have realised that you can build the best models, but if your data isn’t qualitative, your results will be wrong.
There are many, varied job roles within the data space. And I always thought the distinction of the roles were pretty obvious. However, recently a lot has been written about the difference between the different data roles, and more specifically the difference between Data Scientists and Data Engineers.
I think it’s important to understand that not knowing these differences can be instrumental in teams failing or underperforming with data. Which is why I am writing this article. To attempt to clarify the roles, what they mean, and how they fit together. I hope that this will help you to understand the differences between a Data Scientist and a Data Engineer within your organisation.
What do the Data Engineer and Data Scientist roles involve?
So let’s start with the basics. Data Engineers make data available to the business, and Data Scientists enable decisions to be made with the data.
Data Engineers, at a senior level, design and implement services that enable the business to gain access to its data. They do this by building systems that automagically ingest, transform and publish data, whilst gathering relevant metadata (lineage, quality, category, etc.), enabling the right data to be utilised.
Data Scientists not only utilise the data made available, but also uncover additional data that can be combined and processed to solve business problems.
Both Data Scientists and Data Engineers apply similar approaches to their work. They identify a problem, they look for the best solution, then they implement the solution. The key difference is the problems they look at and, depending on their experience, the approach taken to solving it.
Data Engineers like Software Engineers, or even more generally engineers, tend to use a process of initial development, refinement and automation.
Initial development, refinement and automation explained, with cars.
In 1908 Henry Ford released the Model T Ford. As you can see, it has many of the same features as a modern car – wheels on each corner, a bonnet, a roof, seats, a steering wheel, brakes, gears.

In 1959 the first Mini was released. It had all the same features as the Model T Ford. However, it was more comfortable, cheaper, easier to drive, easier to maintain, and more powerful. It also incorporated new features like windscreen wipers, a radio, indicators, rear view mirrors. Basically, the car had, over 50 years, been incrementally improved.

Step forward in time to 2010, and Tesla released the Models S and X. These too have many features we can see in the Model T Ford and the Mini. But now they also contain some monumental changes.

The internal combustion engine is replaced with electric drive. It has sat-nav, autopilot, and even infotainment. All of which combine to make the car much easier and more pleasurable to drive.
What we are seeing is the evolution of the car from the initial production line – basic but functional – through multiple improvements in technology, safety, economy, driver and passenger comforts. All of which improve the driving experience.
In other words we are seeing initial development, refinement and automation. A process that Data Engineers and Data Scientists know only too well.
For Data Engineers the focus is on data, getting it from source systems to targets, ensuring the data quality is qualified, the lineage captured, the attributes tagged, and the access controlled.
What about Data Scientists? They absolutely follow the same pattern, but they additionally look to develop analytics along the Descriptive, Diagnostic, Predictive, Prescriptive scale.
So why is there confusion between the Data Scientist and Data Engineer roles?
There is of course not a single answer but some of the common reasons include:
- At the start, both Data Scientist and Data Engineers spend a lot of time Data Wrangling. This means trying to get the data into a shape where it can be used to deliver business benefits.
- At first, the teams are often small and they always work very closely together, in fact, in very small organisations they may be the same person – so it’s easy to see where the confusion might come from.
- It’s often given to Data Engineers to “productionise” analytics model created by Data Scientists.
- Many Data Engineers and Data Scientists dabble in each other’s areas, as there are many skills both roles need to employ. These can include data wrangling, automation and algorithms..
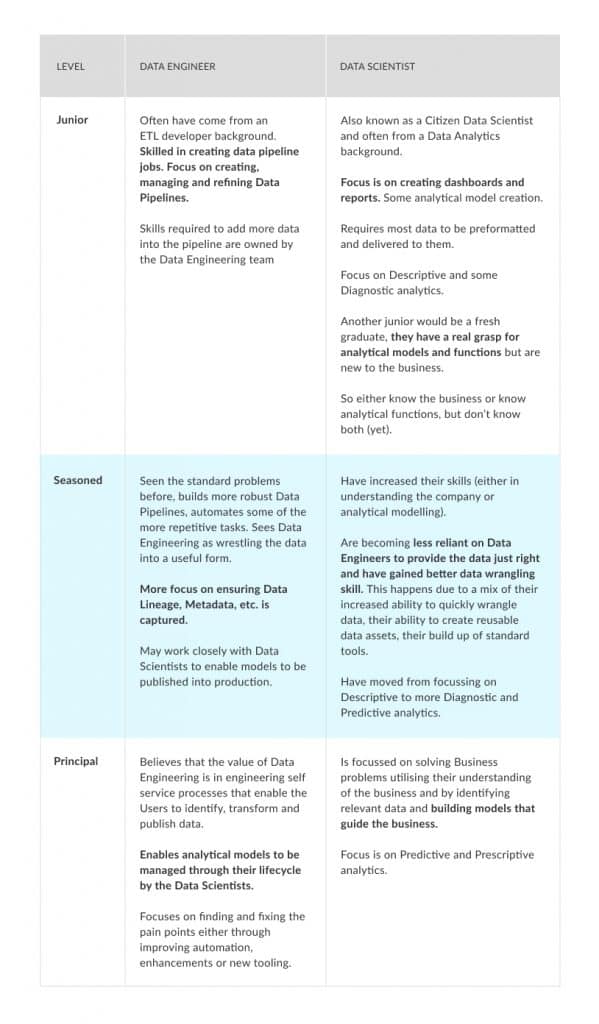
As the seniority of data roles develop, so do the differences.
When I talk to and work with Data Engineers and Data Scientists, I can often categorise them into one of three categories – Junior, Seasoned, Principal – and when I work with Principals, in either space, you can tell they are a world apart in their respective fields.
So what differentiates the different levels and roles?
That’s it. I hope this article helps you to more easily understand the differences between a Data Scientist and a Data Engineer. I also hope this helps you to more easily identify both within your organisation. If you’d like to learn more about our Data Practice at Equal Experts, please get in touch using the form below.