
Crafting quality in data pipelines
In today’s world, data is an important catalyst for innovation, significantly amplifying the potential of businesses. Given the ever-increasing volume of data being generated and the complexity of building models for effective decision making, it’s imperative to ensure the availability of high quality data.
What is data quality?
Data quality measures how well data meets the needs and requirements of its intended purpose. High data quality is free from errors, inconsistencies and inaccuracies, and can be relied upon for analysis, decision making and other purposes.
In contrast, low quality data can lead to costly errors and poor decision making, and impacts the effectiveness of data-driven processes.
How to ensure data quality
Ensuring high quality data requires a blend of process and technology. Some important areas to focus on are:
- Define standards: it’s important to define quality criteria and standards to follow.
- Quality assessment: assess criteria and standards regularly using data profiling and quality assessment tools.
- Quality metrics: set data quality metrics based on criteria such as accuracy, completeness, consistency, timeliness and uniqueness.
- Quality tools: identify and set up continuous data quality monitoring tools.
- Data profiling: analyse data to know its characteristics, structure and patterns.
- Validation and cleansing: enable quality checks on data to ensure validation and criteria happen in line with criteria
- Data quality feedback loop: Use a regular quality feedback loop based on data quality reports, observations, audit findings and anomalies.
- Quality culture: Build and cultivate a quality culture in your organisation. Data quality is everyone’s responsibility, not just an IT issue.
Example Data Pipeline:
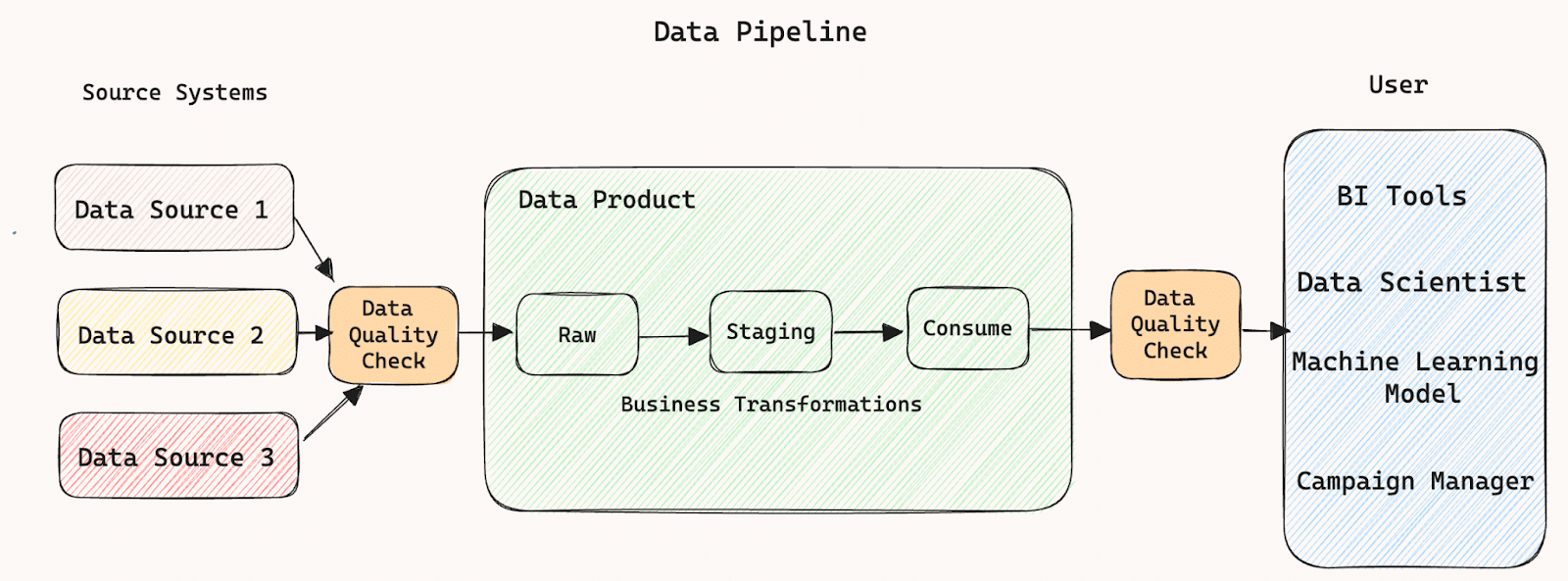
This diagram shows a basic data pipeline. It takes data from multiple source systems, putting data into various stages eg. RAW, STAGING and CONSUME. It then applies transformations and makes data available for consumers. To ensure the accuracy, completeness, reliability of the data:
- There is a data quality check in between the source systems and data product, which ensures that quality data is being consumed, and
- There is a data quality check in between the data product and consumers, which ensures that quality data is being delivered.
Data quality checks can include the following:
- Uniqueness and deduplication checks: Identify and remove duplicate records. Each record is unique and contributes distinct information.
- Validity checks: Validate values for domains, ranges, or allowable values
- Data security: Ensure that sensitive data is properly encrypted and protected.
- Completeness checks: Make sure all required data fields are present for each record.
- Accuracy checks: Ensures the correctness and precision of the data. Rectify errors and inconsistencies in the data.
- Consistency checks: Validate the data formats, units, and naming conventions of the dataset.
Tools/Framework to ensure data quality
There are multiple tools and frameworks available to enable Data Quality and Governance, including:
- Alteryx/Trifacta (alteryx.com) : A one stop solution for enabling data quality and governance for data platforms. The advanced capabilities enable best practices in data engineering.
- Informatica Data Quality (informatica.com): Offers a comprehensive data quality suite that includes data profiling, cleansing, parsing, standardisation, and monitoring capabilities. Widely used in enterprise settings.
- Talend Data Quality (talend.com): Talend’s data quality tools provide data profiling, cleansing, and enrichment features to ensure data accuracy and consistency.
- DataRobot (datarobot.com): Offers data preparation and validation features, as well as data monitoring and collaboration tools to help maintain data quality throughout the machine learning lifecycle. Primarily Datarobot is an automated machine learning platform.
- Collibra (collibra.com): Collibra is an enterprise data governance platform that provides data quality management features, including data profiling, data lineage, and data cataloging.
- Great Expectations (greatexpectations.io): An open-source framework designed for data validation and testing. It’s highly flexible and can be integrated into various data pipelines and workflows. Allows you to define, document, and validate data quality expectations.
- Dbt (getdbt.com): Provides a built-in testing framework that allows you to write and execute tests for your data models to ensure data quality.
Data quality in action
We have recently been working with a major retail group to implement data quality checks and safety nets in the data pipelines. The customer has multiple data pipelines within the customer team, and each data product runs separately, consuming and generating different Snowflake data tables.
The EE team could have configured and enabled data quality checks for each data product, but this would have made configuration code redundant and difficult to maintain. We needed something common that would be available for the data product in the customer foundation space.
We considered several tools and frameworks but selected Great Expectations to enable DQ checks for several reasons:
- Open source and free
- Support for different databases based on requirement
- Community support on Slack
- Easy configuration and support for custom rules
- Support for quality checks, Slack integration, data docs etc
We helped the retailer to create a data quality framework using docker image, which can be deployed in the GCR container registry and made available across multiple groups.
All the project specific configuration, such as Expectation Suite and Checkpoint file are kept in the data product’s GCS Buckets. This means the team can configure required checks based on the project requirement. Details about GCP Bucket are shared in the DQ image. The DQ image is capable of accessing the project specific configuration from Bucket and executing the Great Expectation suite on Snowflake tables in one place.
Flow Diagram:
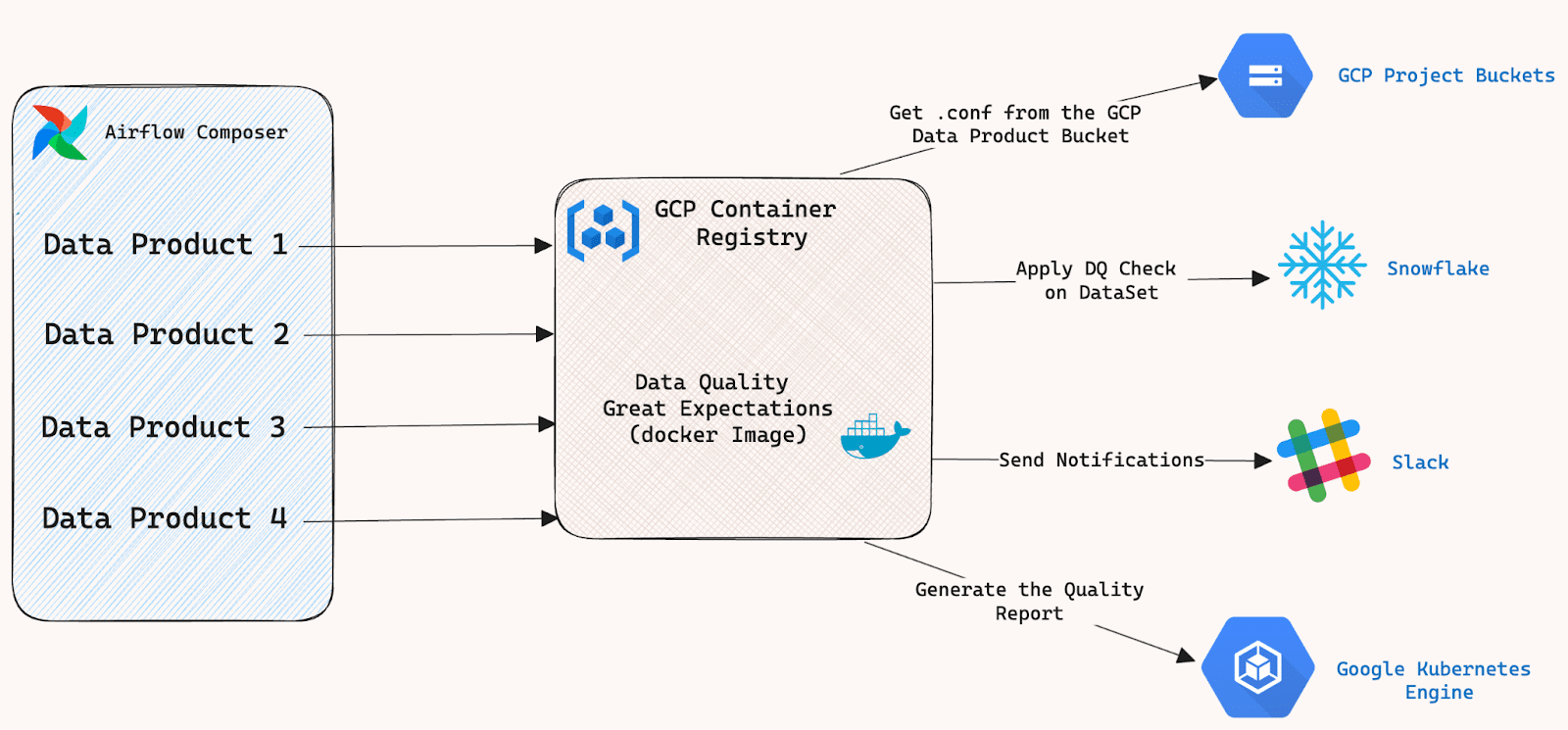
The DQ framework can:
- Access the configuration files from the data product’s GCP Buckets
- Connect to Snowflake Instance
- Execute Great Expectation suites
- Send the Slack notification
- Generate the quality report using Data Docs (In progress)
Quality assurance is a continuously evolving process and requires constant monitoring and audit. By doing this, we not only safeguard the credibility of the data but also empower our customer with the insights needed to thrive in a data-centric world.
A lot of people worry about data governance. It’s a common topic that we hear from many of our customers across all sectors, and independent research backs this up. In fact, in a recent analysis we made from thousands of industry requests, data governance was the main concern for many data leaders.
We hear concerns from people in senior management about how to operate effective data governance, and as a company focused on agile delivery we also hear from “people on the ground” who worry about finding the right balance between governance and delivery.
Where does this worry come from? What can we do to help people operate data governance effectively? In this blog I’ll share some of my experiences and learning about the “secret sauce” of good governance, and describe some concrete steps you can take to help.
Here’s what it boils down to
- Governance is essentially about people not documents.
- People are anxious.
- Don’t be afraid.
- Talk to each other.
- Help each other.
What does governance mean to you?
When I say “governance” what does this make you think? How does it make you feel? If you’re able, take a moment to reflect on this now and observe your gut reactions.
When we pose this question to agile delivery teams, answers typically tend to group around two areas:
- “Governance gets in the way of delivery”. Sometimes people describe governance as being like Darth Vader or the bouncers at a nightclub!
- “Governance is a box-ticking exercise”. Agile delivery teams often mention frustration at a seemingly endless number of documents that need to be filled in.
We’re not saying that we agree with these sentiments; we’re just reporting what others have told us about how they feel.
In order to help agile delivery teams interact more effectively with governance, we work with them to help them understand the nature of good governance as we see it.
So – what is the essence of governance?
In our work with agile delivery teams, we try to help them understand the following key points about governance from our experience:
- Governance is not essentially about documents.
- Governance is essentially about people.
- Governance is about people who are worried about how to do things safely.
- Governance is about people making decisions under uncertainty and ambiguity.
- People are anxious.
- Relationships are hard.
Your organisation will have people who are legally accountable for the safe handling of data under their care. It’s not easy being accountable for data – just ask any Chief Data Officer, or Chief Information Security Officer, or your Audit & Risk Committee! Given the complexity of the data and the many interacting forms of legislation, it is not always clear what is the “right thing to do”. The accountable people are rightly worried that data could be mismanaged or lost, or that a mistake could be made that would impact the whole business.
Governance is (or should be) the means by which people get together to agree on a way of handling this risk, uncertainty and ambiguity. When it’s not clear what to do, governance provides a means of establishing a consensus among people about the best course of action to ensure that data is being safely managed and controlled.
So – how can we use this understanding to work better together towards governance that provides both safe management of data and effective delivery? Is there a “secret sauce” of governance?
“Secret sauce” for effective data governance
Governance is a way of reaching a consensus among people who make decisions about operating safely in the presence of complexity, uncertainty and ambiguity. In our experience of working with both governance bodies and agile delivery teams, we have found some key things that have helped everyone work effectively together.
- Empathise. Don’t say “I empathise”: empathise!
As an agile delivery team, remember that the people in charge of data governance have a difficult job too. They are asked to make tricky decisions, and it’s often not clear what the right approach is, particularly when you’re dealing with complex, sensitive data at scale.
The people in charge of governance are just trying to do the right thing for the whole organisation, balancing the needs of delivery with many different forms of interacting legislation and policy. Being empathetic of their situation goes a long way – just as it does when they are empathetic about your needs too. Remember that being empathetic is an activity not a statement; it’s an active way of relating together, and it takes purposeful effort.
- Whose problem is it? Make it our problem together.
We have heard that some delivery teams view governance as “somebody else’s problem”. This is neither true nor useful. If you do not consider the needs of governance throughout your work, you risk failing at the final hurdle when your project cannot go live because it is not handling data safely. This benefits no-one.
It is key to find the right people to work together with on your project’s governance. If you can’t find them, keep looking – don’t give up! Build the relationship with those people so you understand their key worries about your project, and work together to resolve them. Doing this early means everyone is much happier later, and results in faster delivery.
- Documents are worries. Therapy works.
One of our key theses is that governance is essentially about people rather than documents – so why do all these documents exist? What are they, really?
In our view, governance documents are best thought of as “embodied worries”. Each document that you’re asked to fill in contains sections that individually reflect particular worries that accountable people have about handling data safely. For example, think of how many times you’ve filled in a section on GDPR. These are legitimate worries.
Work directly with your governance people to understand those worries in detail. Talk with them, discuss their concerns (as embodied in the documents) and work with them to understand how to resolve them. I think of this as a kind of “talking therapy” – often it’s only when you discuss a problem that you can (together) understand what lies behind the worry. Then you can start to address it by demonstrating how you’re taking steps that you (together) agree can help.
- Co-create. Prisoners / protestors / passengers / participants.
By working together with governance folks, you create something that means something for both of you. This is a form of the collaboration and co-creation that is so effective elsewhere in agile delivery. Your governance stakeholders are users too.
The “Four P” model (prisoners / protestors / passengers / participants) often used in professional training can be useful here. We ask agile delivery teams to reflect about how they feel when they’re working on governance. Sometimes people will identify with the “prisoner” – feeling trapped and wanting to escape. Sometimes people are “protestors” who disagree and argue that it won’t work, or “passengers” who sit back and hope others take the lead. Our goal is always to be “participants” – people who get involved, take shared responsibility, and help each other to reach the goal.
- Advice and guidance – not “sign this off!”
Imagine how you’d feel if you were asked to sign a contract without knowing exactly what you’re signing! In the same way, asking someone in a governance role to just sign something off is simply wrong.
We often hear that governance folks ask teams to “engage early” – essentially this means “don’t back me into a corner”. Nobody likes being backed into a corner. When we’ve got a difficult thing to do, we need a chance to think and evolve our narrative around it – how to fit it into the wider context, and how to present it to those who also need to be involved.
Asking governance folks for advice and guidance during your co-creation is an excellent way of understanding each other and building your trust together. They often have perspectives on the data and the legislation that are invaluable in helping to understand the wider landscape, and this helps to build better products.
- Escalate carefully. Escalate together.
There will, inevitably, be times when you can’t reach an agreement together. This is a natural part of being involved in something complex. When this happens, be very careful how you escalate – it’s easy to accidentally ruin a great relationship. Be sensitive but realistic – if you’re unable to reach an agreement then this will be obvious to them as well, and they will be looking for some help and advice from their senior accountable team too.
Escalation works best when both parties do it together, avoiding the drama, and calmly asking for some advice. One of the great things about governance is that these escalation paths exist, so use them well. Escalate together via the next layer up first – never just go straight to the most senior person you can think of! Escalation is not a fight; it’s a request for help resolving something difficult. Agree who you are going to escalate to, and do it together, as one team.
Ultimately, the rules of good data governance are much more simple than you think. If you remember that governance is essentially about people and their anxieties, not documents and procedure, you’ll be able to simplify your approaches and make governance a natural part of the whole rather than a thorn in your side.
What do you think? Get in touch if you have anything to add, or have a data governance need.
As we emerge from the pandemic, for many businesses the biggest concern isn’t being too bold – it’s being too cautious.
Business leaders are looking to accelerate transformation and deliver ambitious new services that are invariably delivered through technology. IT leaders are in the hot seat, and that’s a worry if you’re not 100% confident in your data.
Can you guarantee that data quality meets requirements? Do you have the systems and skills to integrate data from multiple platforms, silos and applications? Can you track where data comes from, and how it is processed at each stage of the journey?
If not, you’ve got a data governance problem.
Without strong, high-quality governance, organisations are at the mercy of inaccurate, insufficient and out-of-date information. That puts you at risk of making poor decisions that lead to lost business opportunities, reputational damage and reduced profits – and that’s just for starters.
What does high-quality data governance look like?
It’s likely that the IT department will own data governance, but the strategy must be mapped to wider business goals and priorities.
As a rough guideline, here are 10 key things that we think must be a part of an effective data governance strategy:
- Data security/privacy: do we have the right measures in place to secure data assets?
- Compliance: are we meeting industry and statutory requirements in areas such as storage, audit, data lineage and non-repudiation.
- Data quality: do we have a system in place to identify data that is poor quality, such as missing data points, incorrect values or out-of-date information? Is such information corrected efficiently, to maintain trust in our data?
- Master/Reference data management: If I look at data in different systems, do I see different answers?
- Readiness for AI/automation: If we are using machine learning or AI, do I know why decisions are being made (in line with regulations around AI/ML)
- Data access/discovery: Are we making it easier for people to find and reuse data? Can data consumers query data catalogues to find information, or do we need to find ways to make this easier?
- Data management: Do we have a clear overview of the data assets we have? This might require the creation of data dictionaries and schema that allow for consistent naming of data items and versioning.
- Data strategy: What business and transformation strategy does our data support? How does this impact the sort of decisions we make?
- Do we need to create an operating model so the business can manage – and gain value from – this data?
Moving from data policy to data governance
As we can see, data governance is about more than simply having an IT policy that covers the collection, storage and retention of data. Effective, high-level data governance needs to ensure that data is supporting the broader business strategy and can be accessed and relied upon to support timely and accurate decision-making.
So how do IT leaders start to move away from the first view of governance to the latter? `
While it can be tempting for organisations to buy an off-the-shelf solution for data governance, it’s unlikely to meet your needs, and may not align with your strategic goals.
Understanding your strategy first means the business can partner with IT to identify the architecture changes that might be needed, and then identify solutions that will meet these needs.
Understanding Lean Data Governance
Here at Equal Experts, we advocate taking a lean approach to data governance – identify what you are trying to achieve and implement the measures needed to meet them.
The truth is that a large proportion of the concerns raised above can be met by following good practices when constructing and operating data architectures. You’ll find more information about best practices in our Data Pipeline and Secure Delivery playbooks.
The quality of data governance can be improved by applying these practices. For example:
- It’s possible to address data security concerns using proven approaches such as careful environment provisioning, role-based access control and access monitoring.
- Many data quality issues can be resolved by implementing the correct measures in data pipelines, such as incorporating observability so that you can see if changes happen in data flows, and pragmatically applying master and reference data so that there is consistency in data outputs.
- To improve data access and overcome data silos, organisations should construct data pipelines with an architecture that supports wider access.
- Compliance issues are often related to data access and security, or data retention. Good implementation in these areas makes achieving compliance much more straightforward.
The field of data governance is inherently complex, but I hope through this article you’ve been able to glean insights and understand some of the core tenets driving our approach.
These insights and much more are in our Data Pipeline and Secure Delivery playbooks. And, of course, we are keen to hear what you think Data Governance means to your organisation. So please feel free to get in touch with your questions, comments or additions on the form below.
Based on the experience shared in evolving a client’s data architecture, we decided to share a reference implementation of data pipelines. Recalling from the data pipeline playbook.
What is a Data Pipeline?
From the EE Data Pipeline playbook:
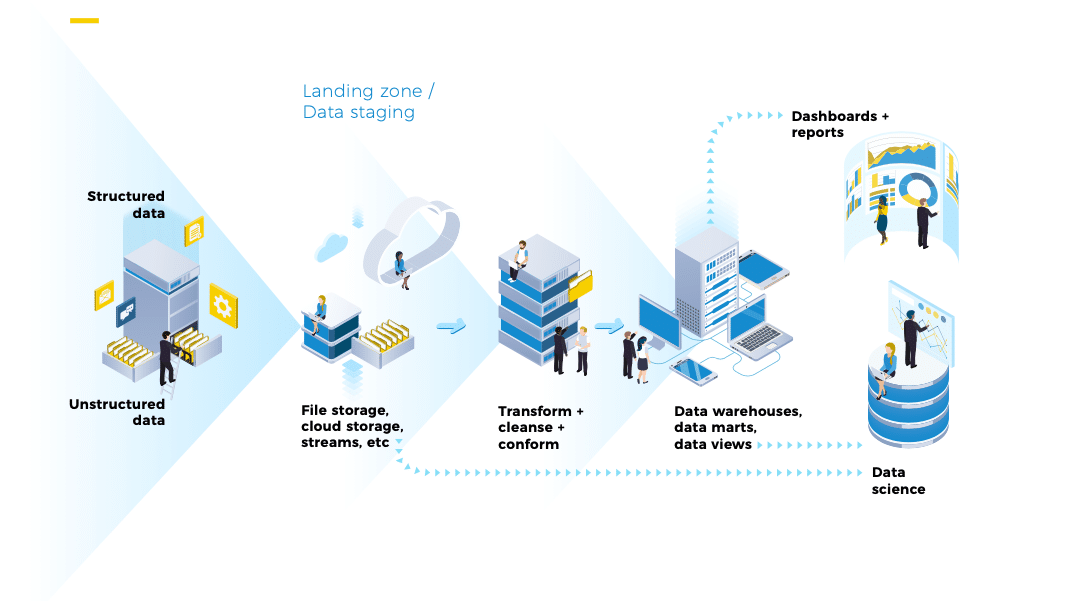
A Data Pipeline is created for data analytics purposes and has:
- Data sources – these can be internal or external and may be structured (e.g. the result of a database call), semi-structured (e.g. a CSV file or a Google Sheet), or unstructured (e.g. text documents or images).
- Ingestion process – the means by which data is moved from the source into the pipeline (e.g. API call, secure file transfer).
- Transformations – in most cases data needs to be transformed from the input format of the raw data, to the one in which it is stored. There may be several transformations in a pipeline.
- Data Quality/Cleansing – data is checked for quality at various points in the pipeline. Data quality will typically include at least validation of data types and format, as well as conforming against master data.
- Enrichment – data items may be enriched by adding additional fields such as reference data.
- Storage – data is stored at various points in the pipeline. Usually at least the landing zone and a structured store such as a data warehouse.
Functional requirements
- Pipelines that are:
- Easy to orchestrate
- Support scheduling
- Support backfilling
- Support testing on all the steps
- Easy to integrate with custom APIs as sources of data
- Easy to integrate in a CI/CD environment
- The code can be developed in multiple languages to fit each client skill set when python is not a first class citizen.
Our strategy
In some situations a tool like Matillion, Stitchdata or Fivetran can be the best approach, although it’s not the best choice for all of our client’s use cases. These ETL tools work well when using the existing pre-made connectors, although when the majority of the data integrations are custom connectors, it’s certainly not the best approach. Apart from the known cost, there is also an extra cost when using these kinds of tools – the effort to make the data pipelines working in a CI/CD environment. Also, at Equal Experts, we advocate we should test each step of the pipeline, and if possible, develop them using test driven development – and this is near impossible in these cases.
That being said, for the cases when an ETL tool won’t fit our needs, we identified the need of having a reference implementation that we can use for different clients. Since the skill set of each team is different, and sometimes Python is not an acquired skill, it was decided not to use the well known python tools that are used these days for data pipelines like Apache Airflow or Dagster.
So we designed a solution using Argo Workflows as the orchestrator. We wanted something which allowed us to define the data pipelines as DAGs like Airflow.
Argo Workflows is a container-native workflow engine for orchestrating parallel jobs on Kubernetes. Argo represents workflows as Dags (Directed Acyclic Graphs), and each step of the workflow is a container. Since data pipelines can be easily modeled as workflow it is a great tool to use. Also, we have freedom to choose which programming language to design the connectors or the transformations, the only requirement is that each step of the pipeline should be containerised.
For the data transformations, we found that dbt was our best choice. Dbt allows the transformations needed between the staging tables and the analytics tables. Dbt is SQL centric, so there isn’t a need to learn another language. Also, dbt has features that we wanted like testing and documentation generation and has native connections to Snowflake, BigQuery, Redshift and Postgres data warehouses.
With these two tools, that is how we ended up with a language agnostic data pipelines architecture that can be easily reused and adapted in multiple cases and for different clients.
Reference implementation
Because we value knowledge sharing, we have created a public reference implementation of this architecture in the github repo which shows a pipeline for a simple use case of ingesting UK COVID-19 data (https://api.coronavirus.data.gov.uk) as an example.
The goal of the project is to have a simple implementation that can be used as an accelerator to other teams. It can be easily adapted to make other data pipelines, to integrate in a CI/CD environment, or to extend the approach and make it work for different scenarios.
The sample project uses a local kubernetes cluster to deploy Argo and the containers which represent the data pipeline. Also a database where COVID-19 data is loaded and transformed and an instance of Metabase to show the data in a friendly dashboard.
We’re planning to add into the reference implementation infrastructure as code to deploy the project on AWS and GCP. Also, we might also work in aspects like facilitating the monitoring of the data pipelines when deployed in a cloud, or using Great Expectations.
Transparency is at the heart of our values
We value knowledge sharing and collaboration, so we hope that this article, along with the data pipelines playbook will help you to start creating data pipelines in whichever language you choose.
Contact us!
For more information on data pipelines in general, take a look at our Data Pipeline Playbook. And if you’d like us to share our experience of data pipelines with you, get in touch using the form below.
If you’re a senior IT leader, I’d like to make a prediction. You have faced a key data governance challenge at some time. Probably quite recently. In fact, there is a good chance that you’re facing one right now. I know this to be true, because clients approach us frequently with this exact issue.
However, it’s not a single issue. In fact, over time we have come to realise that data is a slippery term that means different things for different people. Which is why we felt that deeper investigation into the subject was needed, to gain clarity and understanding around this overloaded term and to establish how we can talk to clients who see data governance as a challenge.
So, what is data governance? And what motivates an organisation to be interested in it?
Through a series of surveys, discussions and our own experiences, we have come to the conclusion that client interest in data governance is motivated by the following wide range of reasons.
1. Data Security/Privacy
I want to be confident that I know the right measures are in place to secure my data assets and that we have the right protections in place.
2. Compliance – To meet industry requirements
I have specific regulations to meet (e.g. health, insurance, finance) such as:
- Storage – I need to store specific data items for specified periods of time (or I can only store for specific periods of time).
- Audit – I need to provide access to specified data for audit purposes.
- Data lineage/traceability – I have to be able to show where my data came from or why a decision was reached.
- Non-repudiation – I have to be able to demonstrate that the data has not been tampered with.
3. Data quality
My data is often of poor quality, it is missing data points, the values are often wrong, or out of date and now no-one trusts it. This is often seen in the context of central data teams charged with providing data to business functions such as operations, marketing etc. Sometimes data stewardship is mentioned as a means of addressing this.
4. Master/Reference Data Management
When I look at data about the same entities in different systems I get different answers.
5. Preparing my data for AI and automation
I am using machine learning and/or AI and I need to know why decisions are being made (as regulations around the use of AI and ML mature this is becoming more pressing – see for example https://ico.org.uk/for-organisations/guide-to-data-protection/key-data-protection-themes/explaining-decisions-made-with-ai/).
6. Data Access/Discovery
I want to make it easier for people to find data or re-use data – it’s difficult for our people to find and/or access data which would improve our business. I want to overcome my data silos. I want data consumers to be able to query data catalogues to find what they need.
7. Data Management
I want to know what data we have e.g. by compiling data dictionaries. I want more consistency about how we name data items. I want to employ schema management and versioning.
8. Data Strategy
I want to know what strategy I should take so my organisation can make better decisions using data. And how do I quantify the benefits?
9. Creating a data-driven organisation
I want to create an operating model so that my business can manage and gain value from its data.
I think it’s clear from this that there are many concerns covered by the term data governance. You probably recognise one, or maybe even several, as your own. So what do you need to do to overcome these? Well, now we understand the variety of concerns, we can start to address the approach to a solution.
Understanding Lean Data Governance
Whilst it can be tempting for clients to look for an off-the-shelf solution to meet their needs, in reality, they are too varied to be met by a single product. Especially as many of the concerns are integral to the data architecture. Take data lineage and quality as examples that need to be considered as you implement your data pipelines – you can’t easily bolt them on as an afterthought.
Here at Equal Experts, we advocate taking a lean approach to data governance – identify what you are trying to achieve and implement the measures needed to meet them.
The truth is, a large proportion of the concerns raised above can be met by following good practices when constructing and operating data architectures – the sorts of practices that are outlined in our Data Pipeline and Secure Delivery playbooks.
We have found that good data governance emerges by applying these practices as part of delivery. For example:
- Most Data security concerns can be met by proven approaches – taking care during environment provisioning, implementing role-based access control, implementing access monitoring and alerts and following the principles that security is continuous and collaborative.
- Many Data Quality issues can be addressed by implementing the right measures in your data pipelines – incorporating observability through the pipelines – enabling you to detect when changes happen in data flows; and/or pragmatically applying master and reference data so that there is consistency in data outputs.
- Challenges with data access and overcoming data silos are improved by constructing data pipelines with an architecture that supports wider access. For example our reference architecture includes data warehouses for storing curated data as well as landing zones which can be opened up to enable self-service for power data users. Many data warehouses include data cataloguing or data discovery tools to improve sharing.
- Compliance challenges are often primarily about data access and security (which we have just addressed above) or data retention which depends on your pipelines.
Of course, it is important that implementing these practices is given sufficient priority during the delivery. And it is critical that product owners and delivery leads ensure that they remain in focus. The tasks that lead to good Data Governance can get lost when faced with excessive demands for additional user features. In our experience this is a mistake, as deprioritising governance activities will lead to drops in data quality, resulting in a loss of trust in the data and in the end will significantly affect the user experience.
Is Data Governance the same as Information Governance?
Sometimes we also hear the term Information Governance. Information Governance usually refers to the legal framework around data. It defines what data needs to be protected and any processes (e.g. data audits), compliance activities or organisational structures that need to be in place. GDPR is an Information Government requirement – it specifies what everyone’s legal obligations are in respect of the data they hold, but it does not specify how to meet those obligations. Equal Experts does not create information governance policies, although we work with client information governance teams to design and implement the means to meet them.
The field of data governance is inherently complex, but I hope through this article you’ve been able to glean insights and understand some of the core tenets driving our approach.
These insights and much more are in our Data Pipeline and Secure Delivery playbooks. And, of course, we are keen to hear what you think Data Governance means. So please feel free to get in touch with your questions, comments or additions on the form below.