
Balancing business opportunities with responsible innovation in Generative AI
Here’s a fact you probably won’t know about me – I went to the same school as Alan Turing.
I mentioned this while appearing as a panellist at the recent Konnecta Ko-Lab: Series 1 discussion in Sydney. Having attended the same educational institution as one of the founding fathers of artificial intelligence, I guess I was always destined to be interested in AI. It’s a fact that certainly grabbed the attention of the audience.
AI, particularly Generative AI, continues to captivate technologists and business leaders worldwide. During the panel, we dived headfirst into the technical aspects of implementing AI, but some of the more compelling and challenging audience questions revolved around how organisations can balance AI’s opportunities with the concerns surrounding the new technology.

How generative AI is impacting business
Generative AI is reshaping the way we create and consume content. It can enhance customer experience through personalisation, streamline business processes and rapidly generate new creative ideas.
But along with the benefits, there are concerns about how Generative AI is impacting business and even society as a whole. These concerns, including data privacy, intellectual property rights, and the use of technology to mislead, deceive or manipulate people, are not new.
However, the speed at which Generative AI tools increased, along with its huge popularity and the ability for any person or business to use them, means it’s vital that people considering implementing AI understand how to innovate ethically and responsibly.
The importance of accountability and transparency
One of the key questions from the event audience was whether businesses can ethically implement AI while still reaping the business and revenue rewards. As a panel, we explored two areas that I believe underpin responsible innovation with AI: accountability and transparency.
As Generative AI is still an emerging technology, the regulations governing its use are also still emerging. Many AI frameworks around the world, including here in Australia, are still under consultation. There is also a lack of industry-standard benchmarks, security policies and reference architectures to help people build AI technologies and assess them for security reasons.
Decisions about how and when to use AI are still largely being driven by organisations themselves – so we’re relying on businesses to innovate but also self-regulate. To innovate responsibly, businesses need to be accountable for the technology they use – including its robustness, its security, and the accuracy of the data informing it. Transparency about how this information is being used, who has access to it and what has been put in place to prevent misuse is also crucial.
The third fundamental of responsible innovation in AI: human-centricity
Alongside compliance and technical robustness, during the panel discussion, I advocated for a third fundamental of AI in a “triangle of responsible innovation”: human-centricity.
Generative AI can create content quickly but it does not replicate human creativity. It’s an enabler for quick idea generation, proofreading or summarising, but it lacks real human empathy to be able to always resonate with audiences authentically.
Additionally, Generative AI reflects the bias in its underlying data, such as social inequality, gender discrimination or minority stereotypes. For instance, it may only generate an image of a white male in his 40s when asked to depict a doctor. Humans are required in the process to recognise this bias in the generated content and act on it.
This in itself can be challenging. After attempting to correct AI’s bias against minority groups, Google overcorrected, enabling users of its Gemini AI to create misleading and historically inaccurate images of people, including the US founding fathers of the US and Vikings, in a variety of ethnicities and genders.
Understand your business aims and collaborate with experts
As the hype around Generative AI continues to grow, more businesses are considering implementing AI within their own operations and workflows. However, all panellists agreed that a business must first define their aims, understand their use cases, and perform a thorough security and risk assessment before they onboard any new tool or start any AI development work.
To successfully embark on AI journey, businesses also need to ensure that leadership teams become fluent in AI and can prioritise use cases that are aligned with their business strategy. Organisations also need to set up an operating model which allows experimentation with AI in a structured way that can then be scaled when needed.
Those who rush into using new tools like Generative AI, without fully considering best practices or how it can add value to their business, risk inviting security issues and wasting time, money and effort on something that might not deliver on the hype. This is especially true with new and rapidly developing technologies such as Generative AI – even large global organisations such as Google, Meta and Microsoft are spending time constantly adapting and improving their understanding of AI and how it should be implemented.
Businesses need expert help and guidance to maximise the resources they invest in any new technology and AI is no different. If you’re interested in exploring how to implement AI in your organisation and maximise the opportunities and benefits it can offer, contact our experts in Australia.
Fourth in a series featuring talks from our recent Geek 23 conference is Lyndsay Prewer, Technical Delivery Manager at Equal Experts, presenting, Consulting with LLMs – how to make ChatGPT say more than “it depends.”
The rise in the popularity and power of large language models (LLMs), such as ChatGPT, Bard and Bing, has led to growing consideration if they can be used to improve how we consult.
This workshop gives attendees a better understanding of the potential and considerations of using LLMs in consulting, as well as practical strategies for leveraging these tools to deliver more value to our clients.
The collective experience and insights of attendees was used to crowdsource answers to the following questions:
- What should we be mindful of when using LLMs (e.g. privacy, bias, sustainability)?
- What practical usages of LLMs have worked well?
- What aspects of LLM usage need further research within EE?
The workshop starts by setting the scene, then describes the goal and approach. A variety of liberating structures will then be used – such as Pecha Kucha, 1-2-4-all – to facilitate the distillation, culminating in a summary of the aggregated answers.
Geek 23 was a specific event for, and led by, our Equal Experts community. Speakers gave talks on a range of topics including service design, developer experience, operability, leadership, distributed systems, testing, large language models, DevOps, mob programming and microservices.
In my first blog post on ChatGPT I noticed that, to get good results for most of the work I wanted, I needed to use the latest model, which is tuned for instruction/chatgpt type tasks (text-davinci-003); the base models just didn’t seem to cut it.
I was intrigued by this, so I decided to have another go at fine-tuning ChatGPT, to see if I could find out more. Base models (e.g. davinci as opposed to text-davinci-003) use pure GPT-3. (Actually, I think they are GPT-3.5 but let’s not worry about that for now). They generate completions based on input text; give them the start of a sentence and they will tell you what the next words will typically be. However, this is different from answering a question or following an instruction.
In the following example you can see the top 5 answers to the prompt “Tell me a story” when using the base GPT-3 model (which is davinci – currently the most powerful we have access to):

You can see from these answers how GPT-3 works; it has found completions based on examples in the training corpus. ‘Tell me a story , mama,” the youngster said. is likely a common completion in several novels. But this is not what I wanted! What I wanted was for ChatGPT to actually tell me a story.
If I give the same query to a different model – text-davinci-003 – I get the sort of results I was looking for. (The answers have been restricted to a short length, but it could carry on extensively.)

Clearly the text-* models have significantly enhanced functionality compared with the standard GPT-3 models. In fact, one of the important things that ChatGPT has done is focus explicitly on understanding the user’s intention when they create a prompt. And as well as allowing ChatGPT to understand the intention of the user, the approach also prevents it from responding in toxic ways.
How they do this is fascinating; they use humans in the loop, and reinforcement learning. First, a group of people create the sort of training set you’d expect in a supervised learning approach. For a given prompt “Tell me a story”, a person creates the response “Once, upon a time there was a …” These manually created prompt-response pairs are used to fine-tune ChatGPT’s base model. Then, people (presumably a different group of people) are used to evaluate the performance by ranking outputs from the model – this is used to create a separate reward model. Finally, the reward model is used in a reinforcement learning approach to update the fine-tuned model made in the first stage. (Reinforcement learning is an ML technique where you try lots of changes and see which ones do better against some reward function. It’s the approach that DeepMind used to train a computer to play video games.)
It’s worth noting the sort of investment required to do this. Using people to label and evaluate machine learning outputs is expensive, but it is a great way to improve the performance of a model. In recent LinkedIn posts I have seen people claiming to have been offered jobs to do this sort of work, so it looks like OpenAI are continuing to refine the model in this way. Reinforcement learning is usually a very expensive way of learning something; reinforcement learning on top of deep learning is even more expensive, so there has clearly been a lot of time, effort and money expended in developing the model.
ChatGPT are open in their approach – here’s their take on how to use ChatGPT; I really applaud their openness. I’m aware there are a lot of negative reactions to the tool, but it’s worth pointing out that the developers are clearly aware that the model is not perfect. If you look at the limitations section of the document they note several things including:
- It can still generate toxic or biased outputs
- It can be instructed to produce unsafe outputs
- It is trained only in English, so will be culturally-biased to English-speaking people
In my opinion, generative models are not deterministic in their outputs so these sorts of risks will always remain. But I think serious thought and expense has been applied in order to reduce the likelihood of problematic results.
I started this investigation into fine-tuning ChatGPT because I noticed that I wasn’t able to fine-tune on the text-* versions of the model. In fact, it clearly states in the ChatGPT fine-tuning guide that only the base models can be fine-tuned. Now I understand why. Unfortunately, I also understand better that the text-* models are those which have been improved with the human in the loop process. And these are the ones that have a lot of the secret sauce for ChatGPT; it is the refinement using human guidance that gives it that fantastic human-like ability which seems so impressive.
The implication for the use-cases I had in mind – fine-tuning ChatGPT to specific contexts, such as question answering about Equal Experts – is that you cannot use the model which understands your intention. So you will not get the sort of natural-sounding responses we see in all the examples people have been posting on the internet. That’s a bit sad for me, but at least now I know.
Pretty much everyone by now has heard of – and probably played with – ChatGPT (If you haven’t, go to https://openai.com/blog/chatgpt/ to see what all the fuss is about.); it’s a chatbot developed by OpenAI based on an extremely large natural language processing model, which automatically answers questions based on written prompts.
It’s user friendly, putting AI in the hands of the masses. There are loads of examples of people applying ChatGPT to their challenges and getting some great results. It can tell stories, write code, or summarise complex topics. I wanted to explore how to use ChatGTP to see if it would help with the sorts of technical business problems that we are often asked to help with.
One obvious area to exploit is its ability to answer questions. With no special training I asked the online ChatGPT site “What is Continuous Delivery?”

That’s a pretty good description and, unlike traditional chatbots, it has not been made from curated answers. Instead, it uses the GPT-3 model which was trained on a large corpus of documents from CommonCrawl, WebText, Wikipedia articles, and a large corpus of books. GPT-3 is a generative model – if you give it some starter text it will complete it based on what it has encountered in its training corpus. Because the training corpus contains lots of facts and descriptions, ChatGPT is able to answer questions. (Health warning – because the corpus contains information that is not always correct, and because ChatGPT generates responses from different texts, in many cases the answers sound convincing but might not be 100% accurate.)
This is great for questions about generally known concepts and ideas. But what about a specific company. Can we use ChatGPT to tell us about what an individual company does?
- Can it immediately answer questions about a company, or does it need to be provided with more information? Can customers and clients use ChatGPT to find out more about an organisation?
- If we give it specific texts about a company can it accurately answer questions about that company?
Let’s look at the first question. We’ll pretend I’m a potential customer who wants to find out about Equal Experts.
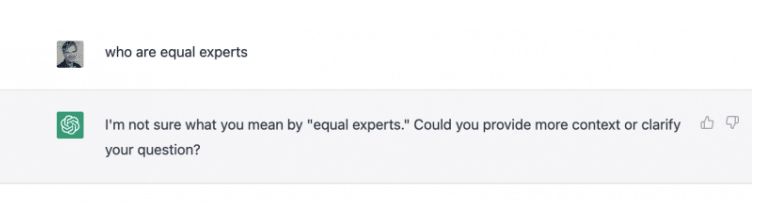
That’s disappointing. Let’s try rephrasing:

It’s still not the answer I was hoping for. Although I do now know that I need a diverse team with a range of skills!
Clearly ChatGPT is great for general questions but won’t help potential customers find out about Equal Experts (or most other businesses.) So maybe I can improve things. ChatGPT has the ability to ‘fine-tune’ models. You can provide additional data – extra documents which contain the information you want – and then retrain the model so it also uses this new information.
So, can we fine-tune GPT to create a model which knows about Equal Experts? I found some available, good quality text on Equal Experts – the case-studies on our website – and used it as training material.
I wrote a small number of sample questions and answers for individual case-studies and submitted them for training. I used a simplified approach to the one given by OpenAI. (For those interested I didn’t use a discriminator because of the low training data volumes.) I then asked some questions for which I knew the answers were in the training data, and displayed the top 5 answers from our new model via the ChatGPT API:

I think we can agree that these are not great results. I should caveat with the fact that creating training examples takes a lot of time. (It is often the biggest activity in an AI or machine learning initiative.) The recommendation is to use 100s of training examples for ChatGPT and I only created 12 training prompts. So results could well be improved with a bigger training set. On the other hand, one of the big selling points of GPT-based models is that they facilitate one-shot or few-shot learning (only needing a few examples to train the model on a new concept – in this case Equal Experts). So I’m disappointed that training has made no difference and that the answers are poor compared to the web interface.
In fact the results are also affected by the training procedure. The training approach to using ChatGPT gives a context first (some text), then a question, then the answer. If I give context with the question (e.g. some relevant text such as an EE case study) and then ask a question, ChatGPT responds much better.

These are much better answers (although far from perfect), but I have had to supply relevant text in the first place, which rather defeats the object of the exercise.
So, could I get ChatGPT to identify the relevant text to use as part of the prompt? You can, in fact, use ChatGPT to generate embeddings – a representation of the document as a mathematical vector – which can be used to find similar documents. So this suggests a slightly different approach:
- For each case-study – generate embeddings
- For a given question – find the case-studies which are most similar to the question (using the embeddings)
- Use the similar case-studies as part of the prompt
This gives some pretty good responses; this image shows the top 5 responses for some questions about our case studies:

These look like pretty relevant responses but they’re a bit short, and they definitely don’t contain all the available information in the case-studies. It turned out that the default response size is 16 tokens (sort of related to word count). When I set it to 200 I get these results for what is a data health check:

Well that’s a much better summary, and it gave good results for other queries also:

Throughout this activity, I found a number of other notable points:
- Using the right model in ChatGPT is really important. I ended up using the latest model, which is tuned for instruction/chatgpt type tasks (text-davinci-003), and got good results for most of the work. Base models (e.g. davinci) just didn’t seem to cut it. This matters when you are thinking of fine-tuning a model because you cannot use the specialised models as the basis of a new one.

- The davinci series models used a lot of human feedback as part of their training, so they give the best results compared to simpler models. (Although I accept the need to experiment more.)
- Quite often the model would become unavailable and I would get the following message. If you want to use the API in a live service, be aware that this can happen quite regularly.

- Each question cost about 5-6 cents.
I have noticed a wide range of reactions from people using ChatGPT, from ‘Wow- this will change the world!’ to ‘It’s all nonsense – it’s not intelligent at all.’ – even amongst people with AI backgrounds. Having played with it, I think there are lots of tasks it can help with; organisations that can figure out where it will help them and how to get the most out of it will really benefit. Watching how things play out with Chat GPT and its successors (hello GPT-4) is going to be a fascinating ride.