Haystack: A deep learning-based question-answering framework
<tl;dr>
Haystack is a question-answering framework – a tool to answer natural language questions from a text corpus which uses AI deep learning techniques to do the natural language processing. If you give it a bunch of wikipedia articles on Game of Thrones and ask “Who is the father of Arya Stark,” it will tell you “Lord Eddard Stark,” and “Ned“, and give you the text which supports it. I made a quick subjective evaluation to see what it can do. It worked pretty much out of the box and has a useful set of tutorials and code samples. Results are pretty good but not perfect, and you can improve them by changing the complexity of the model, or refining the model using your own data.
What is Haystack?
Haystack is a question-answering framework – a tool to answer natural language questions from a text corpus. It can handle the typical ways of storing documents – PDF, doc, txt etc., and uses deep learning technologies (specifically transformer networks), to improve on traditional pattern-matching or NER techniques.
Does it work?
We have several clients who need to search large document corpuses so I decided to have a look at Haystack to see what it can do. I started at the Get Started page in the documentation and tried it out. Quick tip: I needed to increase the memory available to my Docker environment before it would run correctly, but apart from that it worked using the instructions provided.
The demo comes with about 2,500 documents about the Game of Thrones series hosted on an ElasticSearch instance. A sample document is:
”A Man Without Honor” is the seventh episode of the second season of HBO’s medieval fantasy television series ”Game of Thrones.” The episode is written by series co-creators David Benioff and D. B. Weiss, and directed, for the second time in this season, by David Nutter. It premiered on May 13, 2012. The name of the episode comes from Catelyn Stark’s assessment of Ser Jaime Lannister: “You are a man without honor,” after he kills a member of his own family to attempt escape.
I tried the following questions on the corpus.
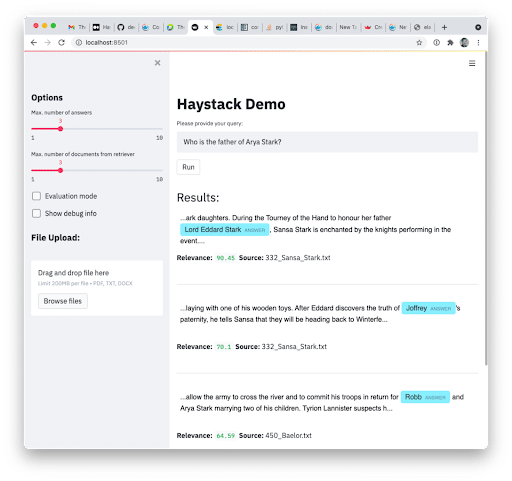
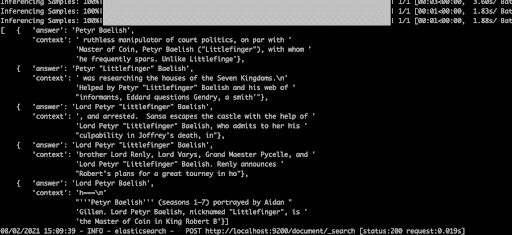
Question 1: Who is the father of Arya Stark?
This is the suggested test query. The first result is great. The second and third are wrong (although their scores are much lower).
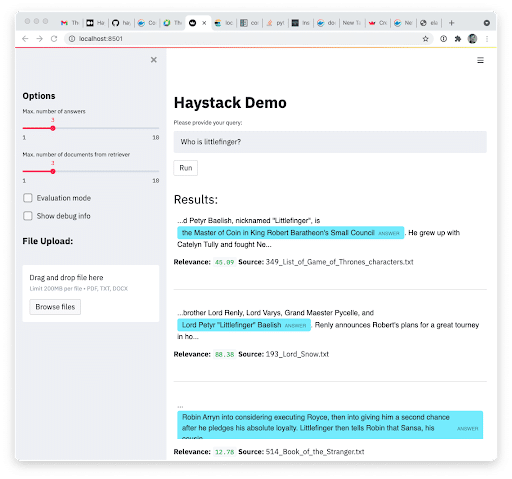
Question 2: Who is littlefinger?
The first two results are great (curiously the UI does not show them in relevance order). The last is wrong.
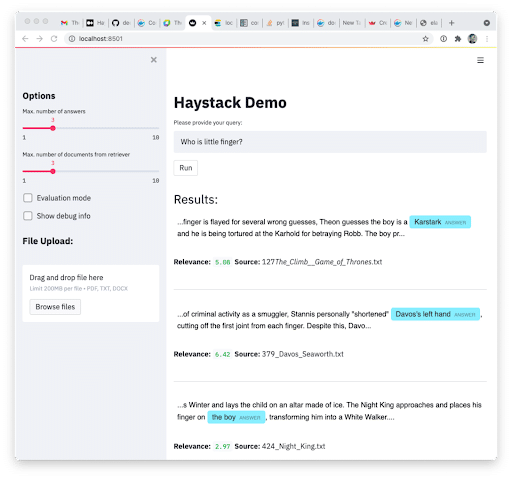
Q3: Who is little finger?
This is the same question as Q2 but with a space in the key term. None of these results are correct.
How does it work?
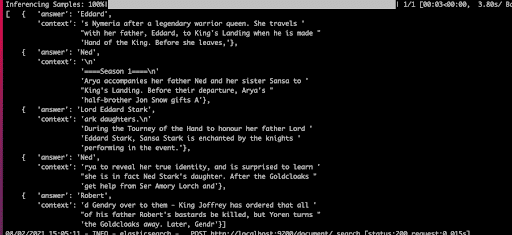
It’s straightforward to create a question answering method from documents in a corpus. This code snippet asks a question about documents stored in an ElasticSearch document store.
prediction = pipe.run(query=”Who is the father of Arya Stark?”, top_k_retriever=10, top_k_reader=5)
print_answers(prediction, details=”minimal”)
The most important stages in the pipeline are:
Retriever – does an initial filter of the documents to find ones which might have the answer. In most cases this uses a simple TF-IDF or similar approach.
Reader – looks at the documents returned by the retriever and extracts the best answers. The readers use deep learning transformer networks. In the example code above it is using a RoBERTa model. You can use models from Huggingfaceor similar. Different models allow you to trade off between accuracy, speed and available processing power.
Can you improve the results?
The results fundamentally depend on the model utilised in the reader stage and can be improved by changing the model. I tried changing it to the bert-large-uncased-whole-word-masking-squad2 model which is bigger (1.34GB compared to 1.4MB), but ran fine on my MacBook Pro.
The results were quite a bit better.
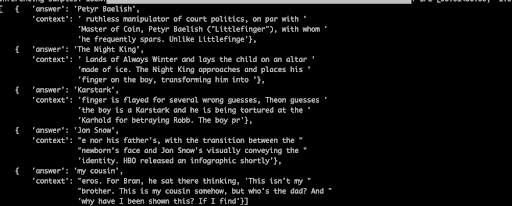
Question 1: Who is the father of Arya Stark?
It gets the right answer most of the time and finds a variety of names for him.
Question 2: Who is littlefinger?
This gives spot-on answers – 100% correct.
Question 3: Who is little finger?
The mistyping with the space between the words still leads to some incorrect results. The first result is correct but the rest are wrong. All in all it’s definitely an improvement.
You can also fine-tune a model. You can collect examples of questions and answers and use them to update the model. Haystack provide an annotation tool to help with this (The manual is here.) Once you have your data it seems straightforward to refine the model:
Apart from improved search you can also use Haystack to:
Return a novel answer composed to a question (Using Generators)
Summarize all the answers into a single response
Translate between languages
Question answers on data stored in knowledge graphs (instead of as documents). Sadly it does not yet generate a knowledge-graph from text 🙁
The repo is here. I found this article to be a useful introduction to Haystack.
You may also like
Blog
Anyone Can Usability Test, Part 3: Making the Most of Your Findings
Blog
Do we need roles in a cross functional team?
Blog
It’s the difference between ‘doing agile’ and ‘being agile’
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.