ML solutions need to be monitored for errors and performance just like any other software solution. ML driven products typically need to meet two key observability concerns:
Monitoring the model as a software product that includes metrics such as the number of prediction requests, its latency and error rate.
Monitoring model prediction performance or efficacy, such as f1 score for classification or mean squared error for regression.
Monitoring as a Software Product
As a software product, monitoring can be accomplished using existing off the shelf tooling such as Prometheus, Graphite or AWS CloudWatch. If the solution is created using auto-generated ML this becomes even more important. Model code may be generated that slows down predictions enough to cause timeouts and stop user transactions from processing.
You should ideally monitor:
Availability
Request/Response timings
Throughput
Resource usage
Alerting should be set up across these metrics to catch issues before they become critical.
Monitoring model prediction performance
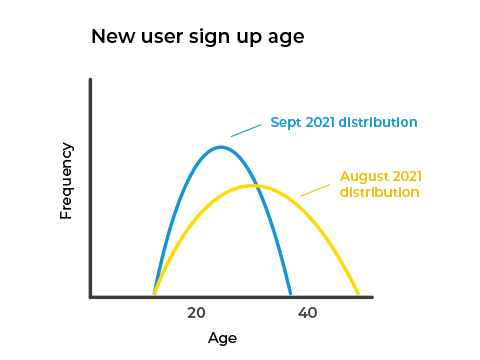
ML models are trained on data that’s available at a certain point in time. Data drift or concept drift happens when the input data changes its distributions, which can affect the performance of the model. Let’s imagine we have a user signup model that forecasts the mean basket sales of users for an online merchant. One of the input variables the model depends on is the age of the new users. As we can see from the distributions below, the age of new users has shifted from August to September 2021.
It is important to monitor the live output of your models to ensure they are still accurate against new data as it arrives. This monitoring can provide important cues when to retrain your models, and dashboards can give additional insight into seasonal events or data skew.
There are a number of metrics which can be useful including:
Precision/Recall/F1 Score.
Model score outputs.
User feedback labels or downstream actions
Feature monitoring (Data Quality outputs such as histograms, variance, completeness).
The right metrics for your model will depend on the purpose of the model and the ability to access the performance data in the right time frame.
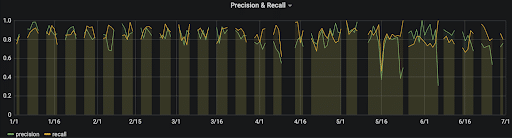
Below is an example of a classification performance dashboard that tracks the precision and recall over time. As you can see, the model’s performance is becoming more erratic and degrading from 1st April onwards.
Alerting should be set up on model accuracy metrics to catch any sudden regressions that may occur. This has been seen on projects where old models have suddenly failed against new data (fraud risking can become less accurate as new attack vectors are discovered), or where an auto ML solution has generated buggy model code. Some ideas on alerting are:
% decrease in precision or recall.
variance change in model score or outputs.
changes in dependent user outputs e.g. number of search click throughs for a recommendation engine.
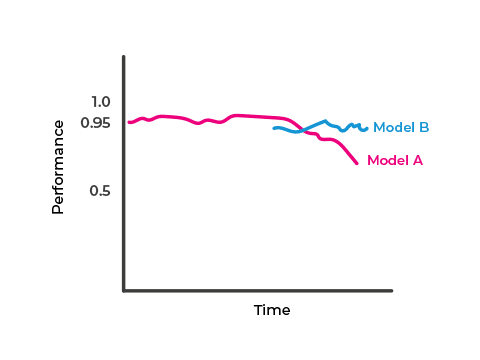
The chart below illustrates that model A’s performance degrades over time. A new challenger model, B, is re-trained on more recent data and becomes a candidate for promotion.
Data Quality
A model is only as good as the data it’s given, so instrumenting the quality of input data is crucial for ML products. Data quality includes the volume of records, the completeness of input variables and their ranges. If data quality degrades, this will cause your model to deteriorate.
To read more about monitoring and metrics for MLOps, download our new MLOps playbook, “Operationalising Machine Learning”, which provides comprehensive guidance for operations and AI teams in adopting best practice.
You may also like
Blog
How Should You Do Big Data on Cloud?
Blog
What do practitioners see as the main challenges in Operationalising Machine Learning solutions?
Blog
From QA to delivery lead…with Karunakar Thedla
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.