Understanding event-driven architecture and microservices in comparison to a monolith.
If you’re not consciously aware of the limitations of a monolithic architecture, you’ll likely be familiar with the practical shortfalls and how they can cripple an organisation.
Do any of the following symptoms ring a bell?
You spend the vast majority of your capacity focused on end-to-end testing or bug fixing, rather than delivering new product features to better serve customers.
Your application is slow. You constantly get complaints from customers about speed and reliability, while product teams and internal stakeholders complain that ‘technology and development’ takes far too long.
You’re struggling to scale and cope with increased load on your system.
You have vast amounts of potentially usable data, but you can’t harness it to make strategic decisions or improve customer experience in real-time.
If any of the above seem familiar, you may benefit from a process of digital transformation: transitioning to a microservices approach with event-driven architecture.
Before you can begin to entertain that decision, let’s define some terms.
What are microservices?
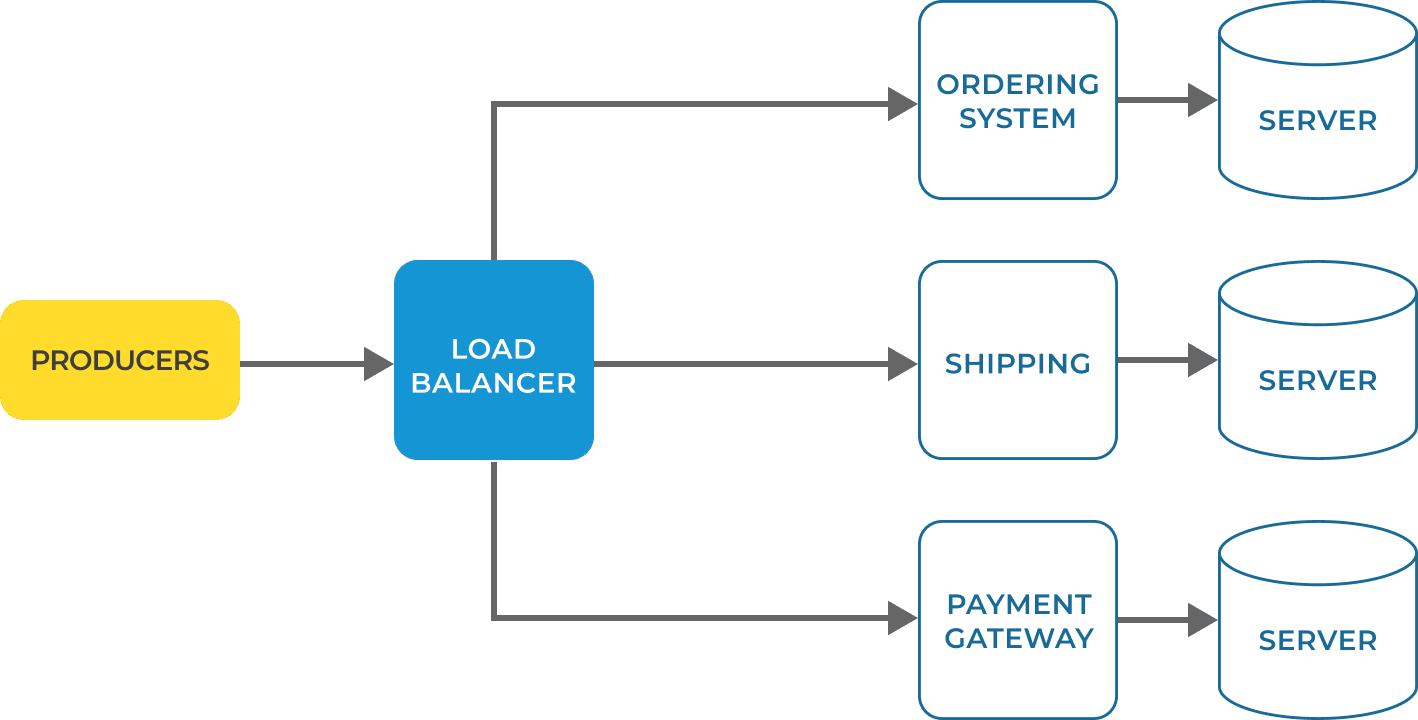
It’s easiest to understand microservices in contrast to a monolithic architecture; a monolith being a system or application where multiple elements are subsumed into the one entity.
For example, a monolithic application for online retail might contain a server, a load balancer, an ordering system, a payment gateway, and a shipping component.
In contrast, microservices take the various functions and responsibilities of an application—you could have five or five hundred—and break them out into distinct, separate, and individually deployable units.
What are the benefits of microservices?
There are many. Perhaps the most compelling benefits for large scale organisations—both public and private sector—are that you can:
Decrease the negative impact of shared mutable data
Imagine you have 500 developers supporting a monolithic application. In this scenario, there are no clear boundaries outlining the role of certain blocks of code.
The lack of boundary—and subsequent overlap or double handling between teams—is the phenomenon of shared mutable data. This makes the code hard to maintain. It makes deployment difficult. And, it makes release cycles slow.
By adopting microservices, you create and enforce hard boundaries in your code that allow teams to move independently and asynchronously. Ultimately, that means delivering more value, faster.
Additionally, microservices empower teams to maintain discrete applications using their own preferred:
Tools of choice
Development languages of choice
Frameworks of choice
Data stores of choice
Happier, self-determined technical teams typically make for faster, better, and more robust development.
Save money by calibrating infrastructure and performance profiles for specific application requirements
In all likelihood, the different services that comprise your application will have different performance requirements. As a quick example, consider the distinction between:
A non-critical service that is accessed every three hours on Sundays to perform a background data processing function
An incredibly high-load elastic search service
With microservices, you have the flexibility to provision the exact infrastructure—no more, no less—that is required to support the unique function of each distinct service.
In a monolithic approach, you are constrained by a ‘highest common denominator’ approach. And, you’re forced to wear the equally high costs associated with overcompensating on unnecessary infrastructure. Why buy a sledgehammer when you only need to crack a peanut?
Increase speed of deployment, by decreasing the implications and impact of testing
With a monolith, if you make a change, that change is made in the context of multiple interconnected services with various cascading interdependencies.
The potential consequence of any issue can reverberate throughout the entire monolithic application. As a result, you effectively have to test everything whenever you deploy a change.
With a microservices approach, the monolith is broken down into, say, ten individual services. If you make an update, you only need to test a tenth of the codebase.
Microservices are typically independent of each other. By only testing and deploying through a singular and distinctive service, you minimise the potential impact radius or cascading issues associated with any bug, downtime, or failure.
What are some common triggers for moving from a monolithic architecture to microservices?
In addition to the symptoms outlined above, you may also benefit from moving away from a monolith if:
You have rapidly expanding and diverse technical teams. This largely pertains to the issues associated with shared mutable data.
You have slowed velocity of feature delivery and deployment. If you’re unable to deploy new features quickly—or you’re falling behind in comparison with competitors—a shift to microservices can increase the pace of your development cadence.
So, how do events relate to microservices? What is event-driven architecture?
An event is a construct that allows your code to announce—whether to everyone or no one—that some state internal to that code has changed. Events allow you to make that announcement in a way that prevents external code from accessing a unique service’s internal state.
Events typically map to real-world actions or business triggers. Examples can include:
An action taken by a customer: someone updates their account details, submits a payment, navigates to a content page on a website, etc.
An Internet-of-Things event: a turnstile registering the amount of people entering a venue or arena, for example.
Technical changes within an application: like updates to a database, for example.
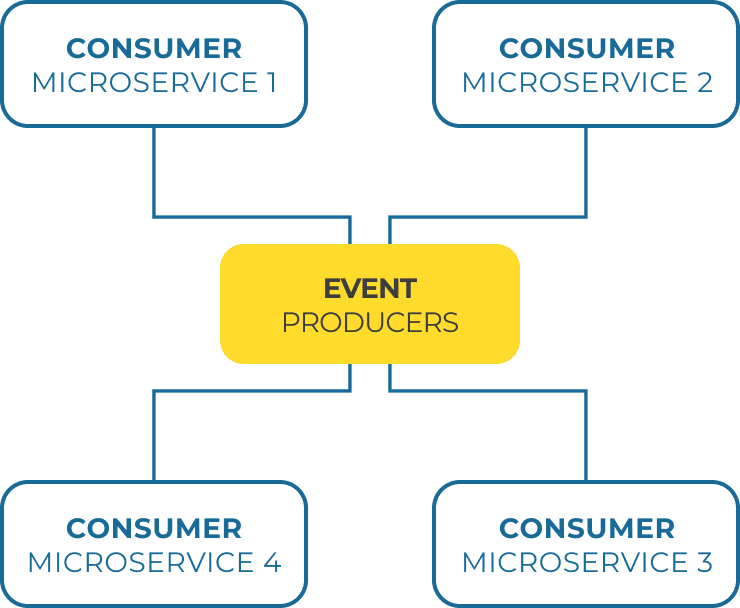
In an event-driven architecture, events act as signals for consumers. These consumers can trigger subsequent business processes, updates, or state-changes.
And the individualised services that facilitate these business processes by producing and consuming events? You guessed it: microservices.
When events and microservices come together in a practical sense—like in the context of banking—event-driven architectures can provide real-time, highly detailed transaction information for customers while promoting improved regulatory compliance for banks.
Crucially, event-driven architecture is considered a ‘receiver-driven’ routing pattern. In other words, services are configured to ‘pull’ data packets (read: events) if they are available to complete a function, rather than indiscriminately ‘pushing’ information through a synchronous, sequential chain of services that may be struggling to manage load.
For example, ‘service A’ will publish an event to notify of a change in state. This is called a producer.
Any number of consumers in the system can subscribe to this notification, become aware of the change in state, and update their own internal state(s) as a result.
In an event-driven architecture, there are no hard or sequential dependencies between these producers and consumers.
This creates significant improvements for speed of processing, while protecting against the potential for cascading deficiencies in the event of a service outage.
If any single consumer fails to register the series of events it is programmed to subscribe to, the consequence is that one single microservice’s internal state will become stale.
Simple antipatterns to avoid when adopting microservices or event-driven architecture.
There are many, many considerations to be mindful of. Three basic tips include:
1. Avoid throwing away any data.
If you have the right configurations in place—like a data pipeline with a batched analytical data lake—events can be useful long before you determine their immediate use case.
Often, we see developers and engineers make the mistake of configuring an event that may have 50 properties on it, only to incorrectly assume that only ~10 of those properties are valuable for other teams or services downstream. As a result, valuable data is lost without being published.
There’s huge value to be gained—and very little to lose—by configuring and capturing as many events as possible. By recording more data in the form of events, you can:
Rehydrate historical events for evolving business considerations moving forward, like developing user profiles for real-time fraud mitigation
Funnel events into a data lake for big data processing and analysis
Importantly, it’s worth drawing a distinction between keeping data in the form of events and publishing data in the form of events.
Publishing ‘everything’ can run the risk of tying the event producer(s) to some maximal set of data that may be very difficult to change in the future.
Instead, it’s better to establish a topic to hold all of the event-based data in its original form, before the data is cleaned and published for a wider audience.
A recommended configuration or workflow may be something like:
Input produces events
Input publishes events to an ‘internal’ topic of all raw data, not meant for consumption beyond current domain boundaries
The raw data is transformed on this ‘internal’ topic
The data is published for wider consumption
2. Avoid issuing events as commands.
Be conscious of the fact that an event is merely something that has happened, not an instruction for something else to happen. The difference is nuanced, but crucial to maintain. Failure to maintain this distinction can lead to issues.
3. Avoid being too aware of the requirements of your consumers.
As a supplement to the above, by structuring events with specific services in mind, you effectively couple producers with consumers. Remember, many of the benefits of microservices and event-driven architectures are contingent on the independence of each service; consciously building interdependencies into your approach is directly counterintuitive and undermines overall efficacy.
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.