Common pitfalls of data pipeline projects, and how to avoid them
Knowing, understanding and managing your data throughout its lifecycle is more important than it has ever been. And more difficult.
Of course, the never ending growth in data volume is partly responsible for this, as are also countless processes that need to be applied to the data to ensure it is usable and effective. Which is why data analysts and data engineers turn to data pipelining.
Added complexity is involved when, In order to keep abreast of the latest requirements, organisations need to constantly deploy new data technologies alongside legacy infrastructure.
All three of these elements mean that, inevitably, data pipelines are becoming more complicated as they grow. In the final article in our data pipeline series, we have highlighted some of the common pitfalls that we have learned from our experience over the years and how to avoid them. These are also part of our Data Pipeline Playbook.
About this series
This is the final post in our six part series on the data pipeline, taken from our latest playbook. Now we look at the many pitfalls you can encounter in a data pipeline project. In the series before now, we looked at what a data pipeline is and who it is used by. Next we looked at the six main benefits of a good data pipeline, part three considered the ‘must have’ key principles of data pipeline projects, and part four and five covered the essential practices of a data pipeline. So here’s our list of some of the pitfalls we’ve experienced when building data pipelines in partnership with various clients. We’d encourage you to avoid the scenarios listed below.
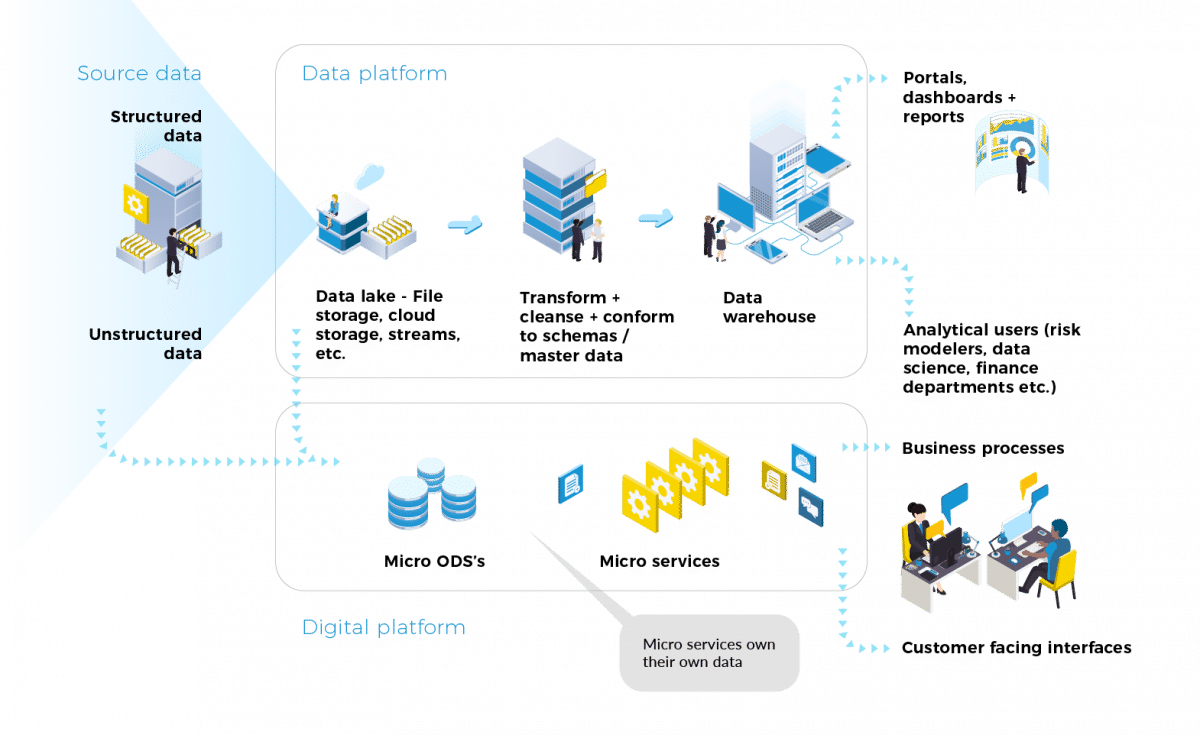
Avoid tightly coupling your analytics pipelines with other business processes
Analytics data pipelines provide data to produce insights about your customers, business operations, technology performance, and more. For example, the role of a data warehouse is to create an historical record of data that can be mined for insights.
It is tempting to see these rich data sources as the best source of data for all data processing and plumb key business activities in these repositories. However, this can easily end up preventing the extraction of insights it was implemented for. Data warehouses can become so integrated into business operations – effectively acting as the Operational Data Store (ODS) – that they can no longer function as a data warehouse. Key business activities end up dependent on the fast processing of data drawn from the data warehouse, which prevents other users from running queries on the data they need for their analyses.
Modern architectures utilise a micro-service architecture, and we advocate this digital platform approach to delivering IT functionality (see our Digital Platform Playbook). Micro-services should own their own data – and as there is unlikely to be a one-size-fits-all solution to volumes, latencies, or use of master or reference data of the many critical business data flows implemented as micro-services. Great care should be taken as to which part of the analytics data pipelines they should be drawn from. The nearer the data they use is to the end users, the more constrained your data analytics pipeline will become over time, and the more restricted analytics users will become in what they can do.
If a micro-service is using a whole pipeline as part of its critical functionality, it is probably time to reproduce the pipeline as a micro-service in its own right, as the needs of the analytics users and the micro-service will diverge over time.
Include data users early on
We are sometimes asked if we can implement data pipelines without bothering data users. They are often very busy interfacing at senior levels, and as their work provides key inputs to critical business activities and decisions, it can be tempting to reduce the burden on them and think that you already understand their needs.
In our experience this is nearly always a mistake. Like any software development, understanding user needs as early as you can, and validating that understanding through the development, is much more likely to lead to a valued product. Data users almost always welcome a chance to talk about what data they want, what form they want it in, and how they want to access it. When it becomes available, they may well need some coaching on how to access it.
Keep unstructured raw inputs separate from processed data
In pipelines where the raw data is unstructured (e.g. documents or images), and the initial stages of the pipeline extract data from it, such as entities (names, dates, phone numbers, etc.), or categorisations, it can be tempting to keep the raw data together with the extracted information. This is usually a mistake. Unstructured data is always of a much higher volume, and keeping it together with extracted data will almost certainly lead to difficulties in processing or searching the useful, structured data later on. Keep the unstructured data in separate storage (e.g., different buckets), and store links to it instead.
We hope that this article, along with all the others in the series, will help you create better pipelines and address the common challenges that can occur when building and using them. Data pipeline projects can be challenging and complicated, but done correctly they securely gather information and allow you to make valuable decisions quickly and effectively.
Contact us!
For more information on data pipelines in general, take a look at our Data Pipeline Playbook. And if you’d like us to share our experience of data pipelines with you, get in touch using the form below.
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.