Adventures in how to use ChatGPT – can it answer questions about my business?
Pretty much everyone by now has heard of – and probably played with – ChatGPT (If you haven’t, go to https://openai.com/blog/chatgpt/ to see what all the fuss is about.); it’s a chatbot developed by OpenAI based on an extremely large natural language processing model, which automatically answers questions based on written prompts.
It’s user friendly, putting AI in the hands of the masses. There are loads of examples of people applying ChatGPT to their challenges and getting some great results. It can tell stories, write code, or summarise complex topics. I wanted to explore how to use ChatGTP to see if it would help with the sorts of technical business problems that we are often asked to help with.
One obvious area to exploit is its ability to answer questions. With no special training I asked the online ChatGPT site “What is Continuous Delivery?”
That’s a pretty good description and, unlike traditional chatbots, it has not been made from curated answers. Instead, it uses the GPT-3 model which was trained on a large corpus of documents from CommonCrawl, WebText, Wikipedia articles, and a large corpus of books. GPT-3 is a generative model – if you give it some starter text it will complete it based on what it has encountered in its training corpus. Because the training corpus contains lots of facts and descriptions, ChatGPT is able to answer questions. (Health warning – because the corpus contains information that is not always correct, and because ChatGPT generates responses from different texts, in many cases the answers sound convincing but might not be 100% accurate.)
This is great for questions about generally known concepts and ideas. But what about a specific company. Can we use ChatGPT to tell us about what an individual company does?
Can it immediately answer questions about a company, or does it need to be provided with more information? Can customers and clients use ChatGPT to find out more about an organisation?
If we give it specific texts about a company can it accurately answer questions about that company?
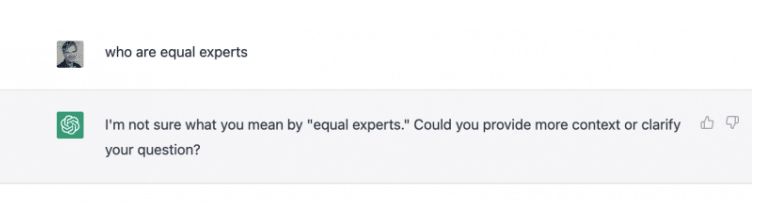
Let’s look at the first question. We’ll pretend I’m a potential customer who wants to find out about Equal Experts.
That’s disappointing. Let’s try rephrasing:
It’s still not the answer I was hoping for. Although I do now know that I need a diverse team with a range of skills!
Clearly ChatGPT is great for general questions but won’t help potential customers find out about Equal Experts (or most other businesses.) So maybe I can improve things. ChatGPT has the ability to ‘fine-tune’ models. You can provide additional data – extra documents which contain the information you want – and then retrain the model so it also uses this new information.
So, can we fine-tune GPT to create a model which knows about Equal Experts? I found some available, good quality text on Equal Experts – the case-studies on our website – and used it as training material.
I wrote a small number of sample questions and answers for individual case-studies and submitted them for training. I used a simplified approach to the one given by OpenAI. (For those interested I didn’t use a discriminator because of the low training data volumes.) I then asked some questions for which I knew the answers were in the training data, and displayed the top 5 answers from our new model via the ChatGPT API:
I think we can agree that these are not great results. I should caveat with the fact that creating training examples takes a lot of time. (It is often the biggest activity in an AI or machine learning initiative.) The recommendation is to use 100s of training examples for ChatGPT and I only created 12 training prompts. So results could well be improved with a bigger training set. On the other hand, one of the big selling points of GPT-based models is that they facilitate one-shot or few-shot learning (only needing a few examples to train the model on a new concept – in this case Equal Experts). So I’m disappointed that training has made no difference and that the answers are poor compared to the web interface.
In fact the results are also affected by the training procedure. The training approach to using ChatGPT gives a context first (some text), then a question, then the answer. If I give context with the question (e.g. some relevant text such as an EE case study) and then ask a question, ChatGPT responds much better.
These are much better answers (although far from perfect), but I have had to supply relevant text in the first place, which rather defeats the object of the exercise.
So, could I get ChatGPT to identify the relevant text to use as part of the prompt? You can, in fact, use ChatGPT to generate embeddings – a representation of the document as a mathematical vector – which can be used to find similar documents. So this suggests a slightly different approach:
For each case-study – generate embeddings
For a given question – find the case-studies which are most similar to the question (using the embeddings)
Use the similar case-studies as part of the prompt
This gives some pretty good responses; this image shows the top 5 responses for some questions about our case studies:
These look like pretty relevant responses but they’re a bit short, and they definitely don’t contain all the available information in the case-studies. It turned out that the default response size is 16 tokens (sort of related to word count). When I set it to 200 I get these results for what is a data health check:
Well that’s a much better summary, and it gave good results for other queries also:
Throughout this activity, I found a number of other notable points:
Using the right model in ChatGPT is really important. I ended up using the latest model, which is tuned for instruction/chatgpt type tasks (text-davinci-003), and got good results for most of the work. Base models (e.g. davinci) just didn’t seem to cut it. This matters when you are thinking of fine-tuning a model because you cannot use the specialised models as the basis of a new one.
The davinci series models used a lot of human feedback as part of their training, so they give the best results compared to simpler models. (Although I accept the need to experiment more.)
Quite often the model would become unavailable and I would get the following message. If you want to use the API in a live service, be aware that this can happen quite regularly.
Each question cost about 5-6 cents.
I have noticed a wide range of reactions from people using ChatGPT, from ‘Wow- this will change the world!’ to ‘It’s all nonsense – it’s not intelligent at all.’ – even amongst people with AI backgrounds. Having played with it, I think there are lots of tasks it can help with; organisations that can figure out where it will help them and how to get the most out of it will really benefit. Watching how things play out with Chat GPT and its successors (hello GPT-4) is going to be a fascinating ride.
You may also like
Blog
Adventures in fine tuning ChatGPT
Blog
Five ways to ensure your team is motivated to embrace You Build It You Run It
Blog
2022 A busy year – in numbers
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.