Keeping legacy systems healthy: Sensible foundations for any modernisation path
At Equal Experts, we help our customers to build and run modern services and get the best out of their legacy systems.
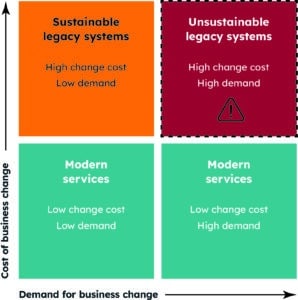
We define a legacy system as one that delivers business value but comes with a high cost of change. It could be a COTS package or a custom-built application, hosted on-premises or in the cloud, AI-free or even a successful AI creation.
At some point, the inability to meet feature demand or to satisfy reliability requirements means something has to change. We’ve spoken about modernisation paths available, but until that decision is made, there are some simple “no regrets” work that will help regardless of the path you take.
Improve observability
To effectively run any service, your team needs visibility and quick feedback on its condition and behaviour. Real-time monitoring and alerting are essential. Metrics like the Four Golden Signals help confirm your services are healthy. Business metrics (checkouts per hour, views per minute, etc.) show whether they’re delivering value. Tools like Datadog or Azure Monitor can help you monitor system health and detect performance issues with built-in tools. With little effort, this foundational monitoring can help catch problems before users notice and, importantly, give you confidence in your deployments. For example, when lifting and shifting a product library service to the cloud, the team added Four Golden Signals monitoring. This paid off shortly after when a CDN cache reset drove all traffic to the origin service. The team spotted this and proactively scaled up, avoiding a costly outage.
Automate your pipeline and deploy regularly
Legacy services often power critical functions, so teams can be wary of change. But avoiding deployments isn’t safer. The longer a service goes between deployments, the harder it becomes to update. At a logistics company, we saw a team struggle to resuscitate a service that hadn’t been deployed in five years. Some dependencies were no longer available, and significant remedial work was needed. That situation is a nightmare if a security patch or urgent fix is needed. Most incidents aren’t caused by deployments but by surprise events (blog post). Mean time to repair (MTTR) matters more than mean time between failures (MTBF). Don’t aim for perfection. Make sure your code is in a code repository with an automated build and look to gently increase deployment frequency. Shifting from quarterly to monthly releases is a big win. We worked with a team that reached fortnightly releases, unlocking faster development and enabling broader transformation (case study).
Be ‘go-minded’ about testing
Legacy services are often tied to multiple test environments with complex dependencies and flaky, expensive, end-to-end tests. Improving observability and automation will have given you confidence that when you go live issues can be spotted quickly and reverted easily. Testing is no longer the single line of defense. As legacy systems are improved it’s important to be more ‘go-minded’, improving flow and with it safety. If you’re upgrading a library or tweaking a config, then re-running weeks’ worth of functional tests is an extremely high cost that can be mitigated by more focused smoke tests and key user journeys. Removing unreliable tests will help you see the wood for the trees. At a distribution company, we sped up releases by targeting flaky tests. We used a tool to find and quarantine them, before fixing or removing them entirely. Tips like these will help make the necessary shift from exhaustive verification to confident iteration.
Next steps
You don’t need a big-bang transformation to invest in your legacy. These modest “no regrets” improvements keep services healthy, dependable, and easier to recover in the event of inevitable surprises. You may not have a lot of time or budget, but if you have any, these are a sound investment and will give you more space to think about next steps. In Rethinking the AWS 6Rs, we showed how organisations can use a cost-focused lens to decide what to do with legacy services. Whatever your strategy: rehosting, replatforming, refactoring, repurchasing, retiring, or retaining – these foundational practices will pave the way for success.
About the author
Olly serves in a global role providing servant leadership to engagement teams and experiential insights to clients across the USA, UK, and Europe. Experienced in scaling major platforms from single-team beginnings to large multi-team ecosystems across UK Government and private sector programmes, as well as supporting fast-growing European scale-ups to build the capabilities needed to accelerate outcomes at speed and scale. Connect with Olly on LinkedIn.
You may also like
Blog
How legacy applications can thrive in an agile world
Blog
Migration and modernisation options for your heritage services – Rethinking the AWS 6Rs
Blog
Heritage services: What they are and why we love them
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.