Combining Data Science and UX Design to Create Data-Driven User Personas
What do Data Science and User Experience have in common?
On the surface, you might expect very little as they appear to oppose one another. How about when attempting to understand human behaviour? Both UX and Data Science specialists try and solve these problems, but with different approaches. On a recent engagement, we found that combining techniques from both disciplines yielded powerful results.
The Problem
Our client wanted to understand their users’ needs while using a job-posting website. User personas are a popular tool for communicating user needs off the back of conducting user research. On this engagement, we wanted to see if we could use some data science techniques to provide quantitative validation of the initial qualitative user research
The Tension Model
We worked in partnership with Koos Service Design. One of the techniques Koos use to develop personas is to investigate conflicting user needs, called “Tensions”. For example, a tension when applying for a job could be the conflict between ‘finding the perfect job’ and ‘finding a job quickly’. Initial research to capture user needs was conducted through in-depth interviews, surveys and exploratory data analysis of user logs.
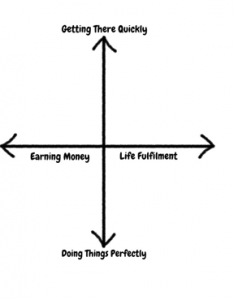
Initial Personas
From this small pool of data, an initial set of tensions was identified onto which personas (detailed below) are placed that encompass the different needs groups of users.
This approach was based on low-volumes of qualitative user research data. To enhance and refine the personas we would need to conduct further testing and experimentation with a much larger dataset.
Machine Learning
With the information gathered during the initial user research, we developed a small survey asking True/False questions aimed at testing our hypotheses about the combination of needs people experienced.
This created an extremely large dataset on which we were able to use machine learning to group users together based on similarity.
The technique utilized was unsupervised k-means clustering. The aim of this is to group (or cluster) data that behaves similarly. An optimal number of 5 clusters was identified using the elbow method to minimise the error in the model without creating too many clusters. So the number of personas was revised to reflect this new information.
Conclusions
There was a lot of similarity between the initial personas and the final data-driven personas. The key divergence was the removal of one persona. However, there were sets of behaviours which persist between the initial and data-driven personas. For example, as the Survivor and the Quick Win, both have a desire to get a well-paid job quickly without any other preferences.
With these personas, the client was able to tailor individual user experiences based on their needs, ultimately improving customer satisfaction and engagement with the system.
This highlights how Data Science can bolster insights from UX design, leading to an end product more useful than using either technique in isolation.
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.