Data mesh is a pattern for structuring an organisation’s data teams, platforms and products. It sounds fancy but in reality it’s stealing the last decade of advances and best practices from modern software development and applying it to data.
What is the problem data mesh is trying to solve? At its core, data mesh rethinks how organisations structure their data systems and teams. Instead of one centralised data function serving the whole business, it distributes ownership to domain teams — the people closest to the data and its use. This shift mirrors how software development evolved from monolithic applications to microservices.
The sections below show how the transforming software principles we are already familiar with can be applied to data.
Data products are analogous to microservices
A data product brings product ownership to data. It consists of:
A data model – the tables and columns that a user queries (the product’s interface)
A data set – The underlying artifact produced at deployment time from the code written by the engineer
Implementation – The data pipeline code, config, infrastructure etc that executes on data or other data products to create the data set
A microservice brings product ownership to software APIs. It consists of:
An API – the parameters and data that a user provides in queries. (The product’s interface)
An executable – The underlying artifact produced at build time from the code written by the engineer
A schema contract – Defines and enforces the interface using checks executed in CI/CD
Implementation – The software code, config, etc that provides instructions for executing API requests when deployed
There are key differences in operational modes between the two, but from an architectural and engineering process perspective, data products and microservices are both independently deployable components with user-accessible interfaces and private implementation details that can be chained together to solve business problems.
Keep on breaking monoliths: Scaling through domains
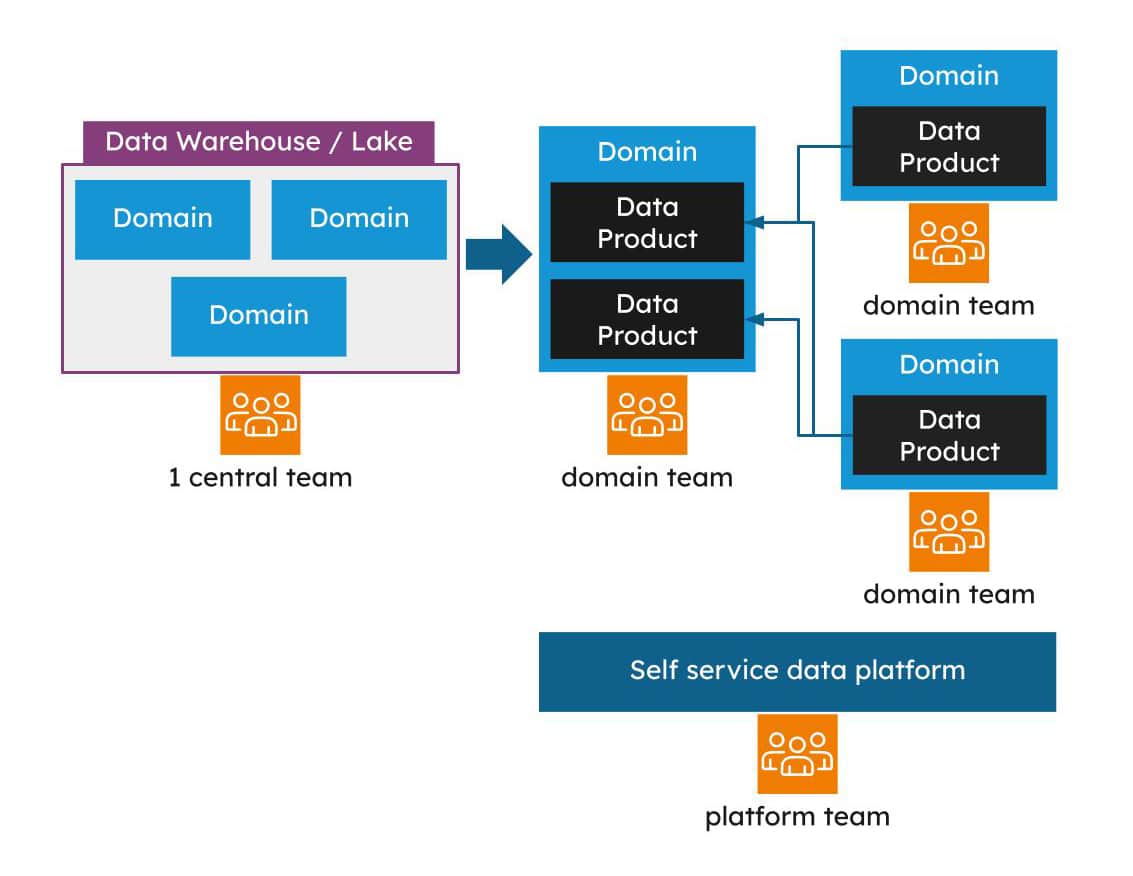
Data teams before data mesh were typically centralised teams that work on the data warehouse – a large interdependent code base comprising multiple domains.
This created a bottleneck for delivery, increased risk of change due to overlapping domain logic, and required teams that were across all of an organisation’s domains in order to work on the code base. This architecture was a key blocker to organisational scaling.
Sound familiar?
The application monoliths suffered from the same problem. Microservices provided composable, deployable units that allowed teams to specialise in domains, and release as they required, so long as they adhered to their API contracts.
Data products provide the same benefit to monolithic data systems. We can now scale out data by applying the same domain driven design principles used in software systems.
Of course, just like monolithic software, a need to scale appropriate for the organisation should be identified before beginning any transformation.
Remember digital platforms? Data needs them too
As can be seen in the diagrams above, a self-serve platform is essential to manage the scaling of both microservice and data products. A self-service data platform provides paved accelerators to build and deploy data products and required infrastructure – just like a self-service digital platform does for microservices. Data and digital may even be the same platform – the team choosing the right workload for the right problem.
Best practices such as security and compliance can be built into the product blueprints, and common changes rolled out across domain teams much faster. By baking in standards, the time and knowledge required to release and maintain quality data products is reduced.
The DataOps movement for data engineering
Here’s a secret: data engineering is easier than ever. As cloud-based data platforms such as Snowflake, Databricks and Big Query have matured, the need to have that data specialist who can finely hone a SQL query over a manually partitioned distributed dataset has gone away.
These modern tools can auto scale and optimise to run queries over data sizes that 5 years ago would’ve required dedicated optimisation & specialists. Most organisations don’t need to process datasets of a size that push the boundaries of these tools. FinOps and usage tracking are still recommended to keep costs down, but the challenge of processing “big data” is not what it used to be.
These tools have also changed to be API first, infrastructure as code driven platforms that are familiar to modern software & platform engineers and don’t require a training course to learn how to use or administer, enabling a DevOps approach to data platform building.
The rise of SQL-as-code tools such as dbt, has allowed for a software engineering approach to data, much like the transformation of infrastructure with Infrastructure as Code tooling. Data pipelines are modelled in a similar way to functions and classes, allowing for decomposition of problems and easier maintenance, while still leveraging SQL as a mature, accessible language. Unit tests and data quality tests can be written side by side, and deployed as one package.
These events have ushered in a new era of DataOps that mirrors the DevOps movement. It’s easier to create working data pipelines over large datasets on scalable tooling than ever before, meaning less specialisation and a wider engineering pool to draw from – meaning we can scale out our domain based data product teams.
The everything mesh
We’ve got domain based microservices, and domain based data products – aren’t these the same domains in our organisation?
Data mesh also proposes cross-functional domain teams – increasing domain knowledge across both operational and data functions and removing silos between the two.
Domain teams consist of engineers who can build products across multiple self service platforms, and focus on the problems they have in common. Team members become generalists with software and data engineers cross-training each other.
Data mesh can be seen as an Everything mesh, aligning the modern application development stack with data by applying the same well proven practices.
The future is the past
Data mesh brings an exciting future to data by applying the hard learned lessons of the software engineering past.
Coupled with the ease of modern data engineering, organisations are in prime position to scale out their data capabilities and cross-train engineers, reusing previous organisational transformation to bring software and data products, and platforms, together across their domains.
You may also like
Blog
Making data mesh real: Transforming existing teams to be domain driven
Blog
Are your microservices hiding data products?
Blog
What we really mean by ‘data products’
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.