If you spend time in data circles, you’ll hear the phrase ‘data product’ used a lot. Everyone agrees they’re important, but if you ask five people what they actually mean, you’ll get five different answers.
When you’re designing data platforms for clients, that definition needs to be concrete. Clients need a way of building, securing and operating data that works, and that everyone understands, not just a beautiful theory. This post sets out how I’ve defined and implemented data products on some recent platforms we’ve helped build.
The key point: despite being pro-data product, this approach doesn’t require a full-blown adoption of data mesh. But it delivers many of the same benefits (ownership, security, encapsulation, reusability) without mandating the organisational changes. It can work with a centralised data team, or distributed teams in domains. That makes it really useful for organisations that want to “start where they are”.
What is a data product?
At a high level, a data product is:
Owned: a team (and preferably a single named Product Owner) is accountable for it.
Valuable: it exists to serve a business purpose.
Accessible: it has a clear public contract. Things can inter-operate with it.
Governed: it carries quality checks, metadata and policies.
Composable: other products can safely build on it.
Discoverable: we have a way of finding data products, knowing what they contain, what their status is, and a clear route to requesting access.
That’s the conceptual view most people agree on. But in practice, you need something more tangible.
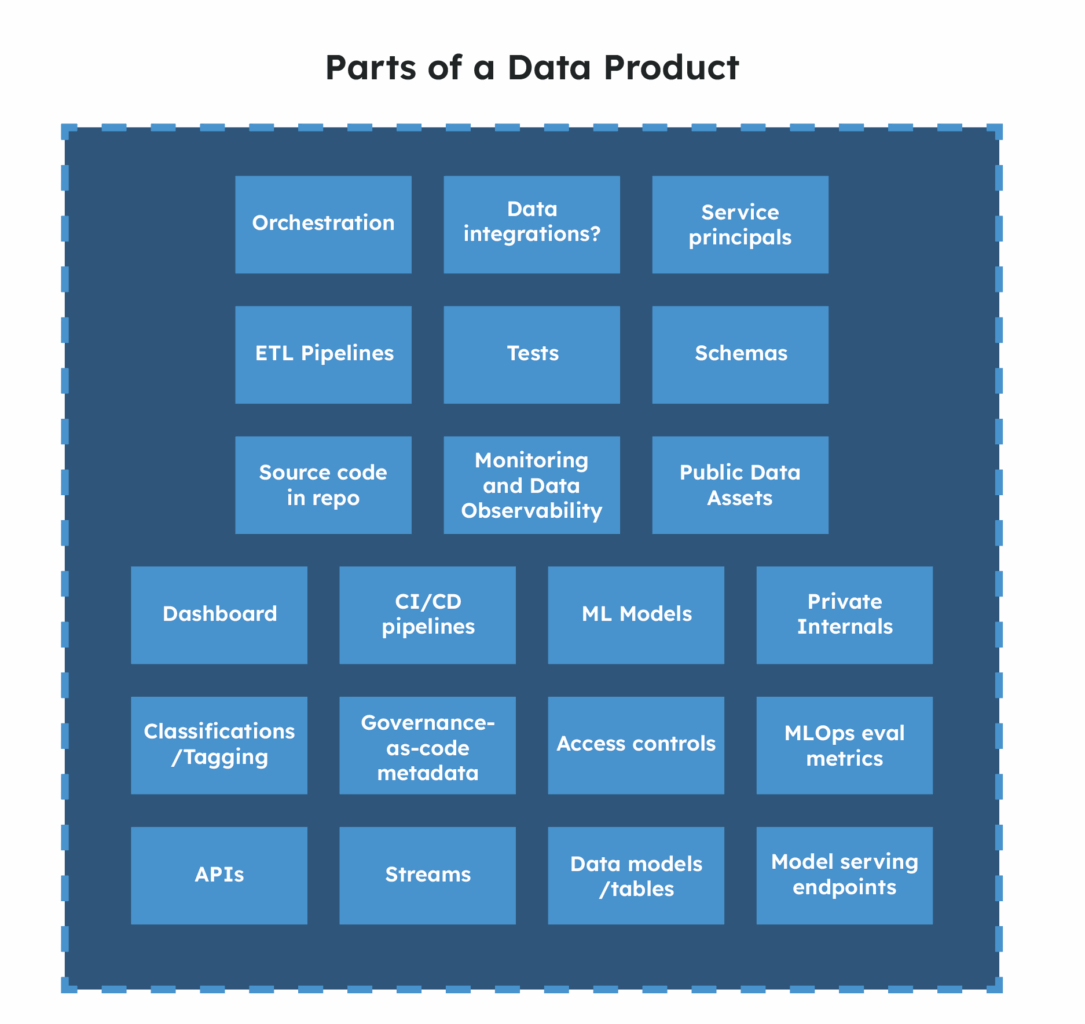
On the platforms we design and build for clients, I recommend concretely defining a data product as a bundle that includes all of the things that make up the data product:
Repos with code, pipelines and tests.
Schemas/TableGroups (in the sense of a ‘database’ or grouping of tables rather than the definition of columns and their datatypes). Each schema belongs to exactly one product.
Governance as code (certification, quality checks, metadata).
A clear public interface defining the contract of consumable data. Typically data products also contain private internals that nobody else should be depending on.
Data products can expose data via tables, APIs, dashboards, ML/LLM endpoints, feature stores or streams. But in practice data products are often exposed as “data models” (tables and views) in a data warehouse.
Access controls and service principals (non-human “users” that the pipelines run as and which own the data assets in the physical database/catalog).
Registration in the central product registry.
“Source” data products
One thing that’s helped me successfully use data product thinking in situations where teams aren’t already domain-aligned and distributed is to recognise raw/ source data products as first-class citizens.
In practice, it’s rarely economical or sensible to mandate fully-fledged data product teams which each include the expensive people (data engineers) with the skills and experience to build new data integrations using the organisation’s arcane and expensive data integration tooling. Instead, there’s often a small central pool of data engineers that manages how data makes its way into an analytics platform. Fighting this reality, and insisting that every product team needs to have the skills to integrate and operate their own data sources, inevitably leads to perceptions of slow progress and infeasible data platform cost.
Additionally, a large source system (say, the sales platform) will typically feed into many different domains—finance, stock, customer, analytics. It makes sense to allow re-use of this work between data product teams, otherwise teams create duplicate integrations. The integration work itself (CDC, replication, extraction frameworks) is often complex enough that it benefits from a single team’s expertise to do it repeatedly and quickly.
So, we define source data products that:
Own the pipelines for landing and exposing source data.
Provide a public interface that downstream data products can depend on.
Don’t try to deliver direct business value themselves—they’re integration building blocks.
These don’t have to expose anything in the “gold” / consumption layer — they’re just untransformed source system aligned data.
Note that, although I’ve used a typical layered (medallion) warehouse architecture to demonstrate in the diagram, this concept translates well even if the layers in your architecture are different.
This approach gives us clean ownership, encapsulation and reuse, without forcing every consuming team to become an integration specialist.
However, in more decentralised organisations, there’s nothing that stops teams building their own source data product when it makes sense.
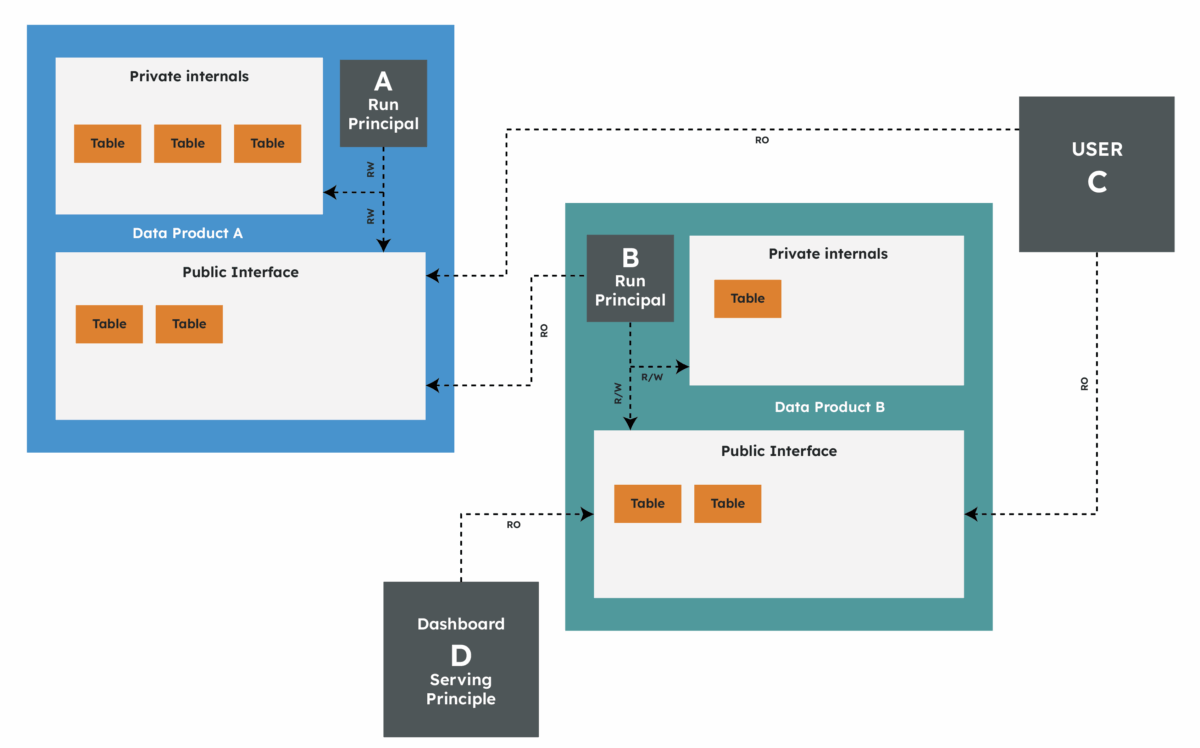
Public and private interfaces
I believe that the most important aspect of a data product is its interface (part of its contract).
The public interface is what consumers can see and use. It could be a set of tables, an API, a dashboard or a model endpoint. Access is granted to consumers only on the public interface. This can be to users or groups directly, or via serving service principals — identities that only have read access to the public contract (e.g. to serve to dashboards).
The private interface is everything else: staging areas, intermediate tables, temporary artefacts. Only the product’s run service principal (which executes pipelines) can write to these. Consumers can’t get near them.
Deployments are handled by a deploy service principal, used by CI/CD pipelines to provision infrastructure and code.
This strict separation is what provides security, stability and confidence in data products; teams can refactor their private internals without breaking downstream consumers, as long as the public contract stays consistent.
Note in the picture above that each data product has its own “run principal” which can read/write all the data product internals. Consumers of the data product (whether downstream data products, users, dashboards etc.) can only read the public tables (not the private tables).
This means never doing things like give entire groups of users blanket read access to e.g. “the warehouse presentation/gold layer”. It’s up to each data product to grant the access to users and groups via the platform’s audited, governed access control mechanisms.
Contracts might make promises to consumers about freshness, or specific attributes of data (like “this column is never null”). In more advanced platforms, data quality metrics, freshness, etc. are published and query-able in by data products in standard ways, and are an important part of implementing the “interoperable” characteristic of data products. So a dependent data product can always find out about the state of its dependencies.
Who does what: Platform vs. product teams
To make this work, you need a clear split of responsibilities. Having a platform team that builds the data platform and the common paved road “building blocks”gives shape to the data products. One can have multiple “data product teams” that build data products on the platform using these building blocks.
Enforces governance by default (governance as code baked into templates).
Ensures cost control and reporting (FinOps via tags).
Improves developer experience, templates, and tooling.
Helps establish and curate the “platform rules” and how to achieve things common to all data products, like libraries and procedures for GDPR Subject Access Rights requests, security requirements, classification and tagging for cost control.
The platform team would not normally build data products (including data integrations/source data products) — it focuses on the platform. Note: that you don’t get this magically out of the box by buying Snowflake or Databricks or AWS, etc.Without a platform team defining and providing the org-specific internal data platform building blocks and rules, every data product team will have to implement these primitives in their own inconsistent way.
The product teams focus on building and owning the products:
Implements pipelines, transformations and tests.
Maintains the public contract.
Manages consumers and declares dependencies.
Owns lifecycle, quality and documentation.
Configures the governance aspects (metadata, ownership, access control, tagging, classification etc.) as governance-as-code, using the platform templates and libraries.
In other words, they’re responsible for creating and maintaining all the things in the “Parts of a Data Product” picture above. Nobody else is going to do this!
Preferably, runs and operates the products they build (YBIYRI).
There may be a special data product team (the ingestion/hydration team) specialising in integrating new data sources quickly (i.e. which focuses on building and running “source data products”), which other product teams depend on. It usually doesn’t make sense for the “source data product” team to be the same as the platform team — they’re vastly different skills.
This division (platform vs product teams) means the platform team builds the factory, while product teams build the cars.
Why this matters
By being explicit about what a data product is — and implementing it with code, schemas, access control and governance baked in — clients in turn get:
Security and encapsulation: no accidental access to private data.
Clarity: every schema belongs to exactly one product.
Reusability: products can compose cleanly, including source data products.
Cost transparency: FinOps tagging standardised from day one.
Simplicity: onboarding a new product is self-service and repeatable.
And crucially: none of this requires a wholesale organisational shift to data mesh. You can adopt this model incrementally, product by product, while still reaping many of the benefits.
Closing thoughts
“Data product” shouldn’t be a vague buzzword. With the right platform foundations and governance-as-code, it can be a concrete, repeatable unit of work.
My experience has been that once clients see this approach in action (source data products, public/private contracts, clean ownership) they get both the practical benefits and a clearer mental model of what data products really mean in their context.
You may also like
Blog
Introducing: The Equal Experts new Data Products Playbook
Blog
Are your microservices hiding data products?
Blog
What is a Data Product Owner? Responsibilities, challenges and best practices
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.